
Улучшение Больших Языковых Моделей с Разнообразными Инструкционными Данными: Подход на Основе Кластеризации и Итеративного Совершенствования
Большие языковые модели (LLM) стали ключевой частью искусственного интеллекта, позволяя системам понимать, генерировать и отвечать на человеческий язык. Эти модели используются в различных областях, включая рассуждения на естественном языке, генерацию кода и решение проблем. LLM обычно обучаются на огромных объемах неструктурированных данных из интернета, что позволяет им развивать широкое понимание языка. Однако для улучшения их специфичности для задач необходима настройка. Настройка включает использование инструкционных наборов данных, состоящих из структурированных пар вопрос-ответ. Этот процесс является важным для улучшения способности моделей выполнять точные действия в реальных приложениях.
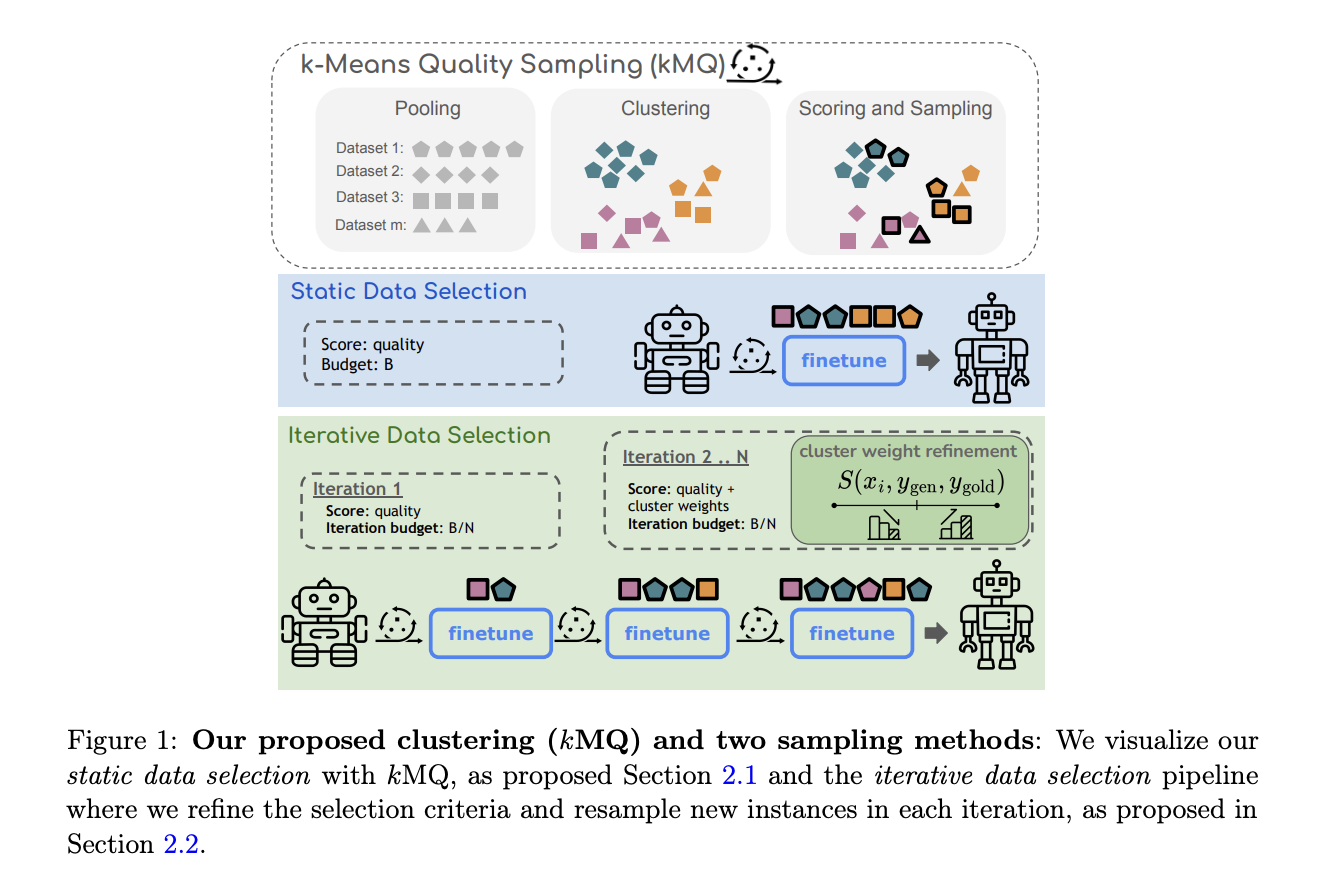
Выбор Оптимального Набора Данных
Выбор подмножества данных из огромных наборов представляет собой ключевую задачу для исследователей: эффективно выбирать данные, улучшающие обучение модели, не истощая вычислительные ресурсы. Проблема заключается в том, что некоторые данные вносят более значительный вклад в процесс обучения, чем другие. Для предотвращения переобучения на конкретные области необходимо добиться баланса между качеством и разнообразием данных. Приоритизация разнообразия в обучающих данных обеспечивает эффективную обобщенность модели по различным задачам.
