
«`html
Text-to-video generation: преимущества и практические решения
Генерация видео по тексту находится в процессе быстрого развития благодаря значительным достижениям в архитектурах трансформеров и моделях диффузии. Эти технологии открывают потенциал преобразования текстовых подсказок в когерентный, динамичный видеоконтент, создавая новые возможности в генерации мультимедийного контента.
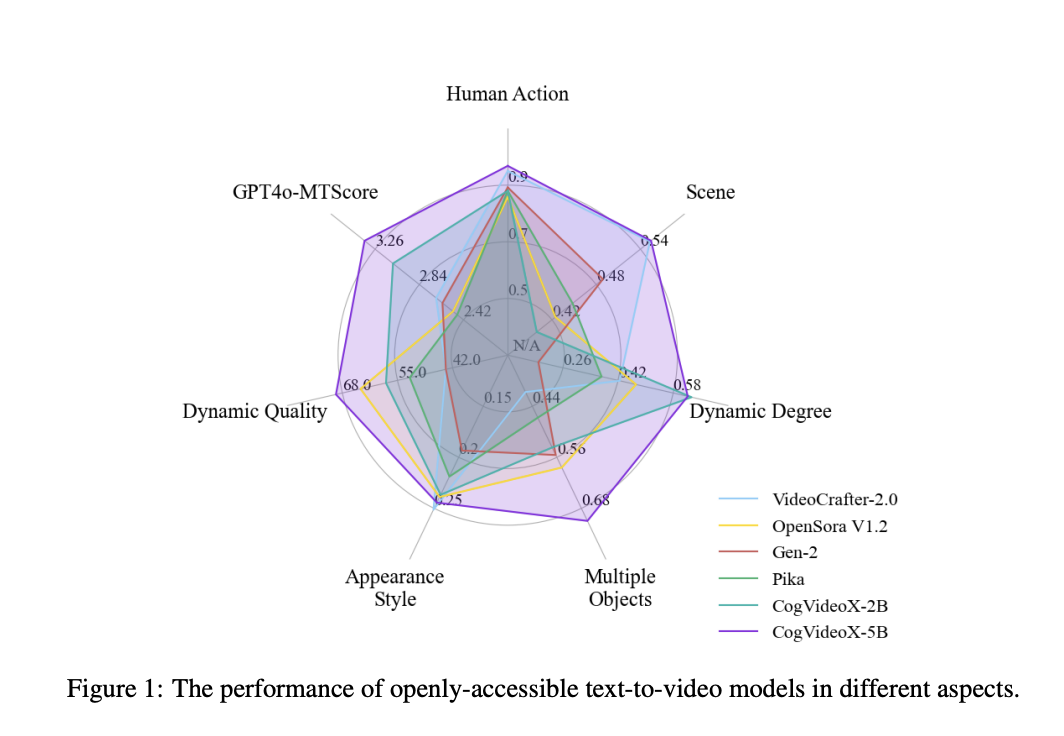
Основное преимущество CogVideoX заключается в создании высококачественных и семантически точных видеороликов, способных протягиваться на более длительные промежутки времени, чем было ранее возможно.
Решения для ключевых проблем
Для достижения временной согласованности в видео большой длительности, CogVideoX использует 3D causal VAE и экспертные трансформеры, обеспечивая сжатие видеоданных по пространственным и временным измерениям, существенно снижая вычислительную нагрузку при сохранении качества видео.
Модель также интегрирует экспертный трансформер с адаптивным LayerNorm, что улучшает согласование между текстом и видео, обеспечивая более гармоничное взаимодействие этих двух модальностей. Это позволяет генерировать высококачественные видеоролики, точно передающие семантику вводных текстов.
Инновационные техники CogVideoX
3D causal VAE позволяет сжимать видеоданные с соотношением 4×8×8, сохраняя непрерывность и качество видео. Экспертный трансформер использует механизм полного внимания 3D, обеспечивая всестороннее моделирование видеоданных для достоверного отображения крупномасштабных движений.
Две варианты CogVideoX
Две варианты модели, CogVideoX-2B и CogVideoX-5B, предлагают различные возможности. 2B предназначен для сценариев с ограниченными вычислительными ресурсами, обеспечивая сбалансированный подход к генерации видео по тексту. 5B, напротив, представляет премиум-вариант, превосходящий в обработке сложной динамики видео и создании видеороликов с высоким уровнем детализации, подходящий для более требовательных приложений.
«`
… (rest of the text in HTML)




















