
«`html
Alibaba представила Qwen2-VL: новейшую версию моделей визуально-языкового восприятия на основе Qwen2 в семействе моделей Qwen
Исследователи в Alibaba объявили о выпуске Qwen2-VL, последней версии моделей визуально-языкового восприятия на основе Qwen2 в семействе моделей Qwen. Эта новая версия представляет собой значительный прорыв в мультимодальных возможностях искусственного интеллекта, продолжая развитие, начатое предшественником Qwen-VL. Улучшения в Qwen2-VL открывают увлекательные возможности для широкого спектра приложений в области визуального восприятия и взаимодействия после года интенсивной разработки.
Основные возможности Qwen2-VL
Исследователи оценили визуальные возможности Qwen2-VL по шести ключевым измерениям: решение сложных задач уровня колледжа, математические способности, понимание документов и таблиц, мультиязычное понимание текста и изображений, ответы на общие сценарии, анализ видео и взаимодействие на основе агентов. Модель 72B продемонстрировала высокую производительность по большинству метрик, часто превосходя даже закрытые модели, такие как GPT-4V и Claude 3.5-Sonnet. Особенно Qwen2-VL проявила значительное преимущество в понимании документов, подчеркивая свою универсальность и продвинутые возможности обработки визуальной информации.
Источник изображения: https://qwenlm.github.io/blog/qwen2-vl/
Модель масштаба 7B
Модель Qwen2-VL масштаба 7B сохраняет поддержку изображений, мультиизображений и видеовходов, обеспечивая конкурентоспособную производительность в более экономичном размере. Эта версия отличается в задачах понимания документов, как продемонстрировано ее производительностью на бенчмарке DocVQA. Кроме того, модель проявляет впечатляющие возможности в мультиязычном понимании текста изображений, достигая передовой производительности на бенчмарке MTVQA. Эти достижения подчеркивают эффективность и универсальность модели в различных визуальных и лингвистических задачах.
Источник изображения: https://qwenlm.github.io/blog/qwen2-vl/
Компактная модель масштаба 2B
Также была представлена новая компактная модель Qwen2-VL масштаба 2B, оптимизированная для потенциального мобильного развертывания. Несмотря на свой небольшой размер, эта версия демонстрирует высокую производительность в понимании изображений, видео и мультиязычном понимании. Модель 2B особенно выделяется в задачах, связанных с видео, пониманием документов и ответами на общие сценарии по сравнению с другими моделями схожего масштаба. Это развитие показывает способность исследователей создавать эффективные модели высокой производительности, подходящие для ресурсоемких сред.
Источник изображения: https://qwenlm.github.io/blog/qwen2-vl/
Улучшения в Qwen2-VL
Qwen2-VL внедряет значительные улучшения в распознавании объектов, включая сложные многокомпонентные отношения и улучшенное распознавание рукописного текста и мультиязычное распознавание. Математические и программные навыки модели были значительно улучшены, что позволяет ей решать сложные задачи через анализ диаграмм и интерпретацию искаженных изображений. Извлечение информации из изображений и диаграмм в реальном мире было усилено, а также улучшены возможности следования инструкциям. Кроме того, Qwen2-VL теперь выделяется в анализе видеоконтента, предлагая суммирование, ответы на вопросы и возможности реального времени. Эти улучшения позиционируют Qwen2-VL как универсального визуального агента, способного связывать абстрактные концепции с практическими решениями в различных областях.
