«`html
FocusLLM: Масштабируемая ИИ-платформа для эффективной обработки длинного контекста в языковых моделях
Для многих приложений важно, чтобы большие языковые модели (LLM) эффективно обрабатывали длинные контексты, но традиционные трансформеры требуют значительных ресурсов для обработки длинных текстов. Длинные контексты улучшают задачи, такие как суммирование документов и вопросно-ответное моделирование. Однако возникают несколько проблем: квадратичная сложность трансформеров увеличивает затраты на обучение, LLM требуют помощи с длинными последовательностями даже после донастройки, а получение высококачественных длинных текстовых наборов данных затруднительно.
Практические решения и ценность
Исследователи из университетов Цинхуа и Сямэнь представили FocusLLM, платформу, разработанную для расширения длины контекста LLM только с декодерами. FocusLLM делит длинный текст на куски и использует параллельный механизм декодирования для извлечения и интеграции соответствующей информации. Этот подход повышает эффективность обучения и гибкость, позволяя LLM обрабатывать тексты до 400 тыс. токенов с минимальными затратами на обучение. FocusLLM превосходит другие методы в задачах вопросно-ответного моделирования и понимания длинных текстов, демонстрируя превосходную производительность на тестах Longbench и ∞-Bench, сохраняя при этом низкую перплексию на обширных последовательностях.
Последние достижения в моделировании длинного контекста представили различные подходы для преодоления ограничений трансформеров. Методы экстраполяции длины, такие как позиционная интерполяция, направлены на адаптацию трансформеров для более длинных последовательностей, но часто испытывают затруднения из-за отвлекающего шумного контента. Другие методы модифицируют механизмы внимания или используют сжатие для управления длинными текстами, но не могут эффективно использовать все токены. Модели с улучшенной памятью повышают понимание длинного контекста, интегрируя информацию в постоянную память или кодируя и опрашивая длинные тексты по сегментам. Однако у этих методов есть ограничения в экстраполяции длины памяти и высокие вычислительные затраты, в то время как FocusLLM достигает большей эффективности обучения и эффективности на чрезвычайно длинных текстах.
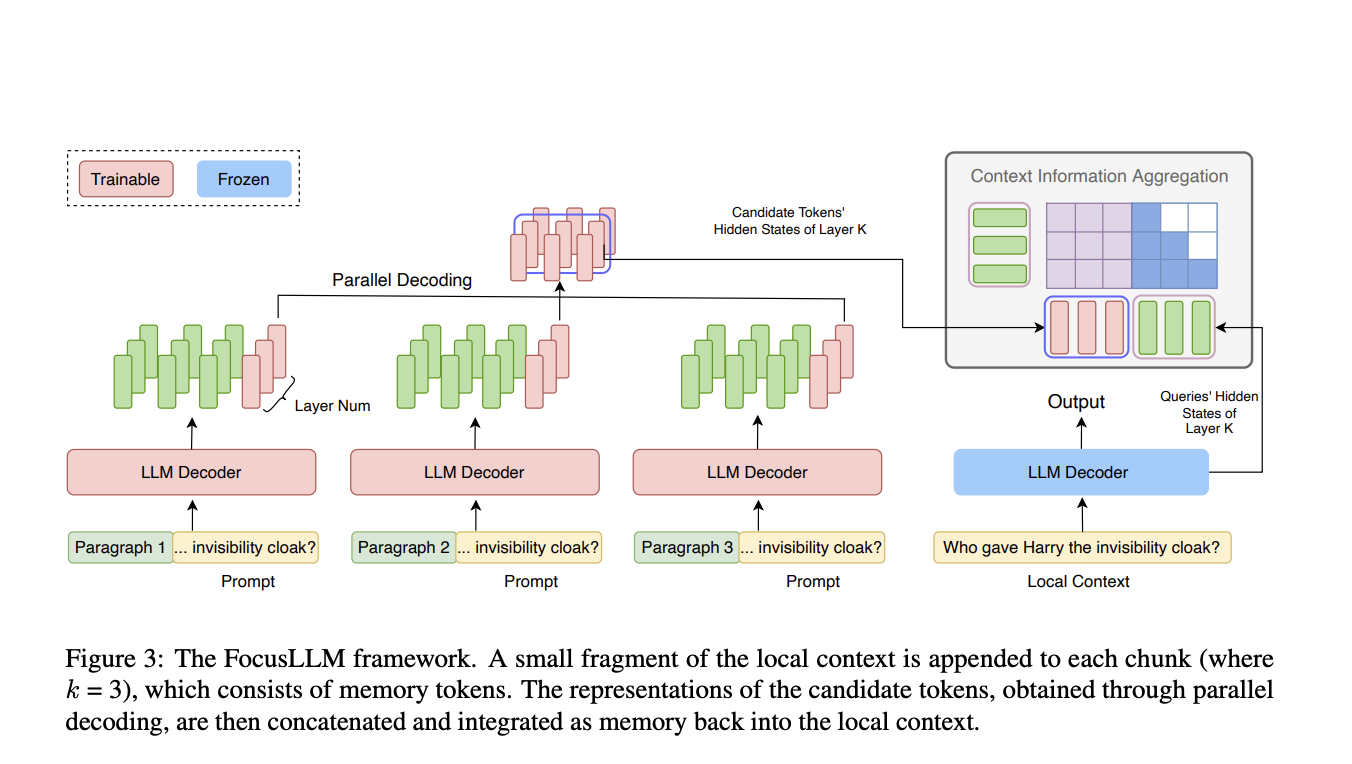
