
«`html
AI в медицинском изображении: балансировка производительности и справедливости среди населения
Поскольку модели искусственного интеллекта все более интегрируются в клиническую практику, оценка их производительности и потенциальных предвзятостей к различным демографическим группам крайне важна. Глубокое обучение достигло замечательных успехов в задачах медицинского изображения, но исследования показывают, что эти модели часто наследуют предвзятости от данных, что приводит к неравенству в производительности среди различных подгрупп. Например, классификаторы рентгеновских снимков груди могут недооценивать состояния у чернокожих пациентов, что потенциально замедляет необходимый уход. Понимание и устранение этих предвзятостей является ключевым для этичного использования этих моделей.
Оценка производительности и справедливости
Недавние исследования выявили неожиданную способность глубоких моделей точнее предсказывать демографическую информацию, такую как раса, пол и возраст, из медицинских изображений, чем радиологи. Это вызывает опасения, что модели прогнозирования заболеваний могут использовать демографические особенности как обманчивые ярлыки — корреляции в данных, которые не имеют клинического значения, но могут влиять на прогнозы.
Исследование и выводы
Недавно была опубликована статья в известном журнале Nature Medicine. В ней исследовалось, как демографические данные могут быть использованы в качестве ярлыков моделями классификации заболеваний в медицинском ИИ, что потенциально приводит к предвзятым результатам. В ходе исследования авторы пытались ответить на несколько важных вопросов: оценка влияния демографических особенностей на результаты прогнозирования алгоритмов, эффективность существующих техник устранения этих предвзятостей и создание справедливых моделей. Кроме того, исследование рассматривало поведение этих моделей в сценариях сдвига реальных данных и определяло критерии и методы, обеспечивающие справедливость.
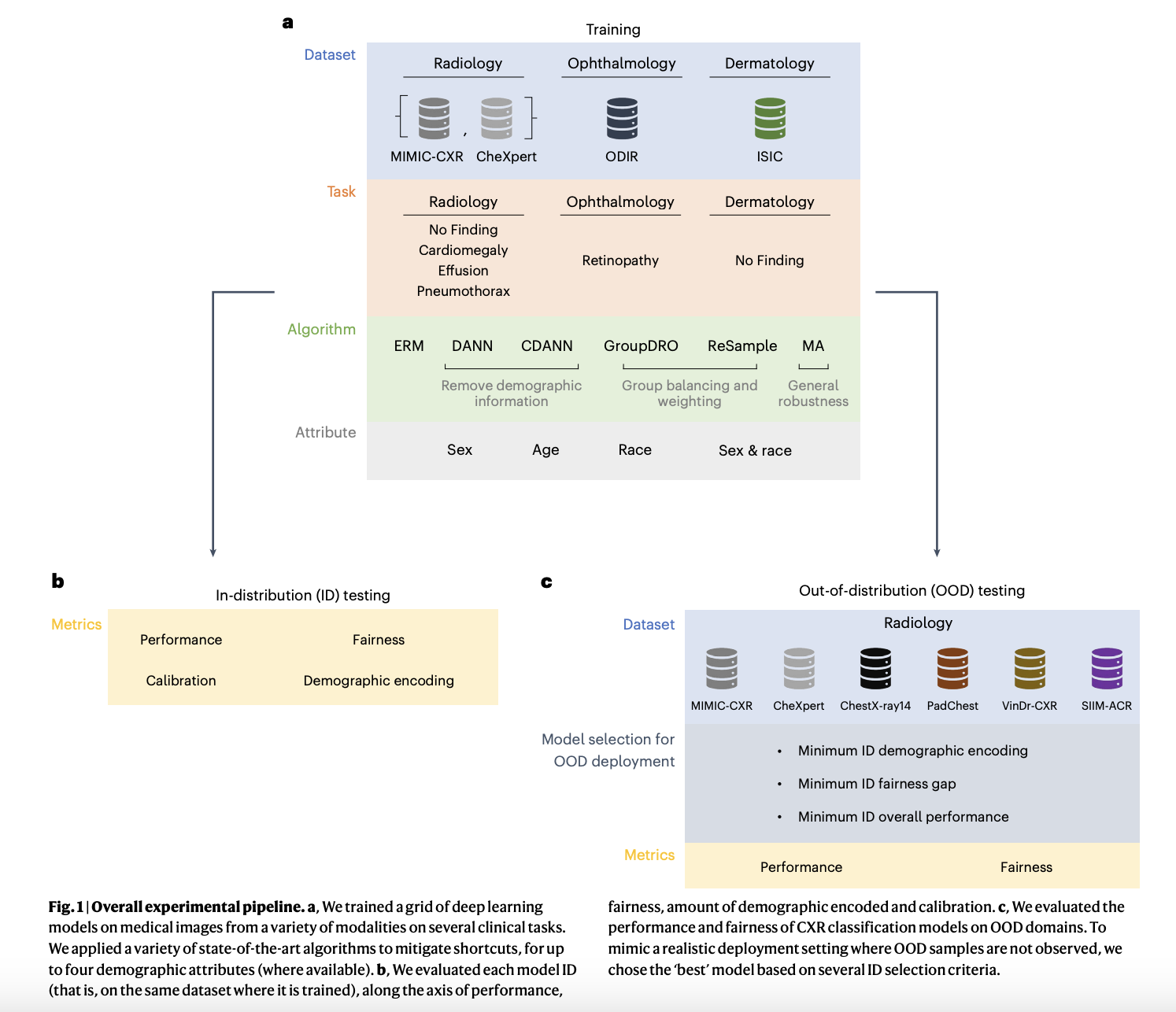