Источник изображения: https://qwenlm.github.io/blog/qwen2-vl/
Архитектура Qwen-VL для Qwen2-VL
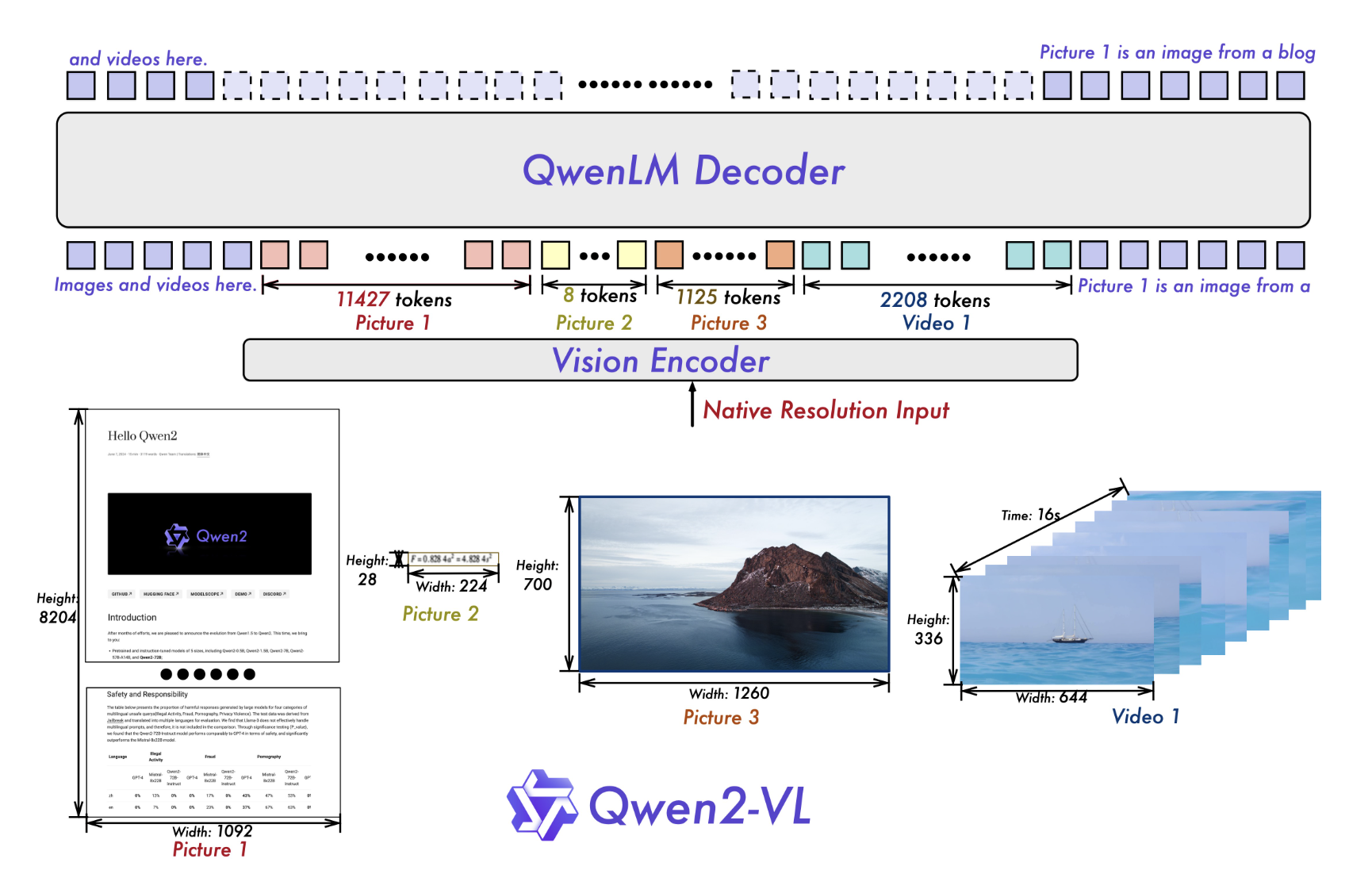
Alibaba сохраняет архитектуру Qwen-VL для Qwen2-VL, которая объединяет модель Vision Transformer (ViT) с языковыми моделями Qwen2. Все варианты используют ViT с примерно 600 миллионами параметров, способных обрабатывать как изображения, так и видеовходы. Ключевые улучшения включают в себя реализацию поддержки Naive Dynamic Resolution, позволяющую модели обрабатывать произвольные разрешения изображений, отображая их в динамическое количество визуальных токенов. Этот подход более точно имитирует визуальное восприятие человека. Кроме того, инновация Multimodal Rotary Position Embedding (M-ROPE) позволяет модели одновременно захватывать и интегрировать 1D текстовую, 2D визуальную и 3D видеопозиционную информацию.
Источник изображения: https://qwenlm.github.io/blog/qwen2-vl/
Заключение
Alibaba представила Qwen2-VL, новейшую модель визуально-языкового восприятия в семействе моделей Qwen, улучшая мультимодальные возможности искусственного интеллекта. Доступная в версиях 72B, 7B и 2B, Qwen2-VL выделяется в решении сложных задач, понимании документов, мультиязычном понимании текста и изображений, анализе видео, часто превосходя модели, такие как GPT-4V. Ключевые инновации включают улучшенное распознавание объектов, улучшенные математические и программные навыки, а также способность решать сложные визуальные задачи. Модель интегрирует Vision Transformer с поддержкой Naive Dynamic Resolution и Multimodal Rotary Position Embedding, делая ее универсальным и эффективным инструментом для различных приложений.
Проверьте карточку модели и детали. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и присоединиться к нашему Телеграм-каналу и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit с более чем 50 тысячами подписчиков.
Вот рекомендуемый вебинар от нашего спонсора: «Построение производительных приложений искусственного интеллекта с использованием NVIDIA NIMs и Haystack».
Опубликовано на сайте MarkTechPost.
Используйте Qwen2-VL для развития вашего бизнеса с помощью искусственного интеллекта
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Qwen2-VL. Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI. На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`




















