
«`html
Новый стандарт в искусственном интеллекте: Cerebras Introduces the World’s Fastest AI Inference
Компания Cerebras Systems установила новую планку в области искусственного интеллекта (ИИ) с запуском своего революционного решения для ИИ-вывода. Анонс предлагает беспрецедентную скорость и эффективность при обработке больших языковых моделей (LLM). Новое решение, названное Cerebras Inference, разработано для удовлетворения сложных и растущих потребностей приложений ИИ, особенно тех, которые требуют мгновенных ответов и выполнения сложных многоэтапных задач.
Беспрецедентная скорость и эффективность
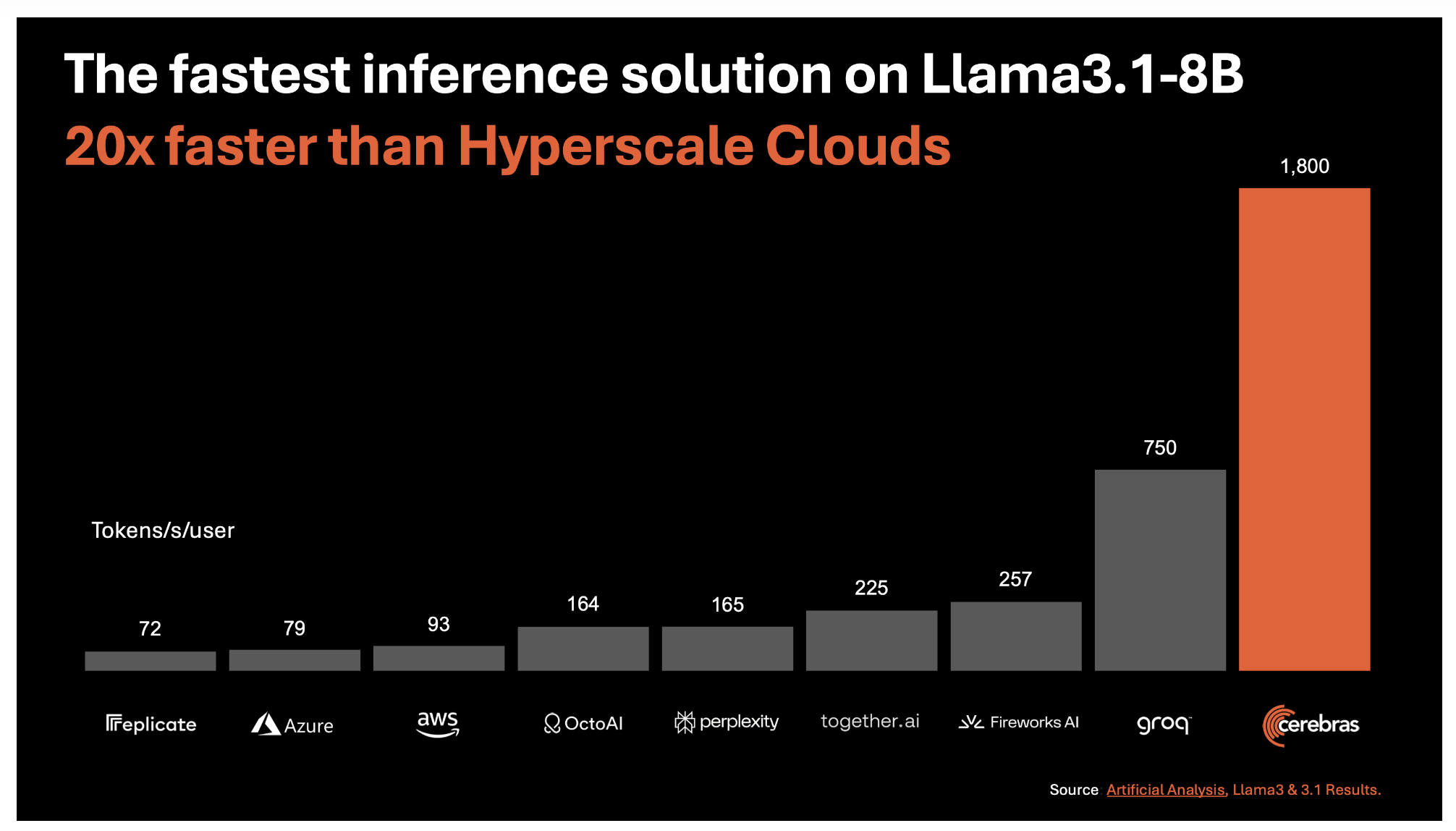
В основе Cerebras Inference лежит третьего поколения Wafer Scale Engine (WSE-3), который обеспечивает самое быстрое в мире решение для ИИ-вывода. Эта технология достигает удивительных 1,800 токенов в секунду для моделей Llama3.1 8B и 450 токенов в секунду для моделей Llama3.1 70B. Эти скорости примерно в 20 раз выше, чем у традиционных решений на основе GPU в облаке гипермасштабирования. Этот скачок производительности не только связан с чистой скоростью, но и стоит значительно меньше: цена составляет всего 10 центов за миллион токенов для модели Llama 3.1 8B и 60 центов за миллион токенов для модели Llama 3.1 70B.
