
«`html
Решение проблемы повышенных затрат и задержек в обработке AI-моделей
По мере усовершенствования AI-моделей требуется более подробный контекст, что приводит к увеличению затрат и задержек. Это особенно актуально для таких сфер, как разговорные агенты, помощники по кодированию и обработка больших документов. Исследователи решают проблему эффективного управления и использования больших контекстов в AI-моделях, особенно в сценариях, требующих частого повторного использования похожей контекстной информации.
Решение: кэширование запросов
Anthropic API представляет новую функцию «кэширование запросов», доступную для определенных моделей Claude. Это позволяет разработчикам сохранять часто используемые контексты запросов и повторно использовать их. Это значительно снижает затраты и задержки, связанные с повторной отправкой больших запросов.
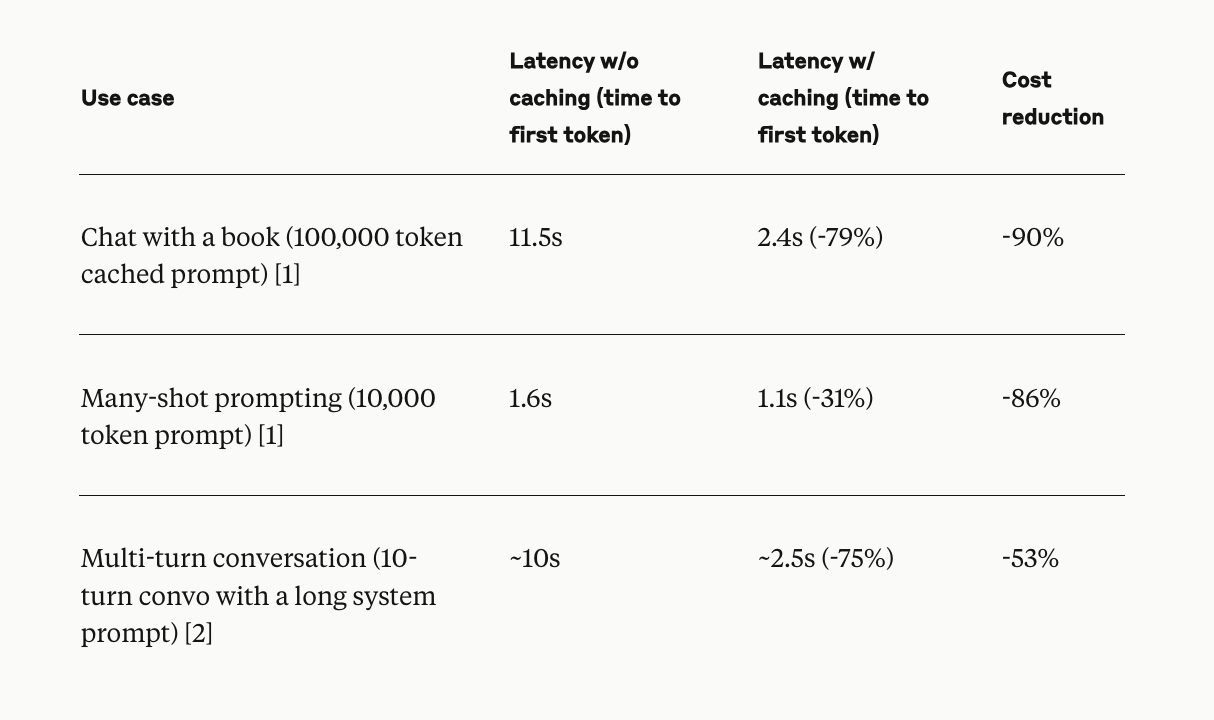
Практическое применение
Кэширование запросов особенно эффективно в сценариях, таких как длительные разговоры, помощь в кодировании, обработка больших документов и поиск информации, где требуется поддержание большого количества контекстной информации. Кэшированный контент может включать подробные инструкции, краткое описание кодовой базы, документы большого объема и другую контекстную информацию.
Ценовая модель и преимущества
Модель ценообразования для кэширования запросов структурирована с учетом экономической эффективности: запись в кэш увеличивает стоимость токена ввода на 25%, а чтение из кэша стоит всего 10% от базовой стоимости токена ввода. Ранние пользователи отметили значительное улучшение как экономической эффективности, так и скорости обработки.
Заключение
Кэширование запросов решает проблему увеличения затрат и задержек в AI-моделях, требующих подробных контекстов. Эта функция повышает эффективность различных приложений, от разговорных агентов до обработки больших документов. Реализация кэширования запросов на Anthropic API предлагает многообещающее решение для вызовов, связанных с большими контекстами запросов, что делает его значительным прорывом в области LLM.
«`




















