
«`html
Применение ИИ в решении проблем многоруких бандитов с ограниченными ресурсами
Применение обучения с подкреплением (RL) для решения проблем сложного принятия решений, особенно в ситуациях с ограниченными ресурсами и неопределенными результатами, недавно стало очень полезным. В различных областях применения RL, то, что отличает «непокойных многоруких бандитов» (RMABs), — это их решение проблем распределения ресурсов между несколькими агентами. Модели RMAB изображают управление несколькими точками принятия решений или «руками», каждая из которых требует тщательного выбора для максимизации накопленных вознаграждений. Такие модели оказались инструментальными в таких областях, как здравоохранение, где они оптимизируют поток медицинских ресурсов; интернет-реклама, где они улучшают эффективность стратегий таргетинга; и охрана природы, где они информируют операции по борьбе с браконьерством. Однако некоторые проблемы остаются в применении RMAB в реальной жизни.
Проблемы и решения
Систематические ошибки данных являются одной из основных проблем, влияющих на эффективную реализацию RMAB. Эти ошибки могут быть результатом несогласованных протоколов сбора данных в различных географических областях, добавления шума для обеспечения дифференциальной конфиденциальности или изменений в процедурах обработки. Такие врожденные ошибки приводят к неправильной оценке вознаграждений и, следовательно, могут привести к неоптимальным решениям со стороны RMAB. Например, сообщается о случае завышения ожидаемой даты поставки в здравоохранении матери и ребенка, где несогласованные методы сбора данных приводят к распределению ресурсов и снижению родов в медицинских учреждениях. Эти ошибки становятся особенно губительными, когда они затрагивают только некоторые точки принятия решений — так называемые «шумные руки» — в модели RMAB.
Было разработано несколько вариантов методов глубокого обучения с подкреплением для решения таких проблем. Цель состоит в обеспечении оптимальной производительности методов RMAB в условиях шумных данных. Большинство существующих подходов предполагают надежный сбор данных со всех рук, что может быть правдой только в некоторых прикладных областях реального мира. Эти методы иногда упускают лучшие действия, когда некоторые руки подвержены ошибкам данных, поскольку так называемые ложные оптимумы могут ввести их в заблуждение — случаи, когда алгоритм ошибочно принимает неподходящее решение за лучшее. Неправильная идентификация может существенно снизить эффективность и эффективность, особенно в области здравоохранения или борьбы с эпидемиями.
Исследователи из Гарвардского университета и Google предложили новую парадигму обучения в рамках RMAB: общение. Обмен информацией между многими руками RMAB позволяет им помогать друг другу исправлять систематические ошибки в данных, тем самым улучшая качество принятия решений. Открыв возможность для рук общаться, исследователи надеялись уменьшить влияние шумных данных на производительность RMAB. Предложенный метод был протестирован в широком диапазоне сценариев, от синтетических сред до сценариев здравоохранения матери и ребенка и моделей борьбы с эпидемиями, что подтверждает применимость этого метода во многих областях.
Алгоритм обучения через общение
Подход к обучению через общение использует мультиагентную структуру марковских процессов принятия решений, предоставляющую возможность общения с другой рукой схожих характеристик. Когда одна рука должна общаться, она получает параметры функции Q от другой руки и улучшает свою политику поведения. Обмениваясь информацией таким образом, рука может исследовать лучшие стратегии и избежать ошибок неподходящих действий, вызванных шумными данными. Исследователи создали разложенную архитектуру Q-сети для управления совместной полезностью общения всех рук. Конкретно их эксперименты показали, что общение в обоих направлениях между шумными и нешумными руками может быть полезным, если политика поведения принимающей руки достигает разумного охвата пространства состояний и действий.
