
«`html
ArabLegalEval: многозадачный набор данных для оценки юридических знаний в LLMs
Оценка юридических знаний в крупных языковых моделях (LLMs) в основном сосредоточена на англоязычных контекстах, с такими показателями, как MMLU и LegalBench, предоставляющими основные методологии. Однако оценка арабских юридических знаний оставалась значительной проблемой. Предыдущие усилия включали перевод англоязычных юридических наборов данных и использование ограниченных арабских юридических документов, подчеркивая необходимость специализированных арабских юридических ресурсов для ИИ.
Практические решения и ценность:
ArabLegalEval представляет собой критически важный показатель для устранения этих ограничений. Этот новый инструмент берет задачи из саудовских юридических документов, предоставляя более актуальный контекст для арабскоговорящих пользователей. Он направлен на расширение критериев оценки, включение более широкого спектра арабских юридических документов и оценку более широкого спектра моделей. ArabLegalEval представляет собой значительное развитие в оценке возможностей LLMs в арабских юридических контекстах.
Быстрые достижения в LLMs улучшили различные задачи обработки естественного языка, но их оценка в юридических контекстах, особенно для неанглоязычных языков, таких как арабский, остается недостаточно исследованной. ArabLegalEval устраняет этот пробел, представляя многозадачный набор данных для оценки профессионализма LLMs в понимании и обработке арабских юридических текстов. Вдохновленный наборами данных, такими как MMLU и LegalBench, он включает задачи, происходящие из саудовских юридических документов и синтезированные вопросы.
Сложность арабского юридического языка требует специализированных показателей для точной оценки возможностей LLMs в этой области. В то время как существующие показатели, такие как ArabicMMLU, тестируют общее рассуждение, ArabLegalEval фокусируется специально на юридических задачах, разработанных в сотрудничестве с юридическими специалистами. Этот показатель направлен на оценку широкого спектра LLMs, включая собственные многоязычные и открытые арабские модели, чтобы выявить их сильные и слабые стороны в области юридического рассуждения.
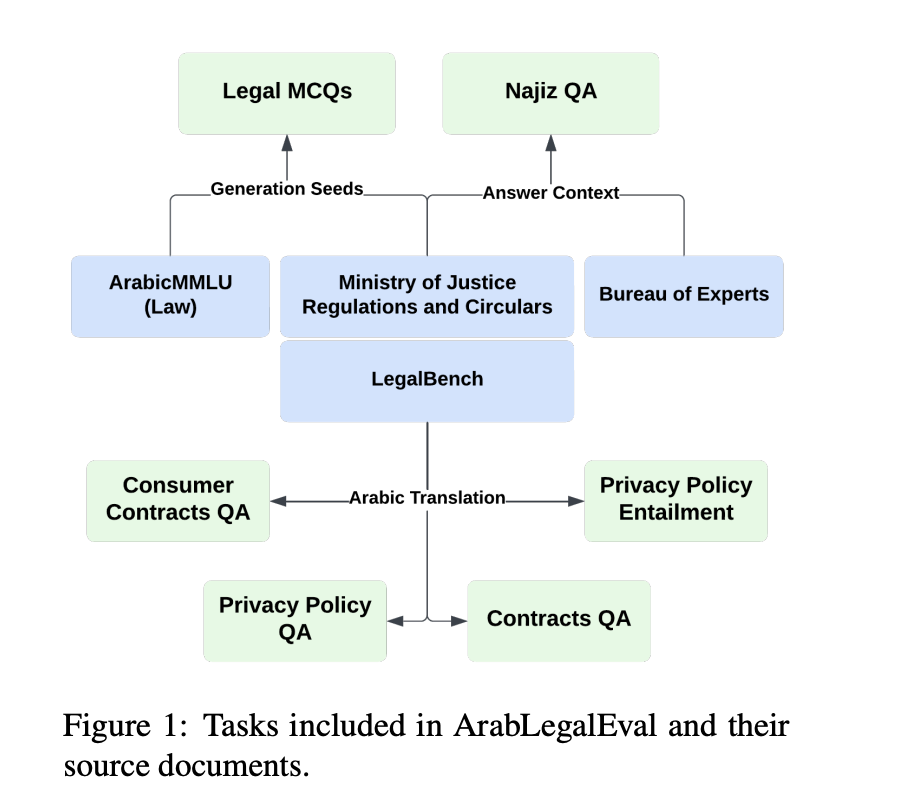
Методология включает систематический подход к созданию и проверке набора данных для оценки арабских юридических знаний в LLMs. Подготовка данных начинается с получения юридических документов от официальных органов и веб-скрапинга для захвата соответствующих регуляций. Процесс затем фокусируется на генерации синтетических вопросов с множественным выбором ответов (MCQs) с использованием трех методов: QA to MCQ, Chain of Thought и Retrieval-based In-Context Learning. Эти техники решают проблемы формулирования вопросов и генерации правдоподобных вариантов ответов.
После генерации вопросов, строгий процесс фильтрации использует косинусную схожесть для идентификации соответствующего текста для каждого вопроса, что является важным для оценки возможностей рассуждения моделей. Окончательный набор данных, включающий 10 583 MCQs, проходит ручную проверку и экспертную валидацию для обеспечения качества. Метрики оценки включают метрики Rouge для качества перевода и оценки возможностей рассуждения. Эта комплексная методология, включающая сотрудничество с юридическими экспертами, направлена на создание надежного показателя для оценки арабских юридических знаний в LLMs, учитывая уникальные вызовы юридического языка.
Показатель ArabLegalEval раскрывает значительные исследования в области производительности LLMs в арабских юридических задачах. Базовые уровни экспертов-людей предоставляют важные сравнения, а обширные анализы по различным задачам подчеркивают эффективность оптимизированных промптов с небольшим количеством шагов и рассуждения Chain of Thought. Меньшие LMs демонстрируют улучшенную производительность с помощью моделей-учителей, клонированных самими собой, в сценариях с небольшим количеством шагов. Традиционные метрики оценки показывают ограничения в захвате семантических сходств, подчеркивая необходимость более тонких методов оценки. Языковые соображения подчеркивают важность соответствия языков ответа и ссылки. Эти результаты подчеркивают важную роль оптимизации промптов, обучения с небольшим количеством шагов и усовершенствованных методов оценки для точной оценки арабских юридических знаний в LLMs.
В заключение, исследователи создают специализированный показатель для оценки юридических рассуждений в LLMs, сосредоточившись на саудовских регуляциях и переведенных проблемах LegalBench. Будущие улучшения направлены на включение дополнительных саудовских юридических документов, расширяя область применения показателя. Оптимизированные промпты с небольшим количеством шагов значительно улучшают производительность LLM на MCQ, с конкретными примерами, оказывающими значительное влияние на результаты. Рассуждение Chain-of-Thought в сочетании с примерами с небольшим количеством шагов улучшает возможности модели, особенно для меньших LLMs с использованием моделей-учителей, клонированных самими собой. Это исследование подчеркивает важность надежных рамок оценки для арабских юридических знаний в LLMs и выделяет необходимость оптимизированных методов обучения для улучшения производительности модели в этой области.
Посмотрите статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашей группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Arcee AI представляет Arcee Swarm: революционное сочетание агентов MoA, вдохновленное кооперативным интеллектом, обнаруженным в самой природе
Пост опубликован на MarkTechPost.