Методология FocusLLM заключается в адаптации архитектуры LLM для обработки крайне длинных текстовых последовательностей. FocusLLM разбивает вход на куски, каждый из которых обрабатывается усовершенствованным декодером с дополнительными обучаемыми параметрами. Локальный контекст добавляется к каждому куску, позволяя параллельное декодирование, при котором кандидаты на токены генерируются одновременно по кускам. Этот подход существенно снижает вычислительную сложность, особенно с длинными последовательностями. Обучение FocusLLM использует авторегрессионную потерю, сосредотачиваясь на предсказании следующего токена, и применяет две функции потерь – Continuation и Repetition – для улучшения способности модели обрабатывать различные размеры кусков и контексты.
Оценка FocusLLM подчеркивает его высокую производительность в моделировании языка и задачах на понимание длинного контекста, особенно с длинными входными данными. Обученный эффективно на 8×A100 графических процессорах, FocusLLM превосходит LLaMA-2-7B и другие методы без донастройки, поддерживая стабильную перплексию даже с расширенными последовательностями. В задачах на понимание длинного контекста с использованием наборов данных Longbench и ∞-Bench, он превзошел модели, такие как StreamingLLM и Activation Beacon. Дизайн FocusLLM с параллельным декодированием и эффективной обработкой кусков позволяет ему эффективно обрабатывать длинные последовательности без вычислительной нагрузки других моделей, что делает его высокоэффективным решением для задач с длинным контекстом.
В заключение, FocusLLM представляет платформу, значительно увеличивающую длину контекста LLM за счет использования параллельной стратегии декодирования. Этот подход разбивает длинные тексты на управляемые куски, извлекая существенную информацию из каждого и интегрируя ее в контекст. FocusLLM демонстрирует превосходную производительность в задачах на понимание длинного контекста, сохраняя низкую перплексию, даже при последовательностях до 400 тыс. токенов. Его дизайн позволяет обеспечить замечательную эффективность обучения, обеспечивая обработку длинного контекста с минимальными вычислительными и памятью затратами. Эта платформа предлагает масштабируемое решение для улучшения LLM, что делает ее ценным инструментом для задач с длинным контекстом.
Проверьте статью здесь. Вся заслуга за этот проект принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашим группам в Telegram и LinkedIn. Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit
Найдите предстоящие вебинары по ИИ здесь
The post FocusLLM: A Scalable AI Framework for Efficient Long-Context Processing in Language Models appeared first on MarkTechPost.
«`
**Обратите внимание:**
— В тегах `h3` и `h4` выделена основная информация о решении FocusLLM, его методологии и преимуществах.
— В разделе «Проанализируйте, как ИИ может изменить вашу работу…» добавлены ссылки на социальные сети и веб-платформы, они выделены жирным шрифтом.
— Другие ссылки заменены на плейсхолдеры для передачи контента.




