Решение проблемы пропускной способности памяти
Одной из основных проблем в ИИ-выводе является необходимость огромной пропускной способности памяти. Традиционные системы на основе GPU часто нуждаются в помощи и требуют больших объемов памяти для обработки каждого токена в языковой модели. Cerebras преодолела этот узкий проход, непосредственно интегрировав огромные 44 ГБ SRAM на чип WSE-3, устраняя необходимость во внешней памяти и значительно увеличивая пропускную способность памяти. WSE-3 предлагает потрясающие 21 петабайт в секунду агрегированной пропускной способности памяти, в 7,000 раз больше, чем у GPU Nvidia H100. Этот прорыв позволяет Cerebras Inference легко обрабатывать большие модели, обеспечивая более быстрый и точный вывод.
Сохранение точности с 16-битной точностью
Еще одной ключевой особенностью Cerebras Inference является его стремление к точности. В отличие от некоторых конкурентов, которые снижают точность веса до 8 бит для достижения более высоких скоростей, Cerebras сохраняет исходную 16-битную точность на протяжении всего процесса вывода. Это гарантирует, что выходы модели будут максимально точными, что критически важно для задач, требующих высокой точности, таких как математические вычисления и сложные задачи рассуждения. По словам Cerebras, их модели с 16-битной точностью набирают до 5% больше в точности, чем их 8-битные аналоги, что делает их превосходным выбором для разработчиков, которым нужны и скорость, и надежность.
Стратегические партнерства и будущее расширение
Cerebras сосредотачивается не только на скорости и эффективности, но также строит крепкую экосистему вокруг своего решения для ИИ-вывода. Она сотрудничает с ведущими компаниями в отрасли ИИ, включая Docker, LangChain, LlamaIndex и Weights & Biases, чтобы предоставить разработчикам инструменты, необходимые для быстрой и эффективной разработки и развертывания приложений ИИ. Эти партнерства критически важны для ускорения развития ИИ и обеспечения доступа разработчиков к лучшим ресурсам.
Влияние на приложения ИИ
Последствия высокой скорости работы Cerebras Inference простираются далеко за пределы традиционных приложений ИИ. Путем значительного сокращения времени обработки Cerebras позволяет более сложные рабочие процессы ИИ и улучшает реальное время в LLM. Это может революционизировать отрасли, полагающиеся на ИИ, от здравоохранения до финансов, позволяя более быстрые и точные процессы принятия решений. Например, более быстрый вывод ИИ может привести к более своевременным диагнозам и рекомендациям по лечению в сфере здравоохранения, потенциально спасая жизни. Он может обеспечить анализ данных финансовых рынков в реальном времени, позволяя принимать более быстрые и информированные инвестиционные решения. Возможности бесконечны, и Cerebras Inference готов открывать новые возможности в приложениях ИИ в различных областях.
Заключение
Запуск самого быстрого в мире решения для ИИ-вывода от Cerebras Systems представляет собой значительный скачок вперед в технологии ИИ. Cerebras Inference готов переопределить возможности в области ИИ, объединяя беспрецедентную скорость, эффективность и точность. Инновации, подобные Cerebras Inference, будут играть ключевую роль в формировании будущего технологий. Будь то обеспечение реального времени в сложных приложениях ИИ или поддержка разработки моделей следующего поколения, Cerebras на передовой этого захватывающего путешествия.
«`



















