
«`html
Классификация текста: практические решения и ценность
Применение моделей обработки естественного языка (NLP) в политической науке
Классификация текста стала важным инструментом в различных областях, включая анализ мнений и классификацию тем. Традиционно для этой задачи требовалась обширная ручная разметка и глубокое понимание техник машинного обучения, что создавало значительные барьеры для вхождения. Однако появление больших языковых моделей (LLM), таких как ChatGPT, революционизировало эту область, позволяя классифицировать тексты без дополнительного обучения. Этот прорыв привел к широкому применению LLM в политических и социальных науках.
Однако исследователи сталкиваются с вызовами при использовании этих моделей для анализа текста. Многие высокопроизводительные LLM являются собственностью и закрытыми, не обладая прозрачностью в своих обучающих данных и исторических версиях. Эта неопределенность противоречит принципам открытой науки. Кроме того, значительные вычислительные затраты и издержки на использование LLM могут сделать обширную разметку данных чрезмерно дорогой. В результате возникает растущий призыв исследователям отдавать предпочтение открытым моделям и обосновывать свой выбор закрытых систем.
Естественная языковая инференция (NLI) выделяется как универсальная классификационная структура, предлагая альтернативу генеративным моделям LLM для задач анализа текста. В NLI «предложение» документа сопоставляется с «гипотезой», и модель определяет, является ли гипотеза истинной на основе предложения. Такой подход позволяет одной модели, обученной в NLI, функционировать как универсальный классификатор по различным измерениям без дополнительного обучения.
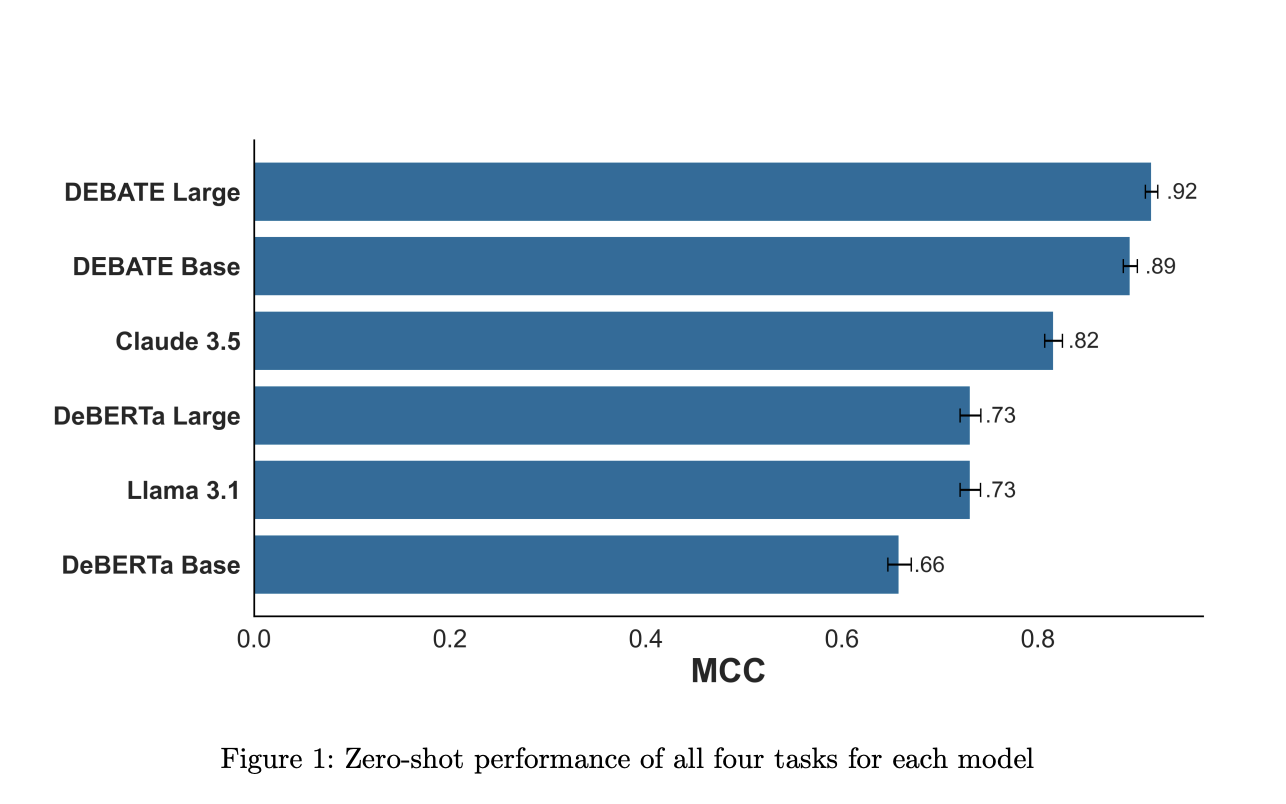
Исследователи из различных университетов предлагают модели Political DEBATE (DeBERTa Algorithm for Textual Entailment), представляющие собой значительное совершенствование открытой классификации текста для политической науки. Эти модели, с 304 миллионами и 86 миллионами параметров, способны выполнять классификацию политического текста с эффективностью, сравнимой с гораздо более крупными закрытыми моделями. Модели Political DEBATE достигают высокой производительности благодаря двум ключевым стратегиям: областно-специфическому обучению с тщательно подобранными данными и использованию классификационной структуры NLI.
Модели Political DEBATE обучены на наборе данных PolNLI, включающем более 200 000 размеченных политических документов, охватывающих различные подобласти политической науки. Этот набор данных извлечен из разнообразных источников, включая социальные медиа, новостные статьи, конгрессуальные информационные бюллетени, законодательство и ответы сообщества. Он также включает адаптированные версии утвержденных академических наборов данных. Важно отметить, что подавляющее большинство текста в PolNLI создано людьми, и лишь небольшая часть (1363 документа) сгенерирована LLM.
Модели Political DEBATE построены на базе моделей DeBERTa V3 с использованием библиотеки Transformers. Они были протестированы на различных классификационных задачах и типах документов, чтобы обеспечить надежность и стабильность. Кроме того, модели были протестированы на их устойчивость к незначительным лингвистическим изменениям.
Модели Political DEBATE продемонстрировали впечатляющую эффективность в обучении с небольшим числом образцов, превзойдя производительность специализированных классификаторов и крупных генеративных моделей. Они также показали значительное преимущество в скорости обработки по сравнению с другими моделями на различных типах оборудования.
Используйте AI для развития своего бизнеса! Присоединяйтесь к нам в Telegram и Twitter, чтобы быть в курсе последних новостей в области искусственного интеллекта.
«`





