Команда исследователей провела эксперименты для оценки производительности и справедливости медицинских ИИ моделей среди различных демографических групп и модальностей. Они сосредоточились на бинарных классификационных задачах, связанных с рентгеновскими снимками груди (CXR), включая категории, такие как «Отсутствие находок», «Эффузия», «Пневмоторакс» и «Кардиомегалия», используя наборы данных, такие как MIMIC-CXR и CheXpert. Задачи дерматологии использовали набор данных ISIC для классификации «Отсутствие находок», а задачи офтальмологии оценивались с использованием набора данных ODIR, специально нацеленного на «Ретинопатию». Метриками для оценки справедливости были ложноположительные и ложноотрицательные рейты, с акцентом на равные шансы для измерения неравенства производительности среди демографических подгрупп. Исследование также исследовало, как кодирование демографических данных влияет на справедливость модели и анализировало сдвиги распределения между настройками внутри и вне диапазона.
Выводы исследования показали, что неравенства в справедливости сохранялись в различных настройках, и улучшения в справедливости внутри диапазона не всегда переводились в лучшую справедливость вне диапазона. Исследование подчеркнуло критическую необходимость надежных техник устранения предвзятостей и комплексной оценки для обеспечения справедливого развертывания ИИ.
Заключение и рекомендации
В заключение, критически важно столкнуться и понять предвзятости, которые могут приобрести модели ИИ из обучающих данных, поскольку они все более интегрируются в клиническую практику. Исследование подчеркивает, насколько сложно сохранить производительность, улучшая справедливость, особенно при обработке изменений распределения между обучением и реальными настройками. Для обеспечения доверия и справедливости ИИ-систем необходимо использовать эффективные стратегии устранения предвзятостей, непрерывное мониторинг и тщательный выбор моделей.
Кроме того, сложность демографических характеристик в предсказании заболеваний подчеркивает необходимость сложного подхода к справедливости, где разрабатываются модели, которые не только технически хороши, но и морально правильны и настроены на реальные клинические настройки.
Подробнее о статье можно узнать по ссылке. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и присоединиться к нашему Телеграм-каналу и группе LinkedIn. Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Находите предстоящие вебинары по ИИ здесь.
Arcee AI выпустила DistillKit: открытый инструмент для моделирования моделей, преобразующий процесс дистилляции моделей языка в эффективные, высокопроизводительные малые языковые модели.
«`



















