
Улучшение эффективности вывода LLM в многоязычных средах
Практические решения и ценность
Обработка естественного языка (NLP) сейчас находится на новом уровне благодаря появлению крупных языковых моделей (LLM), которые применяются в различных приложениях, таких как генерация текста, перевод и разговорные агенты. Эти модели способны обрабатывать и понимать человеческие языки на невиданном уровне, обеспечивая беспрепятственное взаимодействие между машинами и пользователями.
Однако при развертывании этих моделей на нескольких языках возникают значительные проблемы из-за требуемых вычислительных ресурсов. Сложность мультиязычных сред, включающая разнообразные языковые структуры и различия в словарном запасе, дополнительно усложняет эффективное развертывание LLM в практических приложениях.
Одной из основных проблем при развертывании LLM в мультиязычных контекстах является высокое время вывода. Это время увеличивается значительно в мультиязычных средах из-за различий в токенизации и размерах словарей между языками, приводя к изменениям в длине кодирования.
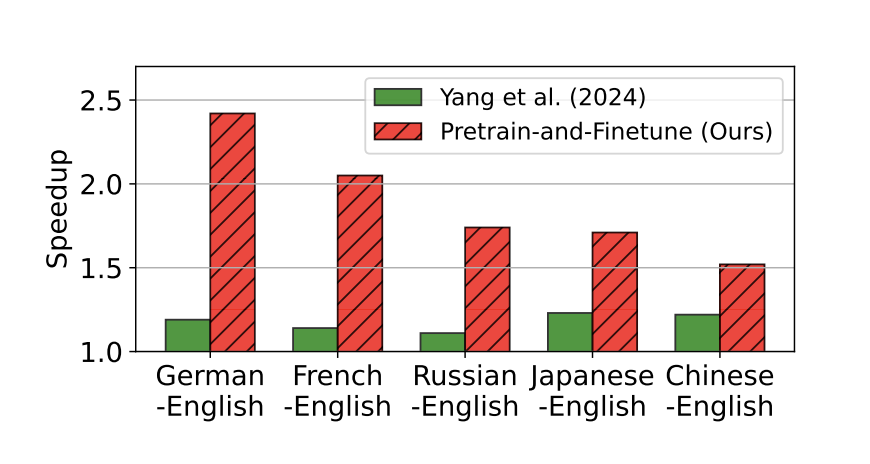
Исследователи из KAIST AI и KT Corporation представили инновационный подход к мультиязычному спекулятивному декодированию, используя стратегию предварительного обучения и донастройки. Подход начинается с предварительного обучения моделей-черновиков с использованием мультиязычных наборов данных для общей задачи языкового моделирования. Затем модели донастраиваются для каждого конкретного языка, чтобы лучше соответствовать прогнозам целевых LLM. Этот двухэтапный процесс позволяет черновикам специализироваться в обработке уникальных характеристик каждого языка, что приводит к более точным начальным черновикам.
Предложенная методология включает три этапа, известных как парадигма черновика-проверки-принятия. Во время начального этапа «черновик» модель-черновик генерирует потенциальные будущие токены на основе входной последовательности. Этап «проверка» сравнивает эти черновые токены с прогнозами, сделанными основным LLM, чтобы обеспечить согласованность. Если вывод черновика соответствует прогнозам LLM, токены принимаются; в противном случае они либо отбрасываются, либо исправляются, и цикл повторяется.
Результаты показали значительное ускорение времени вывода и повышение производительности при применении метода к мультиязычным задачам перевода. Эти результаты подтверждают, что целенаправленное предварительное обучение и донастройка для черновиков могут быть более эффективными, чем простое увеличение размера модели, устанавливая новую планку для практического развертывания LLM в разноязычных средах.




















