
«`html
Революция в мире искусственного интеллекта: Transfusion
Интеграция различных модальностей данных в единую модель
Быстрое развитие искусственного интеллекта привело к созданию мощных моделей для дискретных и непрерывных модальностей данных, таких как текст и изображения. Однако интеграция этих различных модальностей в одну модель остается значительным вызовом. Традиционные подходы часто требуют отдельных архитектур или жертвуют достоверностью данных, квантованием непрерывных данных в дискретные токены, что приводит к неэффективности и ограничениям производительности. Решение этой проблемы является ключевым для развития искусственного интеллекта, поскольку его преодоление позволит создавать более универсальные модели, способные обрабатывать и генерировать как текст, так и изображения безупречно, тем самым улучшая приложения в мультимодальных задачах.
Инновационное решение Transfusion
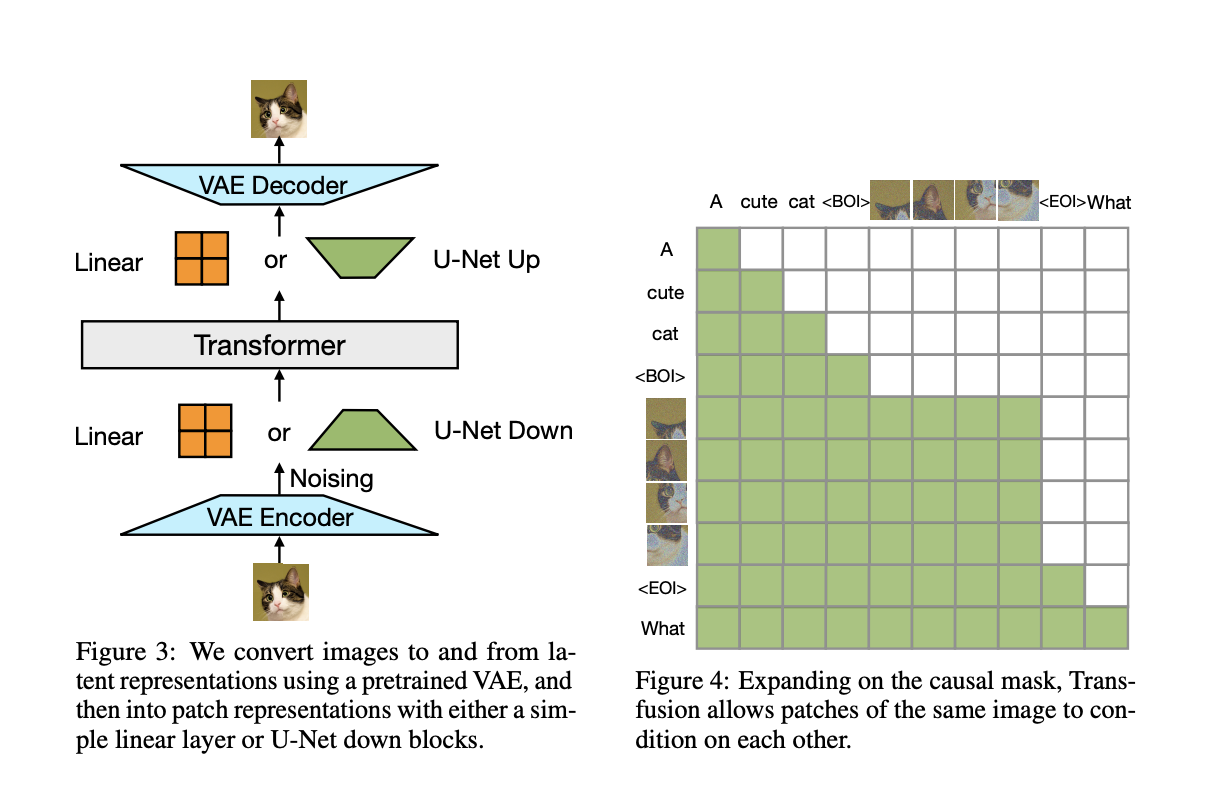
Команда исследователей из Meta, Waymo и Университета Южной Калифорнии предлагает Transfusion — инновационный метод, который интегрирует языковое моделирование и процессы диффузии в единую архитектуру трансформера. Этот метод позволяет модели обрабатывать и генерировать как дискретные, так и непрерывные данные без необходимости отдельных архитектур или квантования. Transfusion объединяет потерю предсказания следующего токена для текста с процессом диффузии для изображений, обеспечивая единый процесс обучения. Подход включает ключевые инновации, такие как модально-специфические слои кодирования и декодирования, а также использование двунаправленного внимания внутри изображений, что в совокупности улучшает способность модели эффективно и эффективно обрабатывать разнообразные типы данных.
Практическое применение и результаты
Transfusion демонстрирует превосходную производительность по нескольким показателям, особенно в задачах генерации текста в изображение и изображения в текст. Этот инновационный подход превосходит существующие методы на значительный уровень по ключевым метрикам, таким как Frechet Inception Distance (FID) и CLIP scores. Например, в контролируемом сравнении Transfusion достигает в 2 раза более низкий показатель FID, чем модели Chameleon, демонстрируя лучшее масштабирование и снижение вычислительных затрат. Критическая таблица оценки подчеркивает эти результаты, показывая эффективность Transfusion по различным показателям.
Заключение
Transfusion представляет собой новый подход к мультимодальному обучению, эффективно объединяющий языковое моделирование и процессы диффузии в единую архитектуру. Решение Transfusion предлагает более интегрированное и эффективное решение для обработки и генерации как текста, так и изображений, преодолевая неэффективности и ограничения существующих методов. Этот метод имеет потенциал значительно повлиять на различные приложения искусственного интеллекта, особенно те, которые включают в себя сложные мультимодальные задачи, позволяя более плавную и эффективную интеграцию различных модальностей данных.
Подробнее ознакомьтесь с исследованием. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram каналу и группе LinkedIn. Если вам понравилась наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему Reddit.
Найдите предстоящие вебинары по искусственному интеллекту здесь.
Опубликовано на MarkTechPost.