
«`html
Увеличение выходной ёмкости моделей языкового моделирования: роль AgentWrite и набор данных LongWriter-6k
Долгие контекстные языковые модели (LLM) требуют достаточного окна контекста для выполнения сложных задач, аналогично рабочей памяти человека. Исследования сосредотачиваются на расширении длины контекста, что позволяет лучше обрабатывать более длинный контент. Методы нулевой настройки и тонкая настройка увеличивают объём памяти. Несмотря на прогресс в обработке ввода (до 100 000 слов), существующие LLM имеют ограничение в 2 000 слов на вывод, что указывает на пробел в возможностях. Обучение выравнивания помогает LLM приоритизировать инструкции и соблюдать ограничения по длине.
Расширение возможностей
Методы нулевой настройки и тонкая настройка увеличивают объём памяти. Несмотря на прогресс в обработке ввода (до 100 000 слов), существующие LLM имеют ограничение в 2 000 слов на вывод, что указывает на пробел в возможностях. Обучение выравнивания помогает LLM приоритизировать инструкции и соблюдать ограничения по длине.
Решение
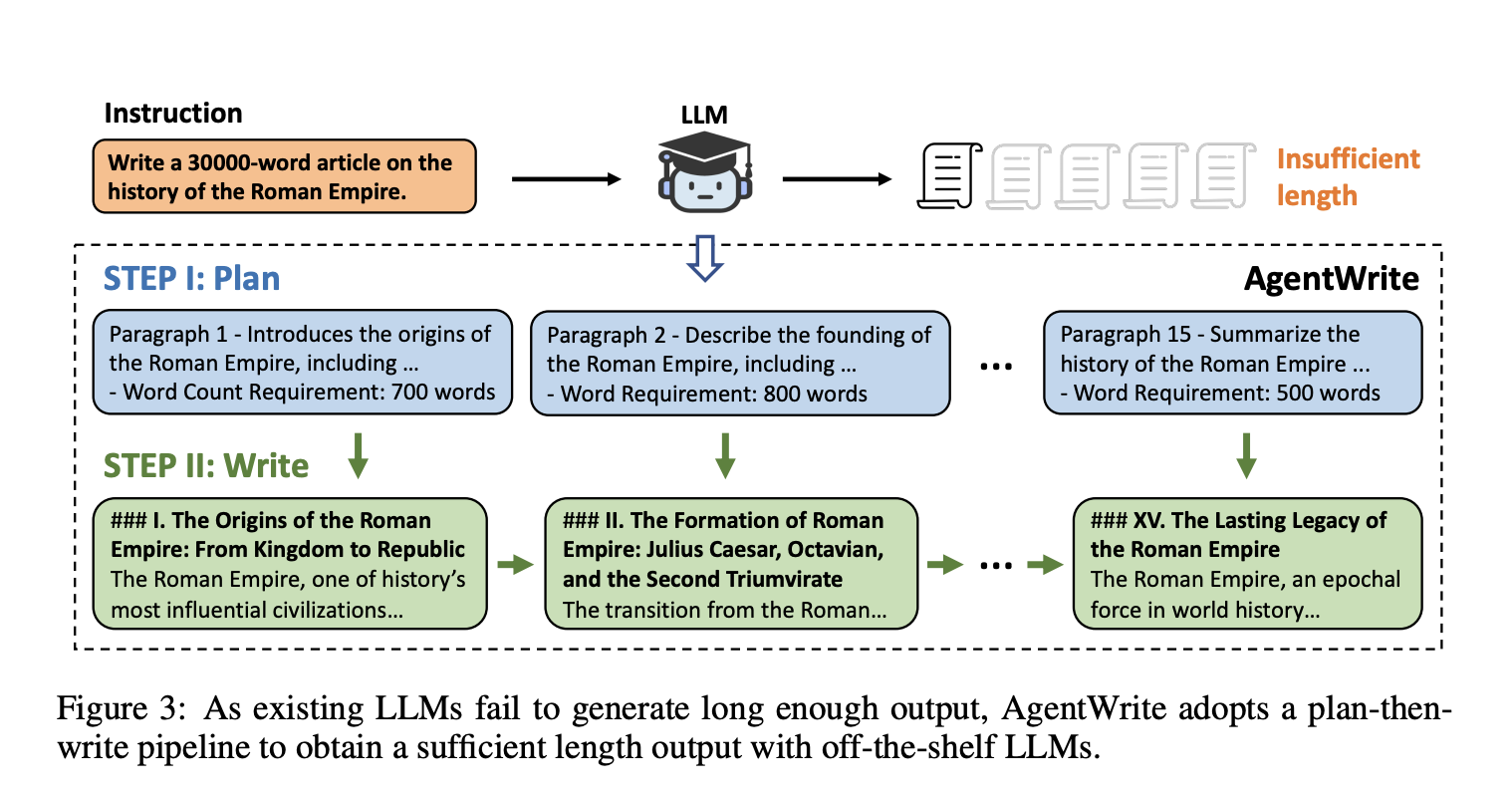
Для решения этой проблемы был создан агентный пайплайн AgentWrite, который разбивает задачи ультрадлинного поколения на подзадачи, позволяя использовать стандартные LLM для создания согласованных выводов объемом более 20 000 слов. Авторы разработали набор данных LongWriter-6k с 6 000 точками данных для надзорной тонкой настройки с длиной вывода от 2 000 до 32 000 слов. Их модель с 9 миллиардами параметров, улучшенная через DPO, достигла лучших показателей на новом бенчмарке для возможностей ультрадлинного поколения, показывая потенциал существующих LLM при соответствующих тренировочных данных.
Практическое применение
AgentWrite успешно увеличил выходную ёмкость модели GPT-4o с 2 000 до примерно 20 000 слов, демонстрируя эффективность в обработке задач ультрадлинного поколения. Оценка с использованием бенчмарка LongBench-Write показала повышение общих оценок качества для модели, обученной с набором данных LongWriter-6k, особенно в задачах с выводом от 2 000 до 4 000 слов. Самое значительное улучшение наблюдалось в измерении «Объём и глубина», с 18% абсолютным улучшением по сравнению с базовой моделью.
Заключение
Эта статья решает существенное ограничение в текущих LLM путём предложения фреймворка AgentWrite для расширения объёма вывода свыше типичного ограничения в 2 000 слов. Модель LongWriter-6k, разработанная с использованием этой схемы, успешно создаёт качественные выводы объемом более 10 000 слов путём включения длинных данных вывода в процесс выравнивания. Обширные эксперименты и абляционные исследования демонстрируют эффективность данного подхода. Авторы предлагают направления для расширения фреймворка, улучшения качества данных и решения проблем эффективности вывода. Они подчеркивают, что у текущих LLM есть неиспользуемый потенциал для больших окон вывода, который можно разблокировать путем стратегической тренировки на длинных данных вывода. Это исследование является значительным прогрессом в области создания ультрадлинных текстов и предоставляет основу для дальнейших разработок в этой области.
Подробности о работе и доступ к репозиторию на GitHub доступны по ссылке. Вся заслуга за это исследование принадлежит исследователям проекта.
Не забудьте следить за нами в Twitter и присоединиться к нашим Telegram-каналу и группе в LinkedIn. Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit и следить за предстоящими вебинарами по искусственному интеллекту.
Arcee AI представляет Arcee Swarm: новаторское сочетание агентов, вдохновленное кооперативным интеллектом, обнаруженным в самой природе.
Оригинальная статья: Scaling LLM Outputs: The Role of AgentWrite and the LongWriter-6k Dataset
Источник: MarkTechPost