
«`html
Понимание устной речи для больших языковых моделей (LLM)
Понимание устной речи для больших языковых моделей (LLM) критично для создания более естественного и интуитивного взаимодействия с машинами. Традиционные модели отлично справляются с задачами на основе текста, но испытывают трудности с пониманием человеческой речи, что ограничивает их потенциал в реальных приложениях, таких как голосовые ассистенты, обслуживание клиентов и инструменты доступности. Улучшение понимания речи может улучшить взаимодействие между людьми и машинами, особенно в сценариях, требующих обработки в реальном времени.
Решение от Homebrew Research: Llama3-s v0.2
Компания Homebrew Research представляет Llama3-s v0.2 для решения проблемы понимания устной речи в обработке естественного языка. Текущие языковые модели в основном сосредоточены на тексте и имеют ограниченные возможности в обработке устной речи. Существующие модели понимания речи часто испытывают трудности в сценариях с комплексными акцентами, фоновым шумом или продолжительными аудиовходами.
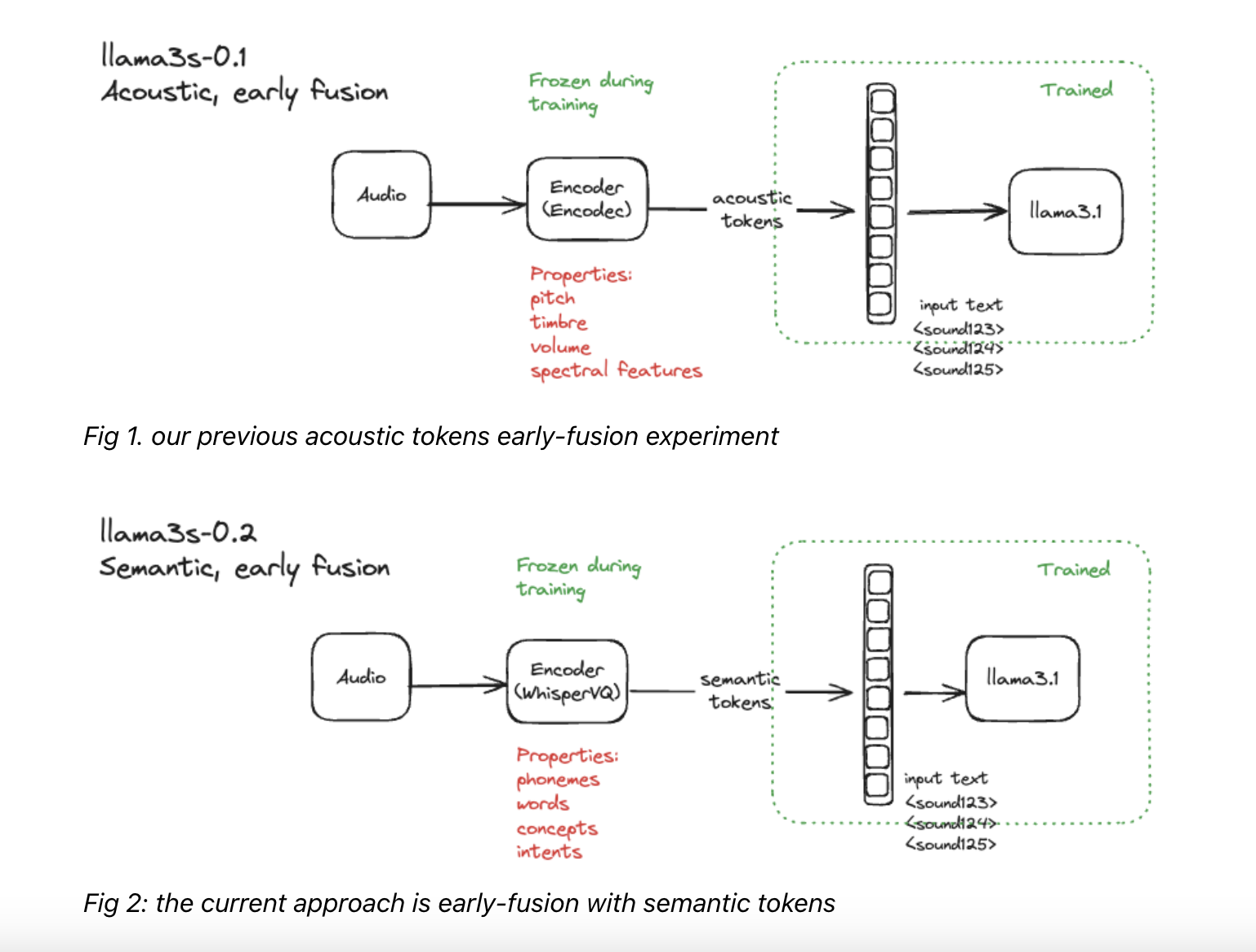
Llama3-s v0.2 строит на основе модели языка Llama 3.1, вводя значительные улучшения, специально разработанные для улучшения понимания речи. Модель использует предварительно обученный аудио-кодировщик (например, WhisperVQ) для преобразования устной речи в числовые представления, которые модель языка может обрабатывать. Этот мультимодальный подход к обучению, который интегрирует текстовые и аудиовходы, позволяет Llama3-s v0.2 эффективно изучать взаимосвязь между устной речью и ее текстовым представлением. Кроме того, модель использует семантические токены, абстрактные представления значений слов, для улучшения своего понимания основного содержания речи.
Llama3-s v0.2 улучшает свои возможности понимания речи через двухэтапный процесс обучения. На первом этапе модель предварительно обучается на реальных речевых данных с использованием набора данных MLS-10k, который включает 10 часов неразмеченной многоязычной человеческой речи. Это предварительное обучение улучшает способность модели к обобщению семантических токенов. На втором этапе модель проходит инструктивную настройку смешанными синтетическими данными, используя WhisperVQ для семантического кодирования речевых данных. Этот подход помогает модели учиться на основе комбинации инструкций по обучению речи и текстовых инструкций. Llama3-s v0.2 продемонстрировала многообещающие результаты, превосходящие существующие модели по нескольким бенчмаркам, включая оценки ALPACA-Audio и AudioBench.
В заключение, Llama3-s v0.2 представляет собой значительный шаг в развитии мультимодальных языковых моделей, способных понимать устную речь. Путем интеграции аудио- и текстовых входов и использования продвинутой семантической токенизации модель преодолевает ограничения, с которыми сталкиваются традиционные языковые модели в понимании речи. Эксперименты, проведенные с помощью Llama3-s v0.2, открывают новые возможности для реальных приложений, делая технологии более доступными и удобными для пользователей.
Подробности
Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и присоединиться к нашему каналу в Телеграме и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Оригинальная статья: MarkTechPost
«`





















