
«`html
Исследование и разработка модели Jina-ColBERT-v2: улучшение эффективности информационного поиска
Область информационного поиска (IR) стремительно развивается, особенно с интеграцией нейронных сетей, которые изменили способы извлечения и обработки данных. Нейронные системы поиска становятся все более важными, особенно те, которые используют плотные и многовекторные модели. Эти модели кодируют запросы и документы как высокоразмерные векторы, захватывая сигналы релевантности за пределами сопоставления ключевых слов, что позволяет более тонко настраивать процессы поиска. Однако с ростом спроса на многоязычные приложения становится более заметной проблема поддержания производительности и эффективности в различных языках. Это обстоятельство делает необходимым разработку моделей, которые не только надежны и точны, но также эффективны в работе с масштабными и разнообразными наборами данных без необходимости больших вычислительных ресурсов.
Проблема и решение
Одной из основных проблем в современной среде IR является баланс между производительностью модели и эффективностью ресурсов, особенно в многоязычных средах. Традиционные одновекторные модели, хотя и эффективны с точки зрения хранения и вычислений, часто нуждаются в большей способности обобщения на разные языки. Это ограничение особенно проблематично, поскольку все больше приложений требует возможности кросс-языкового поиска. Многовекторные модели, такие как ColBERT, предлагают решение, позволяя более детальные взаимодействия на уровне токенов, что может улучшить точность поиска. Однако эти модели имеют недостаток в виде увеличенных требований к хранению и вычислительным ресурсам, что делает их менее практичными для масштабных многоязычных приложений.
Одновекторные модели широко используются из-за своей простоты и эффективности. Они кодируют запрос или документ как один вектор, который затем используется для измерения релевантности по косинусной мере. Однако эти модели часто отстают в многоязычных контекстах, где необходимо учитывать более сложные лингвистические нюансы. Многовекторные модели, такие как оригинальный ColBERT, предлагают альтернативу, представляя запросы и документы как наборы меньших токенных вложений. Этот подход позволяет более детально взаимодействовать между токенами, улучшая способность модели к захвату релевантности в многоязычных средах. Несмотря на их преимущества, эти модели требуют значительно больше хранилища и вычислительной мощности, ограничивая их применимость в масштабных реальных сценариях.
Исследователи из Университета Техаса в Остине и Jina AI GmbH представили Jina-ColBERT-v2, усовершенствованную версию модели ColBERT, разработанную специально для решения текущих проблем. Эта новая модель включает несколько значительных улучшений, особенно в эффективной работе с многоязычными данными. Команда исследователей сосредоточилась на улучшении архитектуры и процесса обучения модели ColBERT. Для повышения эффективности вывода их подход включает использование модифицированной версии базовой модели XLM-RoBERTa, оптимизированной с помощью механизмов flash attention и rotary positional embeddings. Процесс обучения разделен на две стадии: начальную фазу масштабной контрастной настройки и более целевую фазу тонкой настройки с контролируемой дистилляцией. Эти улучшения позволяют Jina-ColBERT-v2 сократить требования к хранилищу до 50% по сравнению с предыдущими версиями, сохраняя при этом высокую производительность при выполнении различных задач поиска на английском и многоязычных языках.
Технологии и результаты
Технология, лежащая в основе Jina-ColBERT-v2, представляет собой сочетание нескольких передовых методик для повышения эффективности и эффективности информационного поиска. Одним из ключевых инноваций является использование нескольких линейных проекционных голов во время обучения, позволяющее модели выбирать различные размеры токенных вложений во время вывода с минимальной потерей производительности. Эта гибкость достигается через Matryoshka Representation Loss, позволяющий модели сохранять производительность даже при уменьшении размерности токенных вложений. Базовая модель Jina-XLM-RoBERTa включает механизмы flash attention и rotary positional embeddings, улучшающие ее производительность во время вывода. Эти технологические достижения улучшают способность модели обрабатывать многоязычные данные и делают ее более эффективной в хранении и вычислениях.
