
«`html
Аудио в мире искусственного интеллекта
Аудио, как средство передачи информации, имеет огромный потенциал для передачи сложной информации, что делает его важным для разработки систем, способных точно интерпретировать и реагировать на аудиовходы. Цель этой области — создание моделей, способных понимать широкий спектр звуков, от устной речи до окружающего шума, и использовать это понимание для облегчения более естественного взаимодействия между людьми и машинами.
Основные вызовы и решения
Одним из основных вызовов в этой области является разработка систем, способных обрабатывать разнообразные аудиосигналы в реальных сценариях. Традиционные модели часто не справляются с распознаванием и реагированием на сложные аудиовходы, такие как перекрывающиеся звуки, многоголосые среды и смешанные аудиоформаты. Проблема усугубляется, когда от этих систем ожидают выполнения задач без обширной настройки под конкретную задачу. Это ограничение побудило исследователей искать новые методологии, способные лучше подготовить модели к работе с непредсказуемостью и сложностью реальных аудиоданных, тем самым улучшая их способность следовать инструкциям и точно реагировать в различных контекстах.
Qwen2-Audio: новаторская модель для работы с аудиосигналами
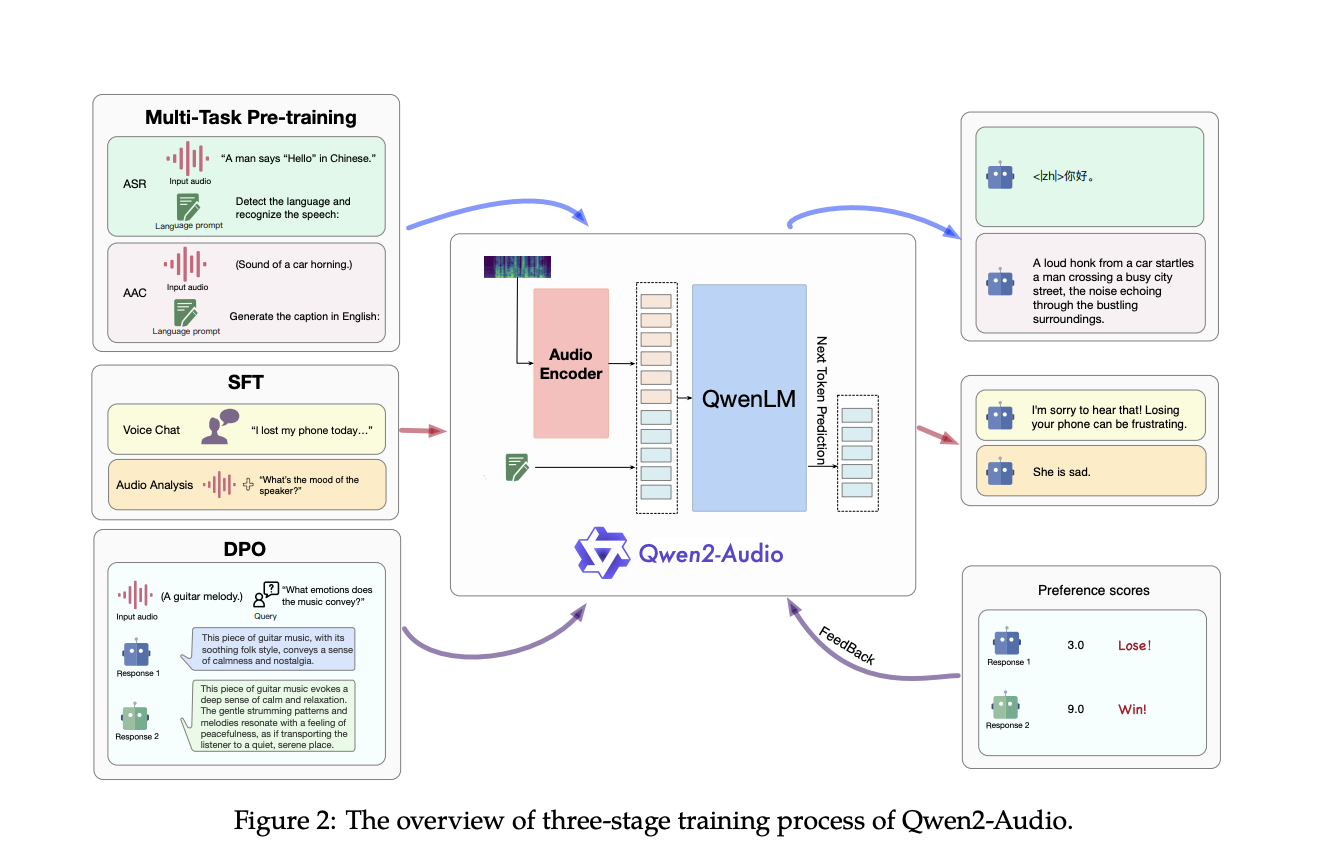
Исследователи из команды Qwen в Alibaba Group представили Qwen2-Audio — передовую масштабную аудио-языковую модель, разработанную для обработки и реагирования на сложные аудиосигналы без необходимости обширной настройки под конкретную задачу. Qwen2-Audio отличается упрощением процесса предварительного обучения с использованием естественных языковых подсказок вместо иерархических тегов, что значительно расширяет объем данных модели и улучшает ее способность следовать инструкциям. Модель работает в двух основных режимах: Voice Chat и Audio Analysis, что позволяет ей участвовать в свободном голосовом взаимодействии или анализировать различные типы аудиоданных в соответствии с инструкциями пользователя. Двухрежимная функциональность обеспечивает плавный переход между задачами без отдельных системных подсказок.
Архитектура и производительность
