
«`html
Оценка крупных языковых моделей в биомедицинской классификации и распознавании именованных сущностей: оценка влияния методов подсказки и предметной области
LLM-модели все чаще используются в здравоохранении для задач, таких как ответы на вопросы и суммирование документов, проявляя производительность на уровне экспертов в области. Однако их эффективность в традиционных биомедицинских задачах, таких как извлечение структурированной информации, остается под вопросом. В настоящее время методы улучшения моделей в основном сосредоточены на расширении внутренних знаний моделей через методы, такие как настройка и контекстное обучение. Эти методы зависят от доступных данных, часто недостаточных в биомедицинской области из-за сдвигов в предметной области и недостатка ресурсов для конкретных структурированных задач, что делает критическим, но недостаточно изученным, производительность в условиях нулевой подсказки.
Практические решения и ценность:
Исследователи из нескольких учреждений, включая ASUS Intelligent Cloud Services, Imperial College London и University of Manchester, провели исследование для оценки производительности LLM-моделей в медицинской классификации и задачах распознавания именованных сущностей (NER). Они стремились проанализировать, как различные факторы, такие как задача-специфическое рассуждение, предметные знания и добавление внешнего опыта, влияют на производительность LLM. Их результаты показали, что стандартная подсказка превзошла более сложные методы, такие как цепочка рассуждений (CoT) и увеличенное создание (RAG). Исследование подчеркивает вызовы применения продвинутых методов подсказки в биомедицинских задачах и подчеркивает необходимость лучшей интеграции внешних знаний в LLM для прикладных приложений в реальном мире.
Существующая литература по оценке LLM в медицинской области в основном сосредоточена на задачах, таких как ответы на вопросы, суммирование и клиническая кодировка, часто игнорируя структурированные задачи предсказания, такие как классификация документов и распознавание именованных сущностей. Недавние подходы к улучшению производительности LLM включают предварительное обучение в предметной области, настройку инструкций, цепочку рассуждений и RAG. Однако эти методы часто требуют более систематической оценки в контексте структурированного предсказания, что исследование стремится решить.
Для оценки производительности LLM в задачах структурированного предсказания исследование оценивает ряд моделей на биомедицинской классификации текста и задачах NER в истинной нулевой настройке. Этот подход оценивает врожденные параметрические знания моделей, что критично из-за недостатка аннотированных биомедицинских данных. Мы сравниваем эту базовую производительность с улучшениями от цепочки рассуждений, RAG и методов самосогласования, сохраняя постоянные параметрические знания. Техники оцениваются с использованием различных наборов данных, включая англоязычные и нет англоязычные источники, и модели ограничены для обеспечения структурированного вывода.
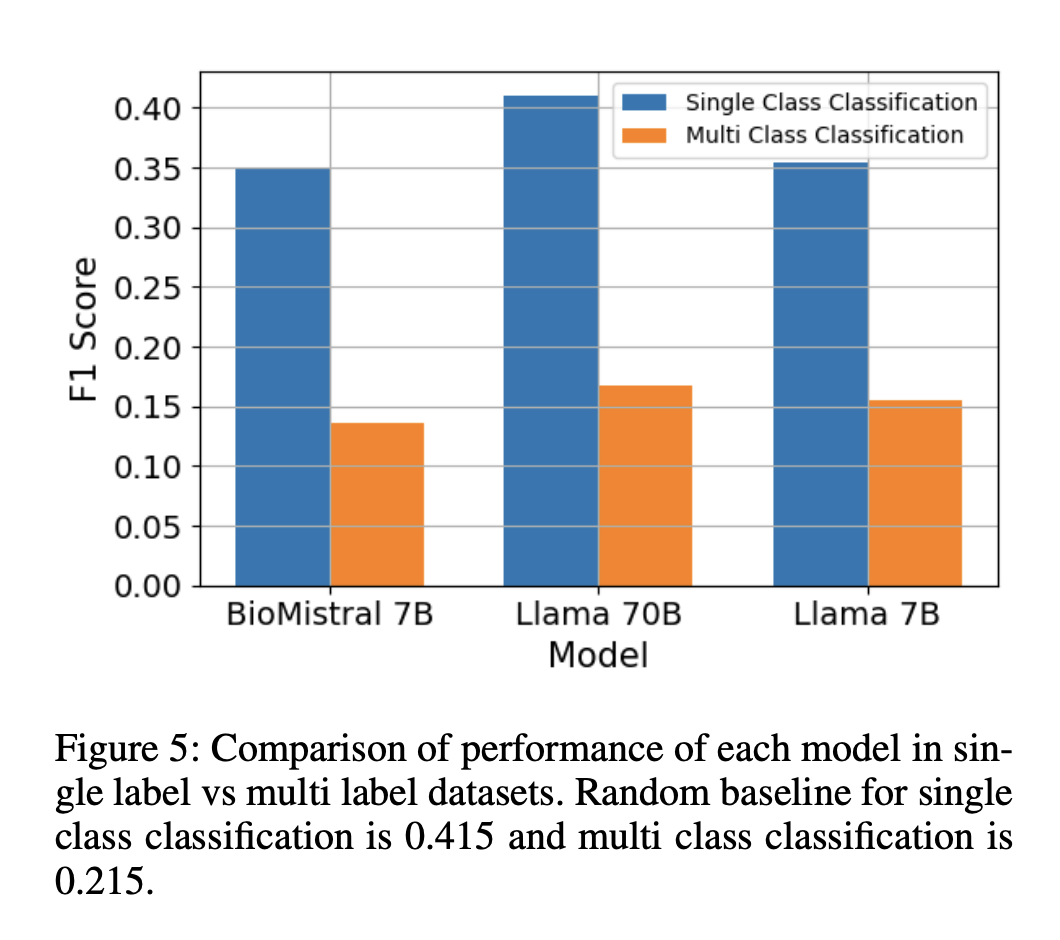
Результаты оценки показывают, что методы рассуждения и улучшения знаний обычно не улучшают производительность. Стандартная подсказка последовательно дает наивысшие значения F1 для задач классификации для всех моделей, при этом BioMistral-7B, Llama-2-70B и Llama-2-7B набирают 36,48%, 40,34% и 34,92% соответственно. Сложные методы, такие как цепочка рассуждений и RAG, часто должны показывать лучшие результаты, чем стандартная подсказка. Более крупные модели, такие как Llama-2-70B, значительно улучшаются, особенно в задачах, требующих продвинутого рассуждения. Однако мультиязычные и частные наборы данных показывают более низкую производительность, и задачи высокой сложности все еще требуют улучшения, причем методы RAG показывают несистематические преимущества.
Исследование оценивает LLM в медицинской классификации и NER, выявляя значительные идеи. Несмотря на продвинутые методы, такие как цепочка рассуждений и RAG, стандартная подсказка последовательно превосходит эти методы во всех задачах. Это подчеркивает фундаментальное ограничение обобщаемости и эффективности LLM в структурированном извлечении биомедицинской информации. Результаты подчеркивают, что текущие продвинутые методы подсказки должны лучше переводиться в биомедицинские задачи, подчеркивая необходимость интеграции предметно-специфических знаний и способностей рассуждения для улучшения производительности LLM в прикладных приложениях в области здравоохранения.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему подпреддиту ML.
Найдите предстоящие вебинары по ИИ здесь.
Опубликовано на MarkTechPost.
«`




