Результаты и применимость
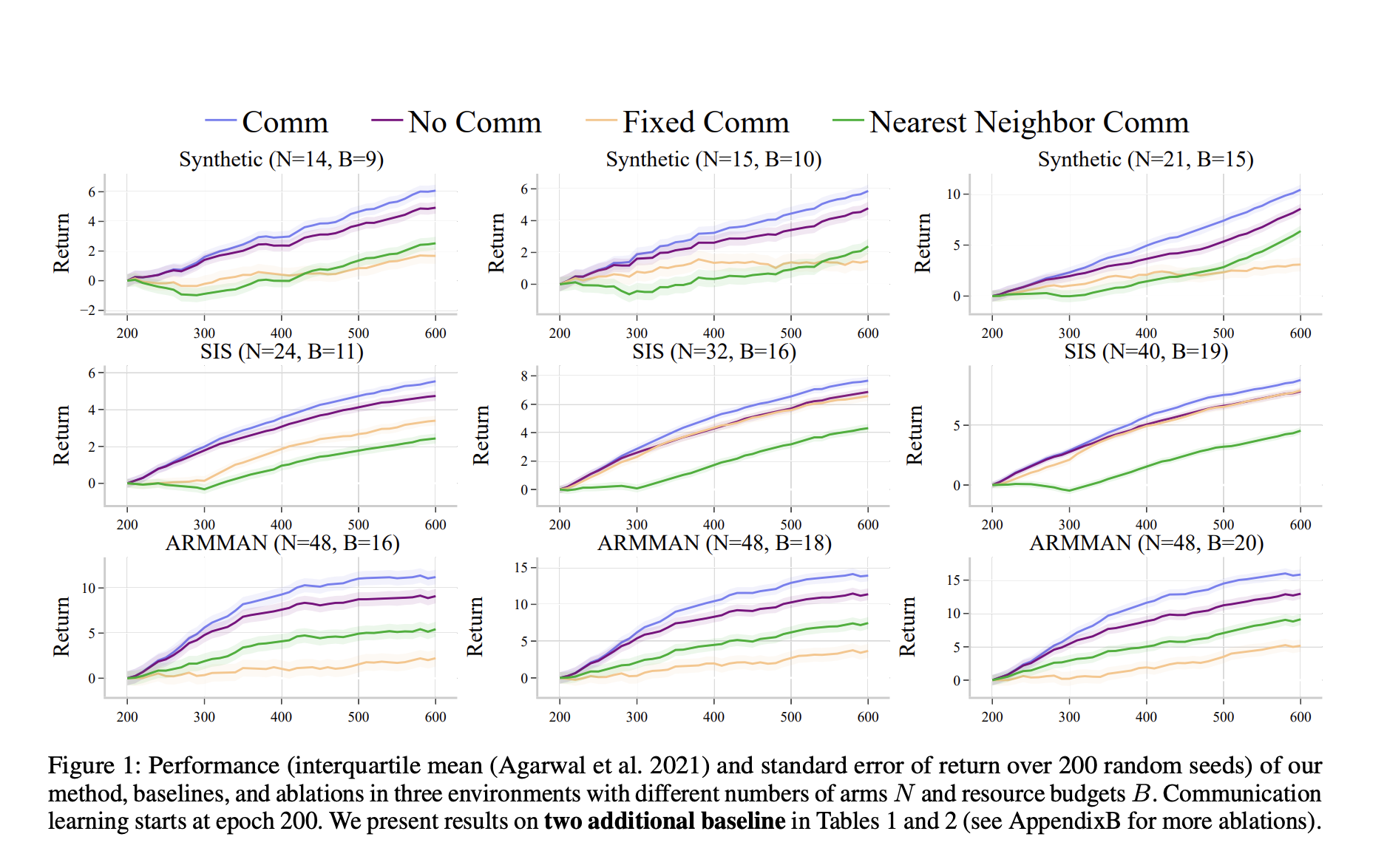
Исследователи обоснованно подтвердили свой подход обширными эмпирическими тестами. В эмпирических испытаниях они сравнили производительность предложенного метода обучения через общение с производительностью базовых методов. Например, в искусственной среде RMAB с 15 руками и бюджетом 10 предложенный метод был лучше как не общающихся, так и фиксированных стратегий общения с приблизительным возвратом 10 к эпохе 600, значительно улучшая возврат по сравнению с базовой моделью без общения, которая достигла возврата около 8. Подобные результаты были получены в реальных сценариях, таких как модель здравоохранения матери и ребенка ARMMAN, где для среды с 48 руками и бюджетом 20 возврат, достигнутый методом, был 15 по сравнению с 12,5, достигнутыми базовой моделью без общения. Эти результаты показывают, как данное обучение через общение является общим по широкому спектру областей проблем, ограничений ресурсов и уровней шума в данных.
В заключение, исследование представляет революционный алгоритм обучения через общение, который значительно улучшает производительность RMAB в шумных средах. Позволяя рукам обмениваться параметрами функции Q и учиться на опыте друг друга, предложенный метод эффективно снижает влияние систематических ошибок данных. Он улучшает общую эффективность принятия решений о распределении ресурсов. Эмпирические результаты, подтвержденные строгим теоретическим анализом, демонстрируют, что данный подход не только превосходит существующие методы, но также предлагает большую устойчивость и адаптивность к вызовам реального мира. Этот прогресс в технологии RMAB потенциально может революционизировать способы решения проблем распределения ресурсов в различных областях, от здравоохранения до общественной политики, предоставляя путь к более эффективным и эффективным процессам принятия решений.
Источник изображения: MarkTechPost
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Harvard and Google Researchers Developed a Novel Communication Learning Approach to Enhance Decision-Making in Noisy Restless Multi-Arm Bandits.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`




