Инновационный Метод Кластеризации и Итеративного Совершенствования
Исследователи из Норт-Вестернского Университета, Стэнфордского Университета, Google Research и Cohere For AI представили инновационный метод итеративного совершенствования для преодоления этих препятствий. Их подход подчеркивает выбор данных, ориентированный на разнообразие, с использованием кластеризации k-средних. Этот метод гарантирует, что выбранное подмножество данных более точно отражает полный набор данных. Исследователи предлагают процесс итеративного совершенствования, вдохновленный техниками активного обучения, который позволяет модели повторно выбирать экземпляры из кластеров во время обучения. Этот итеративный подход обеспечивает постепенное фильтрование кластеров, содержащих данные низкого качества или выбросы, делая упор на разнообразные и репрезентативные точки данных. Метод направлен на баланс между качеством и разнообразием, обеспечивая, что модель не становится предвзятой к определенным категориям данных.
Эффективность Метода
Эффективность этого метода была тщательно протестирована на нескольких задачах, включая вопросно-ответные системы, рассуждения, математику и генерацию кода. Результаты были значительными: метод выборки kMQ привел к улучшению производительности на 7% по сравнению с случайным выбором данных и на 3.8% по сравнению с передовыми методами, такими как Deita и QDIT. На таких задачах, как HellaSwag, проверяющих здравый смысл, модель достигла точности 83.3%, в то время как в GSM8k, модель повысила точность с 14.5% до 18.4% с использованием итеративного процесса kMQ. Это продемонстрировало эффективность выборки с учетом разнообразия в улучшении обобщения модели по различным задачам.
Метод исследователей превзошел предыдущие эффективные техники существенным повышением производительности. В отличие от более сложных процессов, которые полагаются на большие языковые модели для оценки и фильтрации данных, kMQ достигает конкурентоспособных результатов без затратных вычислительных ресурсов. Используя простой алгоритм кластеризации и итеративное совершенствование, процесс масштабируем и доступен, что делает его подходящим для различных моделей и наборов данных. Этот метод особенно полезен для исследователей, работающих с ограниченными ресурсами, но стремящихся достичь высокой производительности при обучении LLM.
Заключение
Данное исследование решает одну из наиболее значительных проблем в обучении больших языковых моделей: выбор высококачественного и разнообразного подмножества данных, максимизирующего производительность по различным задачам. Представляя кластеризацию k-средних и итеративное совершенствование, исследователи разработали эффективный метод, балансирующий разнообразие и качество при выборе данных. Их подход приводит к улучшению производительности до 7% и обеспечивает обобщение моделей по широкому спектру задач.
Посмотрите статью и GitHub. Вся признательность за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 50k+ ML SubReddit
FREE AI WEBINAR: ‘SAM 2 для видео: как настраивать на ваши данные’ (Ср, 25 сентября, 4:00 – 4:45 EST)
Пост вперед: MarkTechPost
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Enhancing Large Language Models with Diverse Instruction Data: A Clustering and Iterative Refinement Approach.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на itinai. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!