
«`html
Интеграция передовых прогностических моделей в системы автономного вождения становится ключевым фактором для повышения безопасности и эффективности.
Камеры, основанные на видеопрогнозировании, становятся решающим компонентом, предлагая богатые данные из реального мира. Содержание, созданное искусственным интеллектом, в настоящее время является ведущей областью исследований в области компьютерного зрения и искусственного интеллекта. Однако создание фотореалистичных и согласованных видеороликов представляет существенные трудности из-за ограниченной памяти и времени вычислений. Кроме того, прогнозирование видео с передней камеры является критическим для систем помощи водителю в автономных транспортных средствах.
Существующие подходы включают диффузионные архитектуры, которые стали популярными для генерации изображений и видеороликов, обладая лучшей производительностью в задачах, таких как генерация изображений, редактирование и перевод. Другие методы, такие как генеративно-состязательные сети (GAN), модели на основе потока, авторегрессионные модели и вариационные автокодировщики (VAE), также использовались для генерации и прогнозирования видео. Модели вероятностной диффузии для удаления шума (DDPM) превосходят традиционные модели генерации по эффективности. Однако генерация длинных видеороликов по-прежнему требует больших вычислительных ресурсов. Хотя авторегрессионные модели, такие как Phenaki, решают эту проблему, они часто сталкиваются с трудностями в реалистичных переходах сцен и несоответствиями в более длинных последовательностях.
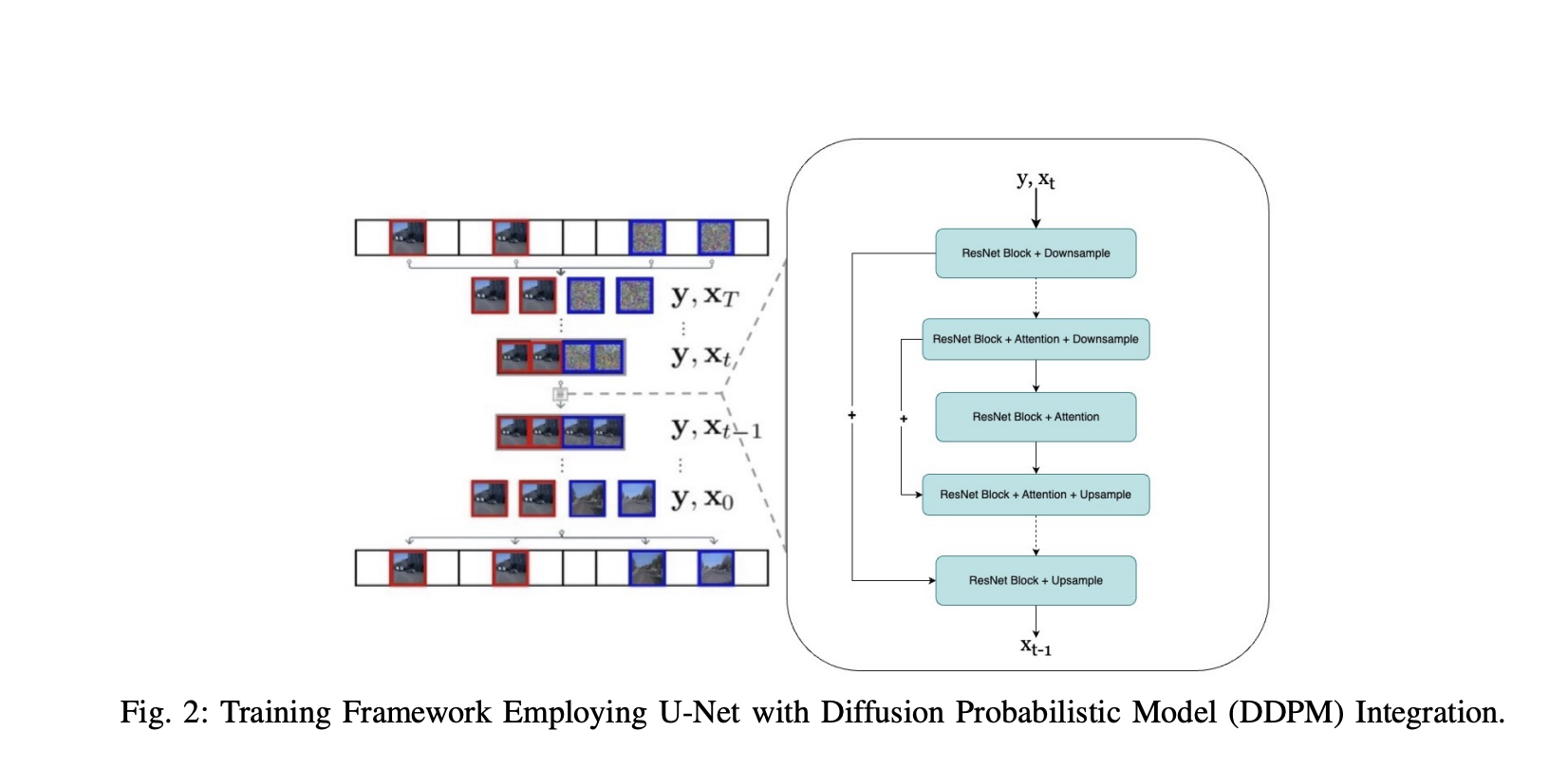
Команда исследователей из Колумбийского университета в Нью-Йорке предложила рамочную модель DriveGenVLM для генерации видеороликов вождения и использовала модели видео-языка (VLM) для их понимания. Рамочная модель использует подход генерации видео на основе моделей вероятностной диффузии для удаления шума (DDPM) для прогнозирования видеопоследовательностей из реального мира. Преобученная модель под названием Efficient In-context Learning on Egocentric Videos (EILEV) используется для оценки адекватности сгенерированных видеороликов для VLM. EILEV также предоставляет нарративы для этих сгенерированных видеороликов, потенциально улучшая понимание сцен дорожного движения, помогая в навигации и улучшая планирование в автономном вождении.
