
«`html
Neural Magic Releases LLM Compressor: A Novel Library to Compress LLMs for Faster Inference with vLLM
Neural Magic выпустила LLM Compressor, передовой инструмент для оптимизации больших языковых моделей, который обеспечивает значительно более быструю вывод через более продвинутое сжатие модели. Этот инструмент является важным строительным блоком в стремлении Neural Magic сделать высокопроизводительные решения с открытым исходным кодом доступными для сообщества глубокого обучения, особенно в рамках vLLM.
Практические решения и ценность
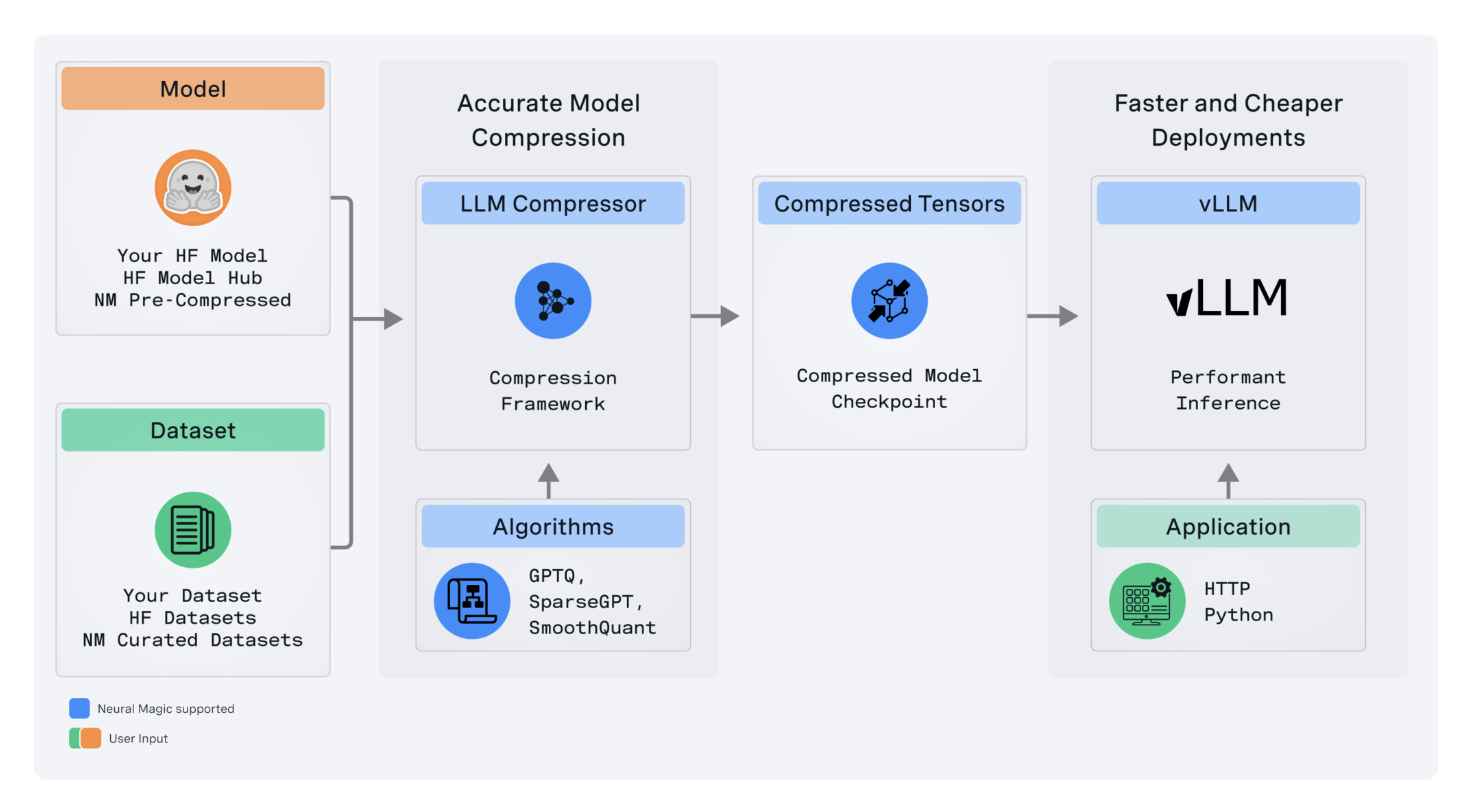
LLM Compressor устраняет сложности, возникающие из фрагментированного ландшафта инструментов сжатия моделей, где пользователи должны были разрабатывать несколько уникальных библиотек, подобных AutoGPTQ, AutoAWQ и AutoFP8, чтобы применять определенные алгоритмы квантования и сжатия. LLM Compressor объединяет эти фрагментированные инструменты в одну библиотеку для легкого применения передовых алгоритмов сжатия, таких как GPTQ, SmoothQuant и SparseGPT. Эти алгоритмы реализованы для создания сжатых моделей, обеспечивающих снижение задержки вывода и поддержание высокого уровня точности, что критично для развертывания модели в производственных средах.
