
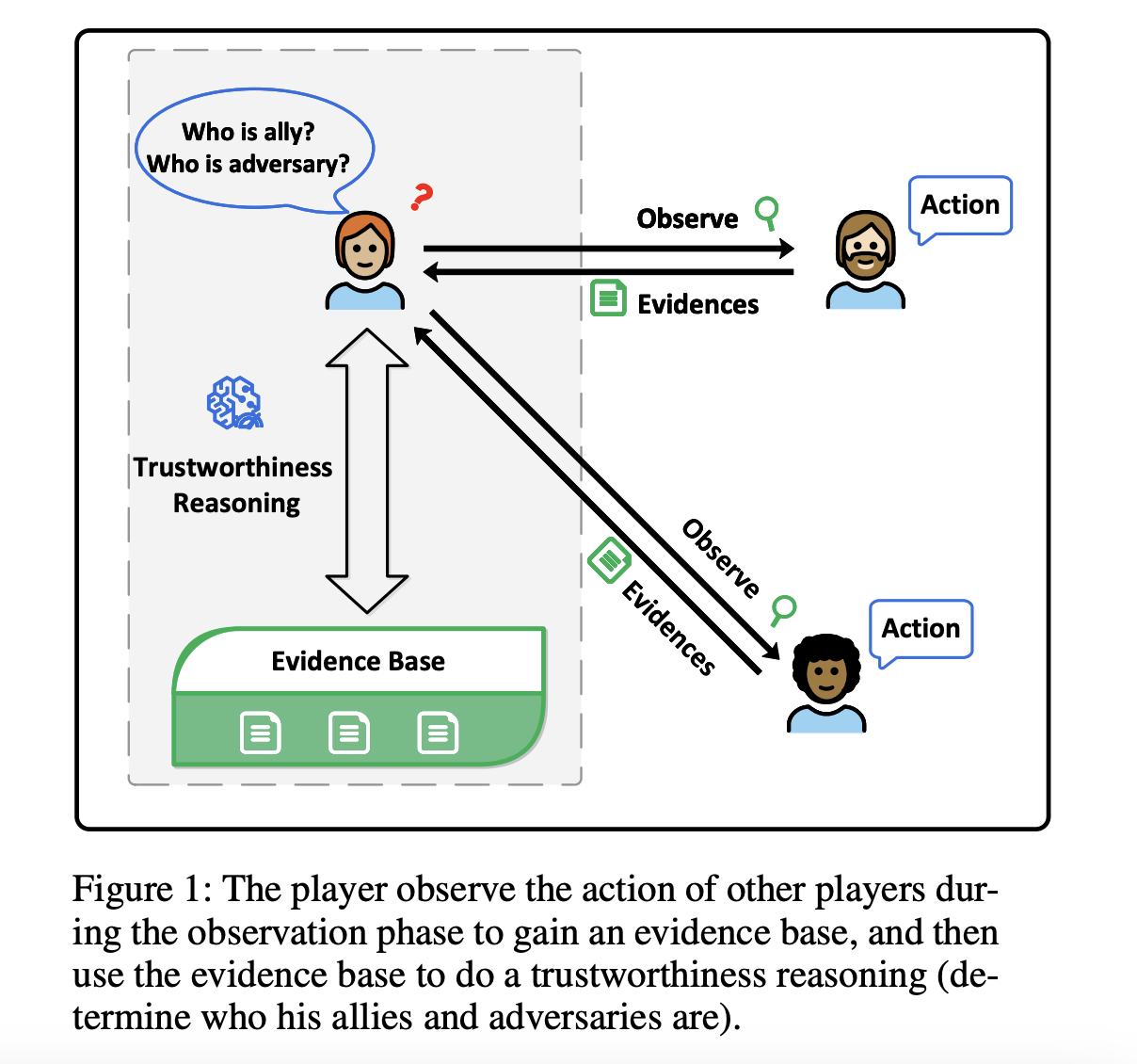
«`html
Разработка AI-решений для доверия в многопользовательских играх с неполной информацией
Разработка AI-решений для доверия в многопользовательских играх с неполной информацией представляет существенные вызовы. Игрокам необходимо оценивать надежность других на основе частичной, часто вводящей в заблуждение информации, принимая решения в реальном времени. Традиционные подходы, сильно зависящие от предварительно обученных моделей, испытывают трудности в адаптации к динамическим средам из-за зависимости от данных, специфичных для области, и обратной связи. Эти ограничения приводят к отсутствию возможности реального времени адаптации, что является важным для эффективного принятия решений в быстро меняющихся сценариях. Решение этих проблем критически важно для продвижения применения ИИ в сложных средах, особенно в контекстах, где оценка доверия в реальном времени критична, таких как в автономных системах и стратегических играх.
