
«`html
NVIDIA представила Mistral-NeMo-Minitron 8B: новейшую модель ИИ, переопределяющую эффективность и производительность с помощью передовых методов обрезки и дистилляции знаний
Новая модель Mistral-NeMo-Minitron 8B от NVIDIA представляет собой высокотехнологичную модель обработки естественного языка, которая продолжает развитие передовых технологий искусственного интеллекта. Она выделяется своей впечатляющей производительностью на различных тестах, что делает ее одной из самых передовых моделей в своем классе.
Процесс обрезки модели и дистилляции знаний
Обрезка модели — это техника уменьшения размера и повышения эффективности моделей ИИ путем удаления менее критических компонентов. В случае Mistral-NeMo-Minitron 8B была выбрана техника обрезки по ширине для достижения оптимального баланса между размером и производительностью. После обрезки модель проходит процесс легкой дистилляции знаний, который передает знания от оригинальной, более крупной модели-учителя к обрезанной, более маленькой модели-ученику.
Производительность и оценка
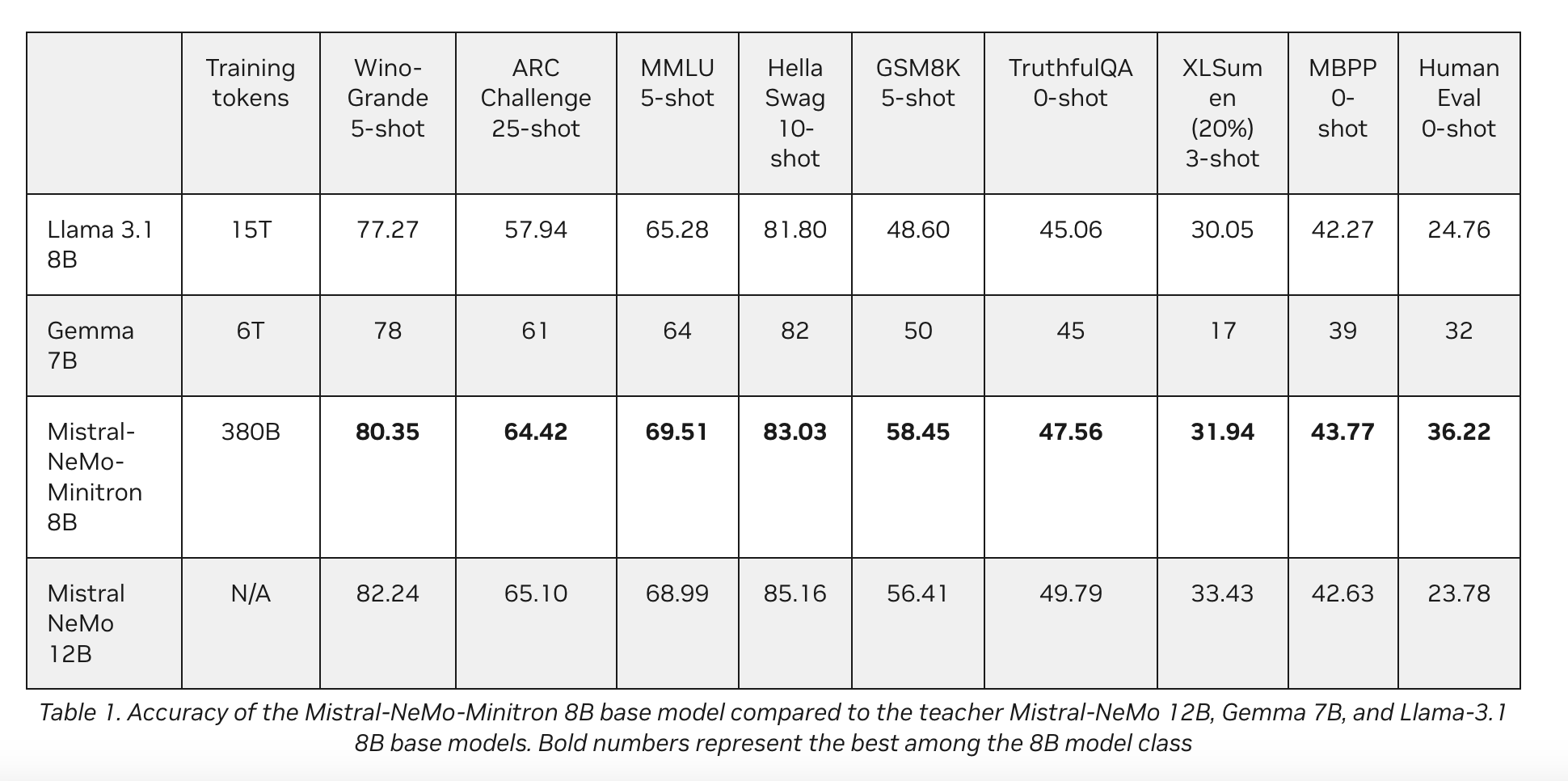
Производительность Mistral-NeMo-Minitron 8B свидетельствует о успехе этого подхода к обрезке и дистилляции. Модель последовательно превосходит другие модели своего класса по различным популярным тестам. Так, она показала результаты 80.35 в тесте WinoGrande, 69.51 в тесте MMLU и 83.03 в тесте HellaSwag, что делает ее одной из самых точных моделей в своей категории.
Технические детали и архитектура
Архитектура модели Mistral-NeMo-Minitron 8B основана на декодере трансформера для авторегрессивного языкового моделирования. Она включает в себя ряд передовых техник, таких как Grouped-Query Attention (GQA) и Rotary Position Embeddings (RoPE), способствующих устойчивой производительности в различных задачах.
Будущие направления и этические соображения
Выпуск Mistral-NeMo-Minitron 8B — это только начало усилий NVIDIA в разработке более маленьких и эффективных моделей с помощью обрезки и дистилляции. Однако важно учитывать ограничения и этические соображения этой модели. Как и многие крупные языковые модели, она была обучена на данных, которые могут содержать токсичный язык и общественные предубеждения. Поэтому важно обеспечить ответственное развитие ИИ и учитывать эти факторы при внедрении модели в реальные приложения.
Заключение
Внедрение Mistral-NeMo-Minitron 8B от NVIDIA открывает новые возможности для эффективности и производительности в области обработки естественного языка. Компания продолжит совершенствовать эту технику, создавая еще более маленькие модели с высокой точностью и эффективностью, интегрируя их в фреймворк NVIDIA NeMo для генеративного ИИ.
Подробнее о модели можно узнать в Model Card and Details.
Все права на это исследование принадлежат исследователям проекта.
Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram Channel и LinkedIn Group.
Если вам нравится наша работа, вам понравится наш newsletter.
Не забудьте присоединиться к нашему 49k+ ML SubReddit.
Найдите предстоящие вебинары по ИИ здесь.
Оригинальная статья опубликована на MarkTechPost.