Вторым ключевым техническим преимуществом, которое приносит LLM Compressor, является поддержка квантования активации и веса. В частности, квантование активации важно для обеспечения использования тензорных ядер INT8 и FP8. Это важная возможность ускорения вычислительных нагрузок, где вычислительное узкое место уменьшается за счет использования арифметических блоков меньшей точности. Это означает, что, квантование активаций и весов позволяет LLM Compressor увеличить производительность для задач вывода вдвое, особенно при высоких нагрузках на сервер. Это подтверждается большими моделями, такими как Llama 3.1 70B, что демонстрирует, что при использовании LLM Compressor модель достигает производительности задержки, очень близкой к неквантованной версии, работающей на четырех GPU только с двумя.
Помимо квантования активации, LLM Compressor поддерживает передовую структурированную разреженность, 2:4, обрезку весов с помощью SparseGPT. Эта обрезка весов селективно удаляет избыточные параметры для снижения потери точности за счет сокращения размера модели на 50%. Кроме ускорения вывода, это сочетание квантования и обрезки весов минимизирует объем памяти и позволяет развертывать модели на аппаратных средствах с ограниченными ресурсами для LLM.
LLM Compressor разработан для легкой интеграции в любую экосистему с открытым исходным кодом, в частности, в модульную систему Hugging Face, путем безболезненной загрузки и запуска сжатых моделей в рамках vLLM. Кроме того, инструмент расширяет возможности, поддерживая различные схемы квантования, включая тонкую настройку квантования, такую как на уровне тензора или канала для весов и на уровне тензора или токена для активации. Эта гибкость в стратегии квантования позволит очень точно настраивать требования к производительности и точности для различных моделей и сценариев развертывания.
Технически LLM Compressor разработан для работы с различными архитектурами моделей с возможностью расширения. У него агрессивный план развития, включая расширение поддержки до моделей MoE, моделей видео-языка и аппаратных платформ, не связанных с NVIDIA. Другие области в плане развития, ожидающие разработки, включают передовые техники квантования, такие как AWQ, и инструменты для создания неоднородных схем квантования; они должны дополнительно увеличить эффективность модели.
В заключение, LLM Compressor становится важным инструментом как для исследователей, так и для практиков в оптимизации LLM для развертывания в производство. Он с открытым исходным кодом и имеет передовые функции, что упрощает сжатие моделей и обеспечивает значительное улучшение производительности без ущерба для целостности моделей. LLM Compressor и аналогичные инструменты сыграют очень важную роль в ближайшем будущем, когда ИИ продолжит масштабирование в эффективном развертывании больших моделей на различных аппаратных средах, что сделает их более доступными для применения во многих других областях.
Проверьте страницу GitHub и детали. Вся заслуга за этот проект принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашей группе LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 48k+ ML SubReddit
Найдите предстоящие вебинары по ИИ здесь
Arcee AI представляет Arcee Swarm: Революционное сочетание агентов MoA Architecture, вдохновленное кооперативным интеллектом, обнаруженным в самой природе
Статья опубликована на портале MarkTechPost.
«`


















