
«`html
Использование Loss-Free Balancing для оптимизации работы с искусственным интеллектом (ИИ)
Модели Mixture-of-experts (MoE) стали ключевым инновационным решением в машинном обучении, особенно в масштабировании больших языковых моделей (LLM). Эти модели разработаны для управления растущими вычислительными требованиями обработки огромных данных. Путем использования нескольких специализированных экспертов в одной модели архитектуры MoE можно эффективно направлять конкретные задачи к наиболее подходящему эксперту, оптимизируя производительность.
Проблема неравномерной нагрузки
Одним из значительных вызовов, с которыми сталкиваются модели MoE, является неравномерное распределение нагрузки среди экспертов. Некоторые эксперты могут перегружаться задачами, в то время как другие могут быть недостаточно задействованы, что приводит к неэффективности. Это неравновесие может привести к сбоям маршрутизации, что затрудняет общий процесс обучения. Кроме того, неравномерное распределение задач увеличивает вычислительные затраты, так как модели требуется помощь в эффективном управлении рабочей нагрузкой.
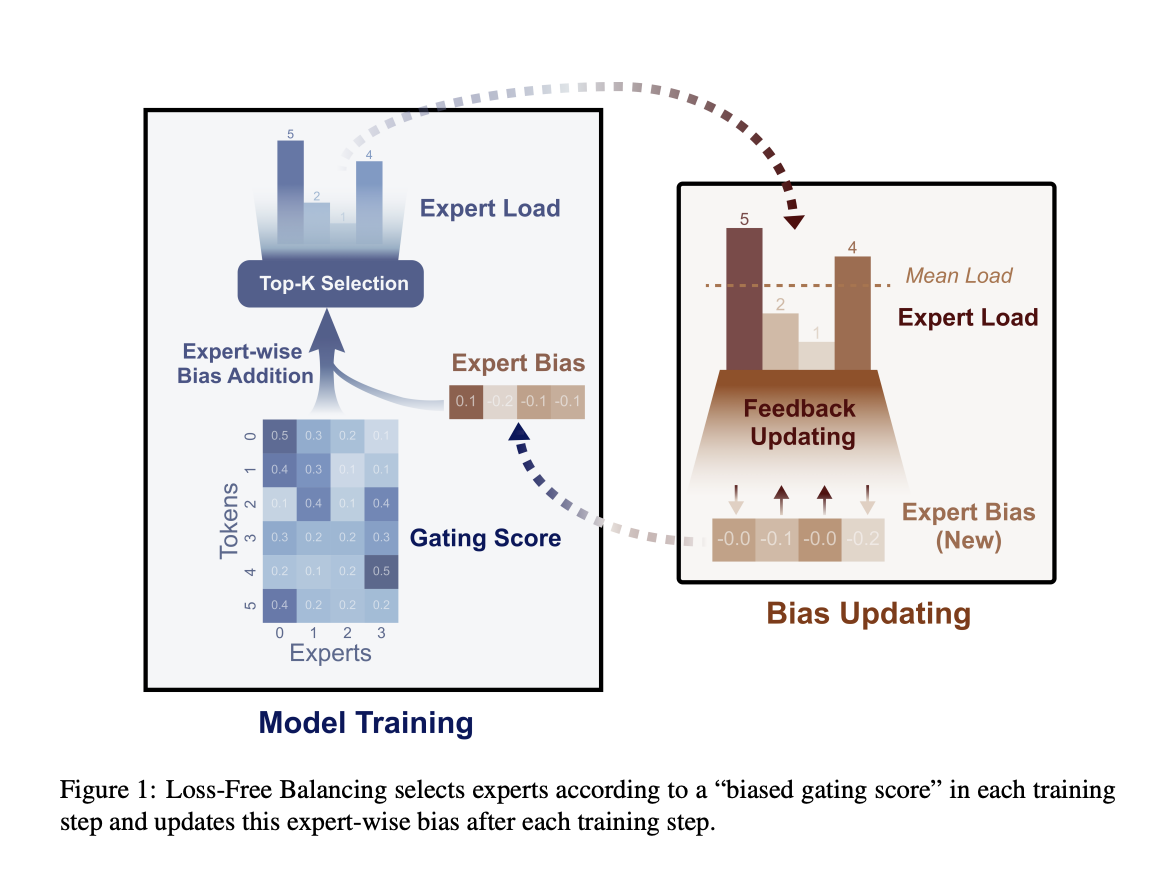
Решение проблемы
DeepSeek-AI и исследователи Университета Пекина разработали новый подход под названием Loss-Free Balancing. Этот метод устраняет необходимость вспомогательных функций потерь путем динамической настройки маршрутизации задач к экспертам на основе их текущей нагрузки. В отличие от предыдущих методов, которые вносили вредные градиенты, Loss-Free Balancing сосредотачивается на поддержании равномерного распределения задач без вмешательства в основные цели обучения модели. Этот подход позволяет модели работать более эффективно, обеспечивая эффективное использование всех экспертов без ущерба производительности.
Эмпирические результаты
Метод Loss-Free Balancing значительно улучшил традиционные стратегии с использованием вспомогательных функций потерь. В экспериментах на моделях MoE с 1 миллиардом (1B) параметров, обученных на 100 миллиардах (100B) токенов, и более крупных моделях с 3 миллиардами (3B) параметров, обученных на 200 миллиардах (200B) токенов, исследователи отметили значительные улучшения как в равномерности нагрузки, так и в общей производительности модели.
Loss-Free Balancing позволяет более эффективно и эффективно обучать крупномасштабные языковые модели, обеспечивая равномерное распределение нагрузки без вмешательства градиентов. Эмпирические результаты подтверждают потенциал этого подхода для улучшения производительности моделей MoE в различных областях применения.
Подробнее ознакомьтесь с исследованием.
Все заслуги за это исследование принадлежат исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашей группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
«`





















