
«`html
Meta-Rewarding LLMs: новый метод улучшения способности к следованию инструкциям
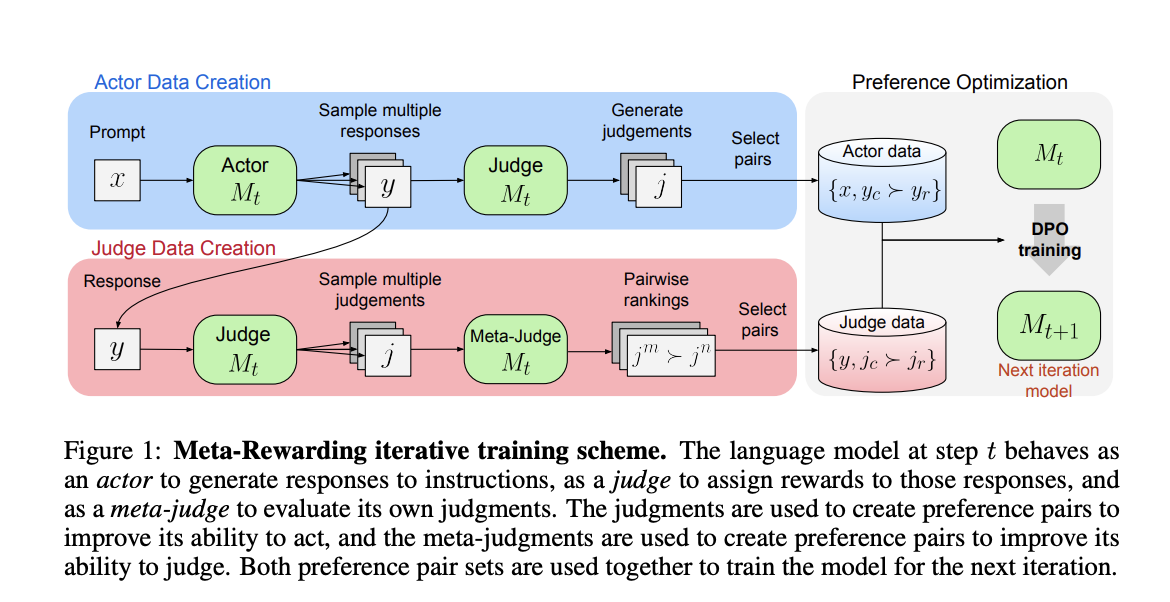
Исследователи разработали Meta-Rewarding, новый метод улучшения способности к следованию инструкциям LLMs. Этот метод использует мета-судью для оценки и выбора суждений для оптимизации предпочтений, что позволяет преодолеть ограничения предыдущих Self-Rewarding методов путем прямого обучения судьи. Более того, он включает новую технику контроля длины для решения проблем длинных ответов в обучении AI. Способности модели к суждению более тесно соответствуют суждениям человеческих судей и передовым AI-судьям, таким как GPT-4. Однако исследователи отмечают ограничение в своей 5-балльной системе суждения, которая иногда приводит к ничьим из-за минимальных различий в качестве ответов.
Результаты и значимость
Значение Meta-Rewarding
Meta-Rewarding значительно улучшает способности LLMs к следованию инструкциям и ответу на сложные вопросы.
Применение в бизнесе
Рассмотрите возможности применения AI в своем бизнесе, начиная с небольшого проекта и постепенно масштабируя автоматизацию на основе данных и опыта.
Связь с нами
Если вам нужны советы по внедрению ИИ, пишите нам здесь. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
AI Sales Bot
Попробуйте AI Sales Bot, который поможет снизить нагрузку на первую линию поддержки и генерировать контент для отдела продаж.
AI Lab itinai.ru
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab, будущее уже здесь!
«`



