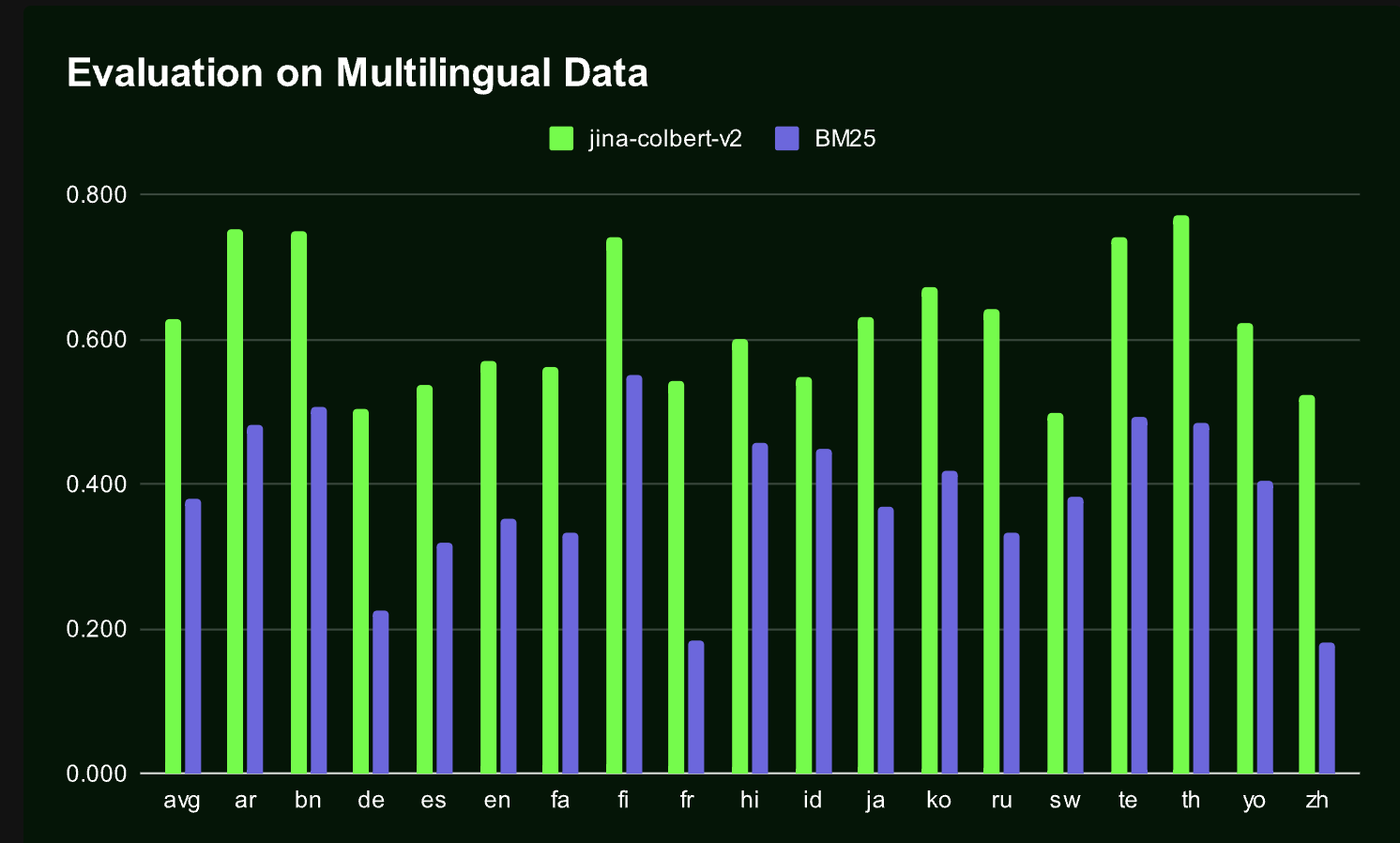
Производительность Jina-ColBERT-v2 была тщательно протестирована на нескольких бенчмарках, демонстрируя ее эффективность как в английском, так и в многоязычных контекстах. На бенчмарке BEIR Jina-ColBERT-v2 показала среднее улучшение в 6.6% по сравнению с ColBERTv2, подчеркивая ее превосходные возможности поиска. Модель также успешно справилась с бенчмарком LoTTE, сфокусированным на длиннохвостых запросах, продемонстрировав улучшение на 6.1% по сравнению с предыдущей версией. В задачах многоязычного поиска Jina-ColBERT-v2 превзошла существующие модели, такие как mDPR и ColBERT-XM, на нескольких языках, включая арабский, китайский и испанский. Способность модели обеспечивать высокую точность поиска при снижении требований к хранилищу до 50% делает ее значительным прорывом в информационном поиске. Эти результаты подчеркивают потенциал модели для реальных приложений, где производительность и эффективность имеют решающее значение.
Заключение
Модель Jina-ColBERT-v2 решает двойные вызовы поддержания высокой точности поиска при значительном снижении требований к хранилищу и вычислениям. Исследовательская команда создала мощную и эффективную модель, включающую передовые техники, такие как flash attention, rotary positional embeddings и Matryoshka Representation Loss. Улучшения производительности, продемонстрированные на различных бенчмарках, подтверждают потенциал модели для широкого применения в академических и промышленных средах. Jina-ColBERT-v2 является свидетельством непрерывного инновационного развития в области информационного поиска, предлагая многообещающее решение для будущего обработки многоязычных данных.
Посмотрите статью и API. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и присоединиться к нашему Телеграм-каналу и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Вот рекомендуемый вебинар от нашего спонсора: «Построение производительных приложений ИИ с помощью NVIDIA NIMs и Haystack».
Опубликовано на MarkTechPost.
«`




















