
«`html
Основные вызовы в исследованиях в области искусственного интеллекта (ИИ)
Один из основных вызовов в исследованиях в области искусственного интеллекта (ИИ) – это проверка правильности выводов языковых моделей (LMs), особенно в контекстах, требующих сложного рассуждения. Поскольку LMs все чаще используются для сложных запросов, требующих нескольких логических шагов, предметной экспертизы и количественного анализа, обеспечение точности и надежности этих моделей является ключевым. Это особенно важно в областях, таких как финансы, право и биомедицина, где неправильная информация может привести к серьезным негативным последствиям.
Текущие методы проверки выводов LM включают факт-чекинг и техники естественного языка (NLI)
Текущие методы проверки выводов LM включают факт-чекинг и техники естественного языка (NLI). Однако эти методы обычно полагаются на наборы данных, разработанные для конкретных задач рассуждения, таких как вопросно-ответный анализ (QA) или финансовый анализ. Однако эти наборы данных не предназначены для проверки утверждений, и существующие методы имеют ограничения, такие как высокая вычислительная сложность, зависимость от больших объемов размеченных данных и недостаточная производительность при выполнении задач, требующих длительного рассуждения или многократных выводов. Высокий уровень шума меток и специфичность многих наборов данных также затрудняют обобщение и применимость этих методов в более широких контекстах.
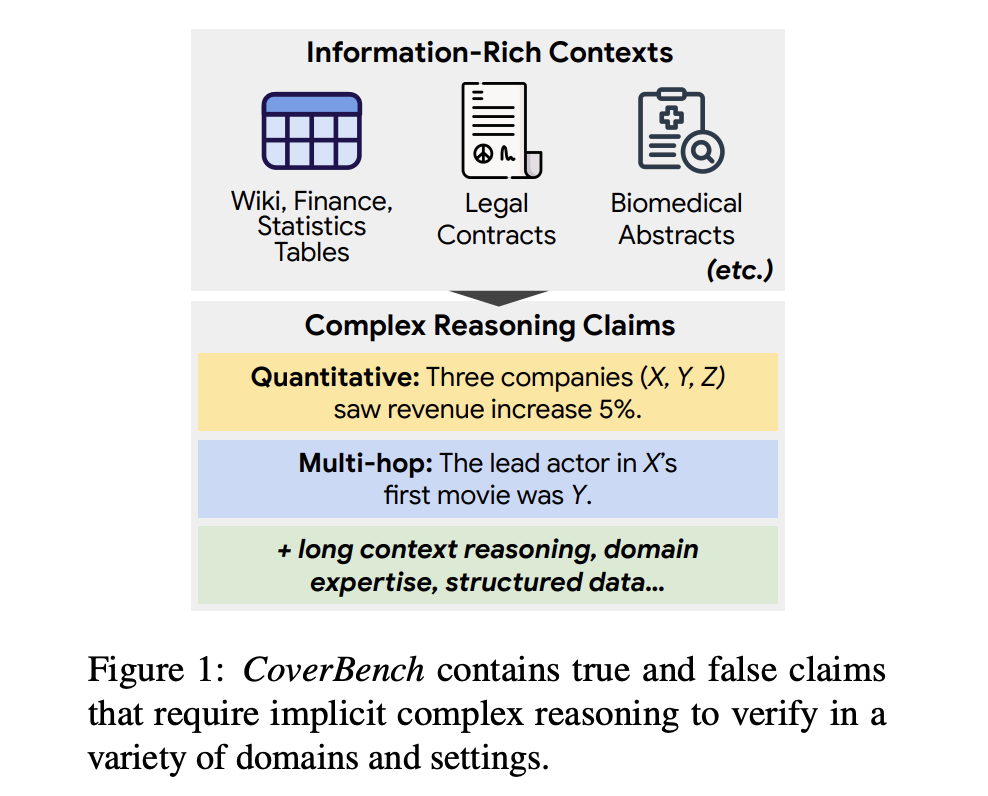
Предложенный бенчмарк CoverBench
Команда исследователей из Google и Тель-Авивского университета предложила CoverBench — бенчмарк, специально разработанный для оценки сложной проверки утверждений в различных областях и типах рассуждений. CoverBench решает ограничения существующих методов, предоставляя унифицированный формат и разнообразный набор из 733 примеров, требующих сложного рассуждения, включая понимание длинного контекста, многократные выводы и количественный анализ. Бенчмарк включает верные и ложные утверждения, проверенные на качество, обеспечивая низкий уровень шума меток. Этот новый подход позволяет провести всестороннюю оценку возможностей проверки LM, выявляя области, требующие улучшения, и устанавливая более высокий стандарт для задач проверки утверждений.
Набор данных CoverBench
Набор данных CoverBench включает наборы данных из девяти различных источников, включая FinQA, QRData, TabFact, MultiHiertt, HybridQA, ContractNLI, PubMedQA, TACT и Feverous. Эти наборы данных охватывают широкий спектр областей, таких как финансы, Википедия, биомедицина, право и статистика. Бенчмарк включает преобразование различных задач QA в декларативные утверждения, стандартизацию представлений таблиц и генерацию отрицательных примеров с использованием моделей-затравок, таких как GPT-4. Итоговый набор данных содержит длинные входные контексты, в среднем состоящие из 3 500 токенов, что представляет вызов для способностей текущих моделей. Наборы данных были вручную проверены на правильность и сложность утверждений.
Оценка CoverBench
Оценка CoverBench показывает, что текущие конкурентоспособные LM значительно затрудняются с представленными задачами, часто достигая производительности близкой к случайной базовой линии. Самые производительные модели, такие как Gemini 1.5 Pro, достигли значения Macro-F1 в 62.1, что указывает на значительное пространство для улучшения. В отличие от этого, модели, такие как Gemma-1.1-7b-it, показали значительно более низкую производительность, подчеркивая сложность бенчмарка. Эти результаты подчеркивают вызовы, с которыми сталкиваются LM в сложной проверке утверждений, и значительный потенциал для прогресса в этой области.
Заключение
CoverBench значительно способствует исследованиям в области ИИ, предоставляя сложный бенчмарк для проверки сложных утверждений. Он преодолевает ограничения существующих наборов данных, предлагая разнообразный набор задач, требующих многократных выводов, понимания длинного контекста и количественного анализа. Тщательная оценка бенчмарка показывает, что текущие LM имеют значительное пространство для улучшения в этих областях. Таким образом, CoverBench устанавливает новый стандарт для проверки утверждений, выдвигая пределы того, что могут достичь LM в сложных задачах рассуждения.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 48-тысячному сообществу в ML SubReddit.
Найдите предстоящие вебинары по ИИ здесь.
Arcee AI выпустила DistillKit: открытый инструмент для преобразования моделей для создания эффективных малых языковых моделей
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте DistillKit: An Open Source, Easy-to-Use Tool Transforming Model Distillation for Creating Efficient, High-Performance Small Language Models.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`




















