
Оценка надежности крупных языковых моделей (LLM) и их применение в различных областях
Ценность и практические решения
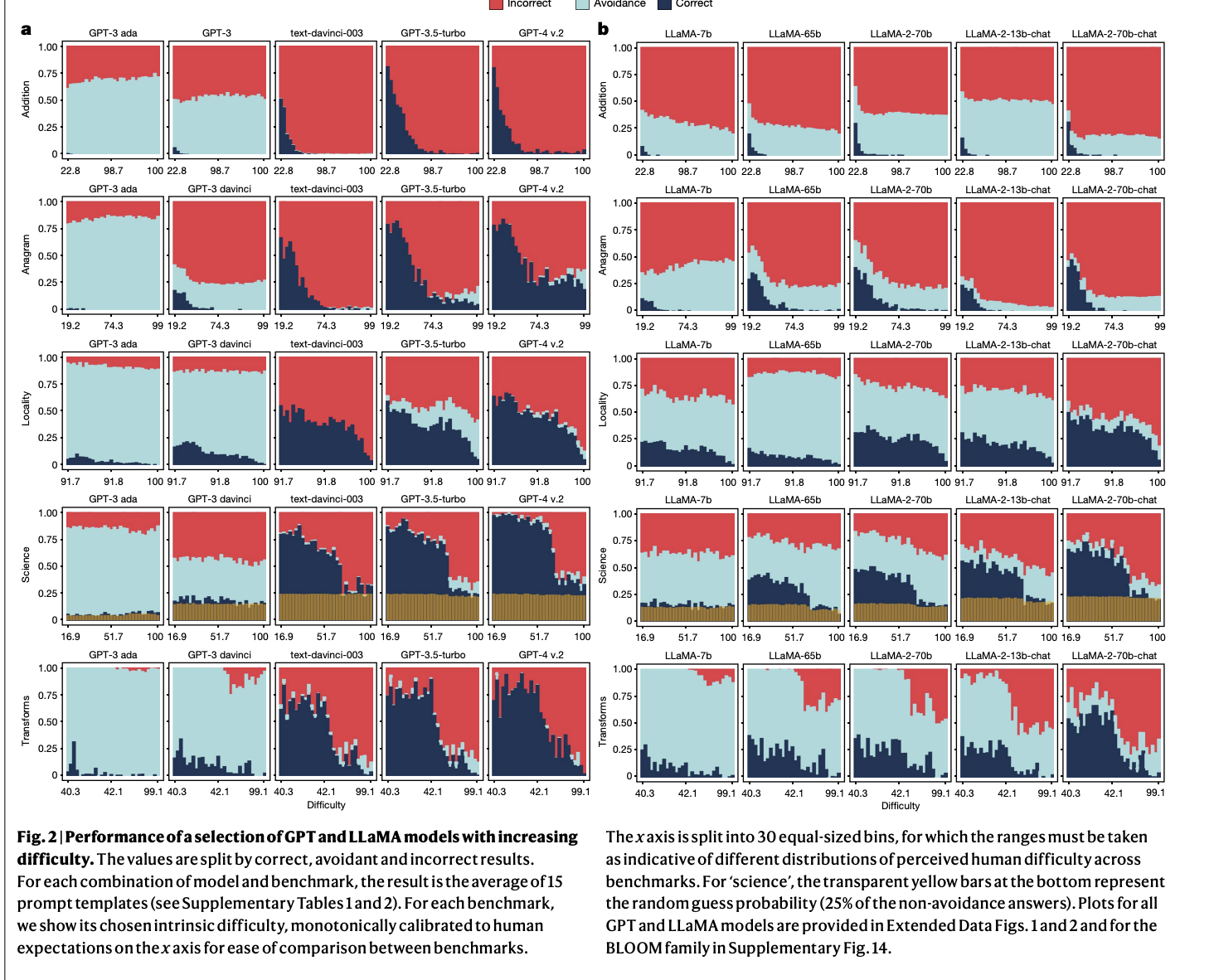
Исследование показывает, что увеличение размеров LLM, таких как GPT, LLaMA и BLOOM, не всегда повышает их надежность. Это может привести к неправильным результатам даже в простых задачах, что подчеркивает необходимость более глубокого анализа надежности этих моделей.
Проблема заключается в том, что, увеличивая мощность LLM, мы сталкиваемся с неожиданными поведенческими шаблонами, что ухудшает их надежность на простых задачах. Для решения этой проблемы предложены методики масштабирования и формирования моделей.
Исследователи предложили фреймворк ReliabilityBench для систематической оценки надежности LLM в пяти областях, что помогает выявить их сильные и слабые стороны.
Полученные результаты показывают, что увеличение размеров моделей и формирование их поведения улучшают производительность на сложных вопросах, но могут ухудшить надежность на простых задачах.
Исследование подчеркивает необходимость изменения подхода к разработке LLM и предлагает использовать фреймворк ReliabilityBench для более глубокой оценки их надежности.
Технологические решения для вашего бизнеса
Используйте ReliabilityBench для оценки производительности LLM и определения областей применения их в вашем бизнесе.
Выберите подходящее решение в области искусственного интеллекта и внедряйте его постепенно, начиная с малых проектов и анализируя результаты.
Следите за новостями о ИИ на наших платформах и попробуйте AI Sales Bot для автоматизации работы с клиентами.
Обращайтесь за советами по внедрению ИИ и изучайте, как AI Lab может изменить ваши бизнес-процессы.





















