
«`html
Усиление обучения (RL) в искусственном интеллекте
Усиление обучения (RL) — это специализированное направление искусственного интеллекта, которое обучает агентов принимать последовательные решения, вознаграждая их за выполнение желательных действий. Эта техника широко применяется в робототехнике, играх и автономных системах, позволяя машинам развивать сложные поведенческие модели через пробу и ошибку. RL позволяет агентам учиться на основе их взаимодействия с окружающей средой, корректируя свои действия на основе обратной связи для максимизации накопленных вознаграждений со временем.
Использование RL для решения задач абстрактного мышления
Одним из значительных вызовов в RL является решение задач, требующих высокого уровня абстракции и рассуждения, таких как те, которые представлены в Abstraction and Reasoning Corpus (ARC). ARC — это бенчмарк, разработанный для тестирования способностей искусственного интеллекта к абстрактному мышлению, представляющий уникальный набор трудностей. Он включает в себя обширное пространство действий, в котором агенты должны выполнять различные манипуляции на уровне пикселей, что затрудняет разработку оптимальных стратегий. Кроме того, определение успеха в ARC является нетривиальным, требуя точного воспроизведения сложных сеток, а не достижения физического местоположения или конечной точки. Эта сложность требует глубокого понимания правил задачи и точного применения, усложняя проектирование системы вознаграждения.
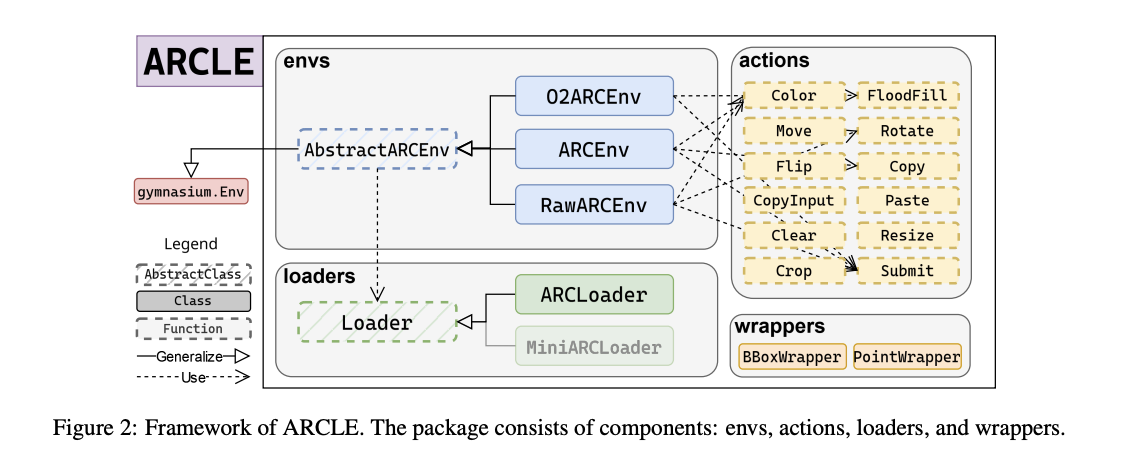
ARCLE: среда обучения для решения задач ARC
Исследователи из Gwangju Institute of Science and Technology и Korea University представили ARCLE (ARC Learning Environment) для решения этих вызовов. ARCLE — это специализированная среда усиления обучения, разработанная для облегчения исследований в области ARC. Она была разработана с использованием фреймворка Gymnasium, предоставляя структурированную платформу, где агенты усиления обучения могут взаимодействовать с задачами ARC. Эта среда позволяет исследователям обучать агентов с использованием техник усиления обучения, специально разработанных для сложных задач, представленных в ARC.
ARCLE включает несколько ключевых компонентов: среды, загрузчики, действия и обертки. Компонент среды включает базовый класс и его производные, которые определяют структуру пространств действий и состояний, а также методы, определяемые пользователем. Компонент загрузчиков предоставляет набор данных ARC для сред ARCLE, определяя, как наборы данных должны быть разобраны и выборочно отобраны. Действия в ARCLE определены для выполнения различных манипуляций с сеткой, таких как окрашивание, перемещение и вращение пикселей. Обертки модифицируют пространство действий или состояний среды, улучшая процесс обучения путем предоставления дополнительных функций.
Результаты исследования
Исследование показало, что агенты усиления обучения, обученные в ARCLE с использованием метода оптимизации ближайшей политики (PPO), могли успешно учиться отдельным задачам. Внедрение нефакториальных политик и вспомогательных потерь значительно улучшило производительность. Эти улучшения эффективно смягчили проблемы, связанные с навигацией в обширном пространстве действий и достижением труднодоступных целей задач ARC. Исследование подчеркнуло, что агенты, оснащенные этими передовыми техниками, показали заметные улучшения в производительности задач. Например, агенты, основанные на PPO, достигли высокой степени успешности в решении задач ARC при обучении с вспомогательными функциями потерь, предсказывающими предыдущие вознаграждения, текущие вознаграждения и следующие состояния. Этот многофакторный подход помог агентам учиться более эффективно, предоставляя дополнительное руководство во время обучения.
Агенты, обученные методом оптимизации ближайшей политики (PPO) и улучшенные нефакториальными политиками и вспомогательными потерями, достигли успешности более 95% в случайных сценариях. Внедрение вспомогательных потерь, включающих предсказание предыдущих вознаграждений, текущих вознаграждений и следующих состояний, привело к заметному увеличению накопленных вознаграждений и успешности. Метрики производительности показали, что агенты, обученные с использованием этих методов, превзошли тех, у которых не было вспомогательных потерь, достигнув на 20-30% более высокой успешности в сложных задачах ARC.
Заключение
Исследование подчеркивает потенциал ARCLE в развитии стратегий усиления обучения для задач абстрактного мышления. Создание специализированной среды усиления обучения, адаптированной под ARC, открывает путь для исследования передовых методов усиления обучения, таких как мета-усиление обучения, генеративные модели и модельное усиление обучения. Эти методологии обещают дальнейшее улучшение способностей ИИ к рассуждению и абстракции, способствуя прогрессу в этой области. Интеграция ARCLE в исследования усиления обучения решает текущие вызовы ARC и способствует более общему стремлению развивать ИИ, который может эффективно учиться, рассуждать и абстрагироваться. Это исследование приглашает сообщество усиления обучения взаимодействовать с ARCLE и исследовать его потенциал для продвижения исследований в области ИИ.
Проверьте статью. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Twitter и присоединиться к нашей группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit.
Найдите предстоящие вебинары по ИИ здесь.
Arcee AI выпустила DistillKit: открытый инструмент для модельного дистилляции, облегчающий создание эффективных малых языковых моделей высокой производительности.