Текущие методы оценки доверия в таких средах включают символьное рассуждение, байесовское рассуждение и обучение с подкреплением (RL).
Символьное рассуждение фокусируется на согласованности и последовательности в моделях, но часто лишено гибкости в динамических средах. Байесовское рассуждение, хотя эффективно обновляет убеждения на основе доказательств, требует значительных вычислительных ресурсов и подвержено неточностям при работе с ограниченными или зашумленными данными. RL, хотя и мощное в принятии решений, требует огромного объема обучающих данных, что делает его непригодным для приложений в реальном времени. Эти методы, как правило, сталкиваются с вычислительной сложностью, ограниченной эффективностью данных и неспособностью эффективно работать в динамических средах реального времени.
Разработанный исследователями из Нанкинского университета информационных наук и технологий и Ханчжоуского университета дианзи фреймворк GRATR представляет собой новый подход, использующий Retrieval-Augmented Generation (RAG) для улучшения оценки доверия.
GRATR создает динамический граф доверия, который обновляется в реальном времени, интегрируя доказательственную информацию по мере ее поступления. Этот метод на основе графа решает ограничения статической обработки данных существующими моделями RAG, позволяя системе адаптироваться к развивающейся природе взаимодействий и доверительных отношений в реальном времени. GRATR улучшает рассуждение путем извлечения и интеграции наиболее релевантных доверительных данных из графа, улучшая принятие решений и уменьшая галлюцинации в больших языковых моделях (LLM). Этот подход представляет собой значительное развитие, предоставляя более точное и эффективное решение для оценки доверия в реальном времени.
Фреймворк GRATR инициализируется динамическим графом доказательств, где узлы представляют игроков, а ребра — доверительные отношения.
Граф непрерывно обновляется при получении новых наблюдений, с прикрепленными списками доказательств к ребрам и значениями доверительности к узлам. Ключевые компоненты включают фазу слияния доказательств, где доказательства агрегируются и оцениваются, и фазу прямого извлечения, где значения доверительности обновляются на основе извлеченных цепочек доказательств. GRATR был протестирован на многопользовательской игре «Оборотни» сравнительными экспериментами с базовыми LLM и LLM, улучшенными с помощью Native RAG и Rerank RAG. Набор данных для этих экспериментов состоял из 50 итераций игры с восьмью игроками, включая различные роли, такие как оборотни, жители и лидеры (ведьма, страж и предсказатель).
GRATR значительно превосходит базовые методы по показателям выигрыша и точности рассуждения.
Например, в одной группе экспериментов GRATR достиг общего показателя выигрыша 76,0%, по сравнению с 24,0% для базового LLM. Аналогично показатель выигрыша для роли оборотня составил 72,4% с GRATR по сравнению с 27,6% для базового метода. GRATR последовательно превзошел как Native RAG, так и Rerank RAG по различным метрикам, включая общий показатель выигрыша, показатель выигрыша оборотня и показатель выигрыша лидера. Например, в одном сравнении GRATR достиг общего показателя выигрыша 83,7%, а показатель выигрыша для роли оборотня составил 83,5%, что значительно превышает производительность LLM, улучшенного Rerank RAG.
GRATR представляет собой значительное развитие в оценке доверия для многопользовательских игр с неполной информацией.
Путем использования динамической структуры графа, обновляющейся в реальном времени, GRATR решает ограничения существующих методов, предлагая более точное и эффективное решение для принятия решений в реальном времени. Экспериментальные результаты подчеркивают превосходную производительность GRATR, особенно в улучшении рассуждения LLM, смягчая проблемы, такие как галлюцинации. Этот вклад готов оказать существенное влияние на исследования в области ИИ, особенно в областях, требующих надежной оценки доверия в реальном времени, таких как автономные системы и стратегические игровые среды.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit с более чем 50 тыс. участников.
Вот рекомендуемый вебинар от нашего спонсора: «Разблокируйте потенциал ваших данных Snowflake с помощью LLM».
Источник: MarkTechPost
«`




















