
«`html
Кросс-языковое клонирование кода: важность, методы и результаты
Кросс-языковое клонирование кода становится все более важной и сложной задачей в современной разработке программного обеспечения из-за возрастающей сложности проектов, в которых typically используются множество языков программирования.
Недавние успехи искусственного интеллекта и машинного обучения привели к значительному прогрессу в решении многих задач вычислений, особенно с появлением больших языковых моделей (LLM). Благодаря своим уникальным навыкам обработки естественного языка, LLM привлекает внимание своим потенциальным использованием в задачах, связанных с кодом, таких как обнаружение клонов кода.
Исследование в области кросс-языкового клонирования кода
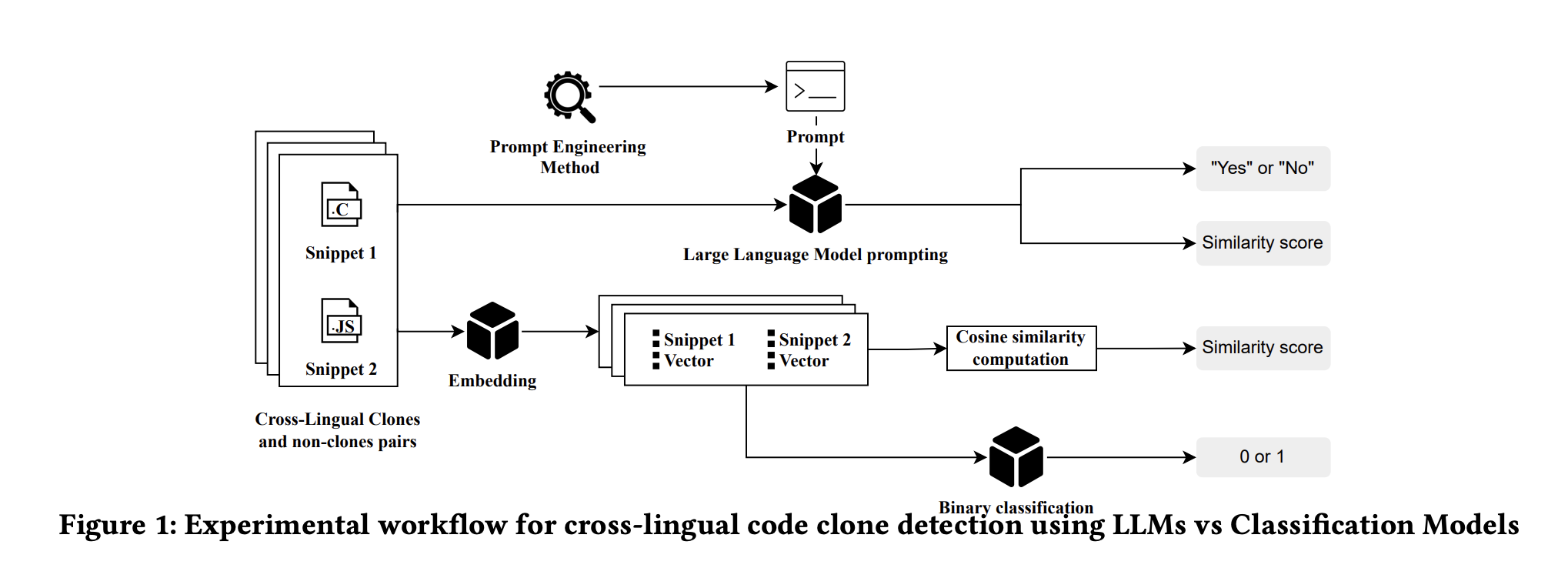
Команда исследователей из Университета Люксембурга пересмотрела проблему кросс-языкового клонирования кода и изучила эффективность как LLM, так и предварительно обученных моделей векторных вложений в этой области.
В рамках исследования были оценены способности четырех различных LLM в сочетании с восемью уникальными подсказками, предназначенными для поддержки обнаружения кросс-языковых клонов кода. Оценилась также полезность предварительно обученной модели вложений, производящей векторные представления фрагментов кода.
Результаты исследования показали, что модели вложений, представляющие фрагменты кода из различных языков программирования в одном векторном пространстве, предлагают более надежную основу для идентификации кросс-языковых клонов кода.
Выводы исследования
Исследование показало, что LLM могут достигать высоких показателей, особенно при обработке простых примеров кода, но могут испытывать трудности с более сложными задачами программирования. В то время как модели вложений способны превзойти все оцененные LLM в области кросс-языкового клонирования кода, обеспечивая современные результаты на различных наборах данных.
Практическое применение исследования
Эти результаты позволяют определить, что модели вложений являются более эффективным методом для обнаружения кросс-языковых клонов кода, поскольку они предоставляют постоянные и языково-нейтральные представления кода.
Заключение
Таким образом, результаты исследования свидетельствуют о том, что, несмотря на высокую способность LLM, особенно в отношении простых примеров кода, они могут быть менее эффективным методом для обнаружения кросс-языковых клонов кода, особенно в сложных ситуациях. В отличие от этого, модели вложений более подходят для достижения передовых результатов в этой области.
Подробнее о исследовании можно узнать в этой статье.
Все авторские права на это исследование принадлежат его авторам. Также не забудьте подписаться на наш Telegram-канал и группу в LinkedIn. Если вам понравилась наша работа, вам понравится и наш рассылка.
Не забудьте присоединиться к нашему 48-тысячному сообществу ML SubReddit.
Исследователи из FPT Software AI Center представляют XMainframe: современную большую языковую модель (LLM), специализированную для модернизации мейнфрейма, чтобы решить проблему устаревшего легаси-кода на сумму $100 млрд.
Ссылка на оригинальную статью.
«`

















