
«`html
DaRec: Уникальный фреймворк для выравнивания совместных моделей и LLM в системах рекомендаций
Системы рекомендаций приобрели популярность в различных областях применения, и алгоритмы на основе глубоких нейронных сетей продемонстрировали впечатляющие возможности. Большие языковые модели (LLM) недавно проявили свою компетентность в нескольких задачах, что побудило исследователей исследовать их потенциал в системах рекомендаций. Однако две основные проблемы мешают принятию LLM: высокие вычислительные требования и игнорирование совместных сигналов. Недавние исследования сосредоточились на методах семантической выравнивания для передачи знаний от LLM к совместным моделям. Тем не менее, существует значительный семантический разрыв из-за разнообразной природы данных взаимодействия в совместных моделях по сравнению с естественным языком, используемым в LLM. Попытки устранить этот разрыв с помощью контрастного обучения показали ограничения, потенциально вносящие шум и ухудшающие производительность рекомендаций.
Графовые нейронные сети (GNN) приобрели популярность в системах рекомендаций, особенно для совместной фильтрации. Методы, такие как LightGCN, NGCF и GCCF, используют GNN для моделирования взаимодействий пользователя с элементами, но сталкиваются с проблемами шумной неявной обратной связи. Для смягчения этого были применены методы обучения без учителя, такие как контрастное обучение, с подходами, такими как SGL, LightGCL и NCL, показавшими улучшенную устойчивость и производительность. LLM вызвали интерес в рекомендациях, и исследователи исследуют способы интеграции их мощных представлений. Исследования, такие как RLMRec, ControlRec и CTRL, используют контрастное обучение для выравнивания встраиваний совместной фильтрации с семантическими представлениями LLM.
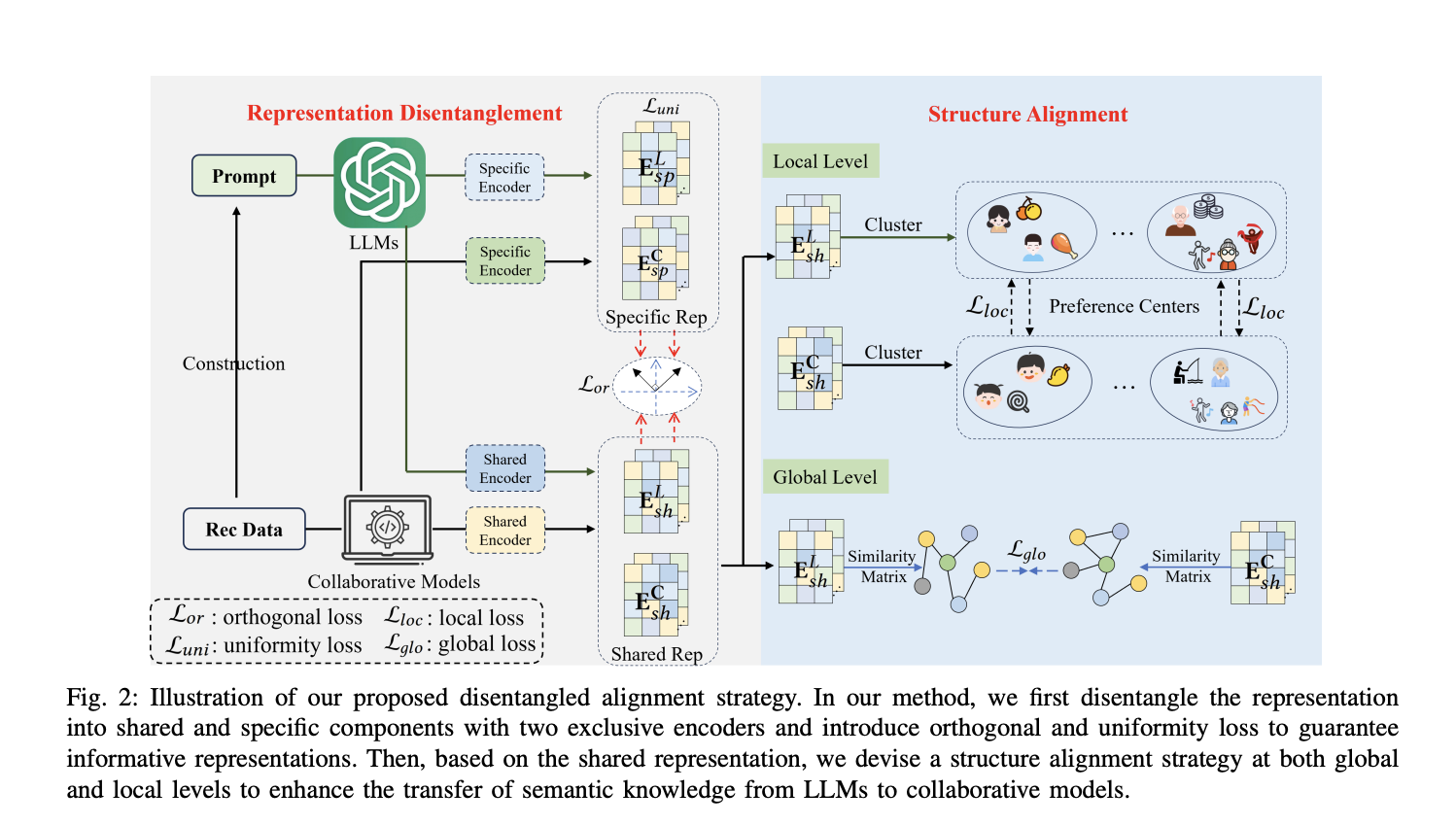
Исследователи Национального университета оборонных технологий в Чанша, Baidu Inc в Пекине и Anhui Province Key Laboratory Университета науки и технологий Китая представили уникальный фреймворк DaRec для модели рекомендаций и LLM (DaRec), уникальный фреймворк, решающий ограничения в интеграции LLM с системами рекомендаций. Вдохновленный теоретическими результатами, он выравнивает семантические знания через раздельное представление вместо точного выравнивания. Фреймворк состоит из трех ключевых компонент: (1) разделение представлений на общие и специфические компоненты для уменьшения шума, (2) использование потерь однородности и ортогональности для поддержания информативности представлений и (3) реализация стратегии структурного выравнивания на локальном и глобальном уровнях для эффективной передачи семантических знаний.
DaRec — инновационный фреймворк для выравнивания семантических знаний между LLM и совместными моделями в системах рекомендаций. Этот подход мотивирован теоретическими результатами, указывающими на то, что точное выравнивание представлений может быть неоптимальным. DaRec состоит из трех основных компонент:
Разделение представлений: фреймворк разделяет представления на общие и специфические компоненты для совместных моделей и LLM. Это уменьшает негативное влияние специфической информации, которая может вносить шум во время выравнивания.
Потери однородности и ортогональности: DaRec использует функции потерь однородности и ортогональности для поддержания информативности представлений и обеспечения уникальной, дополняющей информации в специфических и общих компонентах.
Стратегия структурного выравнивания: фреймворк реализует двухуровневый подход к выравниванию:
- Глобальное структурное выравнивание: выравнивает общую структуру общих представлений.
- Локальное структурное выравнивание: использует кластеризацию для определения центров предпочтений и адаптивного выравнивания их.
DaRec стремится преодолеть ограничения предыдущих методов, предоставляя более гибкую и эффективную стратегию выравнивания, потенциально улучшая производительность систем рекомендаций на основе LLM.
DaRec превзошел как традиционные методы совместной фильтрации, так и подходы к рекомендациям, улучшенные с помощью LLM, на трех наборах данных (Amazon-book, Yelp, Steam) по нескольким метрикам (Recall@K, NDCG@K). Например, на наборе данных Yelp, DaRec улучшил результаты в сравнении со вторым лучшим методом (AutoCF) на 3,85%, 1,57%, 3,15% и 2,07% для R@5, R@10, N@5 и N@10 соответственно.
Анализ гиперпараметров показал оптимальную производительность при числе кластеров K в диапазоне [4,8], параметре компромисса λ в диапазоне [0,1, 1,0] и размере выборки N̂ равном 4096. Экстремальные значения этих параметров приводили к уменьшению производительности.
Визуализация t-SNE показала, что DaRec успешно улавливает основные интересы в предпочтениях пользователей.
В целом, DaRec продемонстрировал превосходную производительность по сравнению с существующими методами, проявляя устойчивость при различных значениях гиперпараметров и эффективно улавливая структуры интересов пользователей.
Это исследование представляет DaRec, уникальный фреймворк для выравнивания совместных моделей и LLM в системах рекомендаций. Основываясь на теоретическом анализе, показывающем, что точное выравнивание может быть неоптимальным, DaRec разделяет представления на общие и специфические компоненты. Он реализует стратегию двухуровневого выравнивания структуры на глобальном и локальном уровнях. Авторы предоставляют теоретическое доказательство того, что их метод создает представления с более релевантной и менее нерелевантной информацией для задач рекомендаций. Обширные эксперименты на стандартных наборах данных демонстрируют превосходную производительность DaRec по сравнению с существующими методами, что представляет собой значительный прогресс в интеграции LLM с моделями совместной фильтрации.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 49k+ ML SubReddit
Найдите предстоящие вебинары по ИИ здесь
Опубликовано на MarkTechPost
«`




