Архитектура Qwen2-Audio интегрирует сложный аудиоэнкодер, инициализированный на основе модели Whisper-large-v3, с моделью большого языка Qwen-7B в качестве основного компонента. Процесс обучения включает преобразование сырых аудио-волн в 128-канальные мел-спектрограммы, которые затем обрабатываются с использованием окна размером 25 мс и шага 10 мс. Полученные данные проходят через слой пулинга, уменьшая длину аудиопредставления и обеспечивая, что каждый кадр соответствует приблизительно 40 мс исходного аудиосигнала. С 8,2 миллиардами параметров Qwen2-Audio способна обрабатывать различные аудиовходы, от простой речи до сложных многомодальных аудиосред.
Оценки производительности показывают, что Qwen2-Audio превосходит предыдущие модели в различных бенчмарках, превзойдя их в задачах, таких как автоматическое распознавание речи (ASR), перевод речи в текст (S2TT) и распознавание эмоций в речи (SER). Модель достигла коэффициента ошибок слов (WER) 1,6% на тестовом наборе Librispeech test-clean и 3,6% на тестовом наборе test-other, значительно улучшив показатели по сравнению с предыдущими моделями, такими как Whisper-large-v3. В задаче перевода речи в текст Qwen2-Audio превзошла базовые показатели в семи направлениях перевода, достигнув BLEU-оценки 45,2 в направлении en-de и 24,4 в направлении zh-en. Кроме того, в задаче классификации вокальных звуков (VSC) Qwen2-Audio достигла точности 93,92%, демонстрируя свою надежную производительность в различных аудиозадачах.
Заключение
Qwen2-Audio, упрощая процесс предварительного обучения, расширяя объем данных и интегрируя передовую архитектуру, модель преодолевает ограничения своих предшественников и устанавливает новый стандарт для систем взаимодействия с аудио. Ее способность хорошо справляться с различными задачами без необходимости обширной настройки под конкретную задачу подчеркивает ее потенциал революционизировать способы обработки и взаимодействия машин с аудиосигналами.
Подробнее ознакомьтесь с статьей, моделью и демонстрацией. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш рассылка.
Не забудьте присоединиться к нашему Reddit-сообществу.
Найдите предстоящие вебинары по ИИ здесь.
DistillKit: открытый инструмент для создания эффективных малых языковых моделей
Arcee AI выпустила DistillKit: открытый и простой в использовании инструмент для моделирования для создания эффективных высокопроизводительных малых языковых моделей.
«`





