Рамочная модель DriveGenVLM проходит проверку на наборе данных Waymo Open Dataset, который предоставляет разнообразные сценарии вождения из реального мира из нескольких городов. Набор данных разделен на 108 видеороликов для обучения, равномерно распределенных между тремя камерами, и 30 видеороликов для тестирования (по 10 на каждую камеру). Эта рамочная модель использует метрику Frechet Video Distance (FVD) для оценки качества сгенерированных видеороликов, где FVD измеряет сходство распределений сгенерированных и реальных видеороликов. Эта метрика ценна для оценки временной согласованности и визуального качества, делая ее эффективным инструментом для оценки моделей синтеза видео в задачах, таких как генерация видео и прогнозирование будущих кадров.
Результаты рамочной модели DriveGenVLM на наборе данных Waymo Open Dataset для трех камер показывают, что адаптивный метод выборки иерархии-2 превосходит другие методы выборки, обеспечивая наименьшие оценки FVD. Прогнозируемые видеоролики генерируются для каждой камеры с использованием этого превосходного метода выборки, где каждый пример зависит от первых 40 кадров, с реальными кадрами и прогнозируемыми кадрами. Кроме того, обучение гибкой модели диффузии на наборе данных Waymo показывает ее способность к генерации согласованных и фотореалистичных видеороликов. Однако она по-прежнему сталкивается с трудностями в точном интерпретировании сложных сцен реального вождения, таких как движение по дороге и встреча с пешеходами.
В заключение, исследователи из Колумбийского университета представили рамочную модель DriveGenVLM для генерации видеороликов вождения. DDPM, обученная на наборе данных Waymo, профессионально генерирует согласованные и реалистичные изображения с передних и боковых камер. Кроме того, предварительно обученная модель EILEV используется для создания нарративов о действиях в видеороликах. Рамочная модель DriveGenVLM подчеркивает потенциал интеграции генеративных моделей и VLM для задач автономного вождения. В будущем описания сцен вождения, сгенерированные этой моделью, могут использоваться в больших языковых моделях для предложения помощи водителям или поддержки алгоритмов на основе языковых моделей.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и LinkedIn. Присоединяйтесь к нашему Telegram-каналу.
Если вам понравилась наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit.
Попробуйте AI Sales Bot здесь. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
Если вам нужны советы по внедрению ИИ, пишите нам на сюда. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
«`




















