
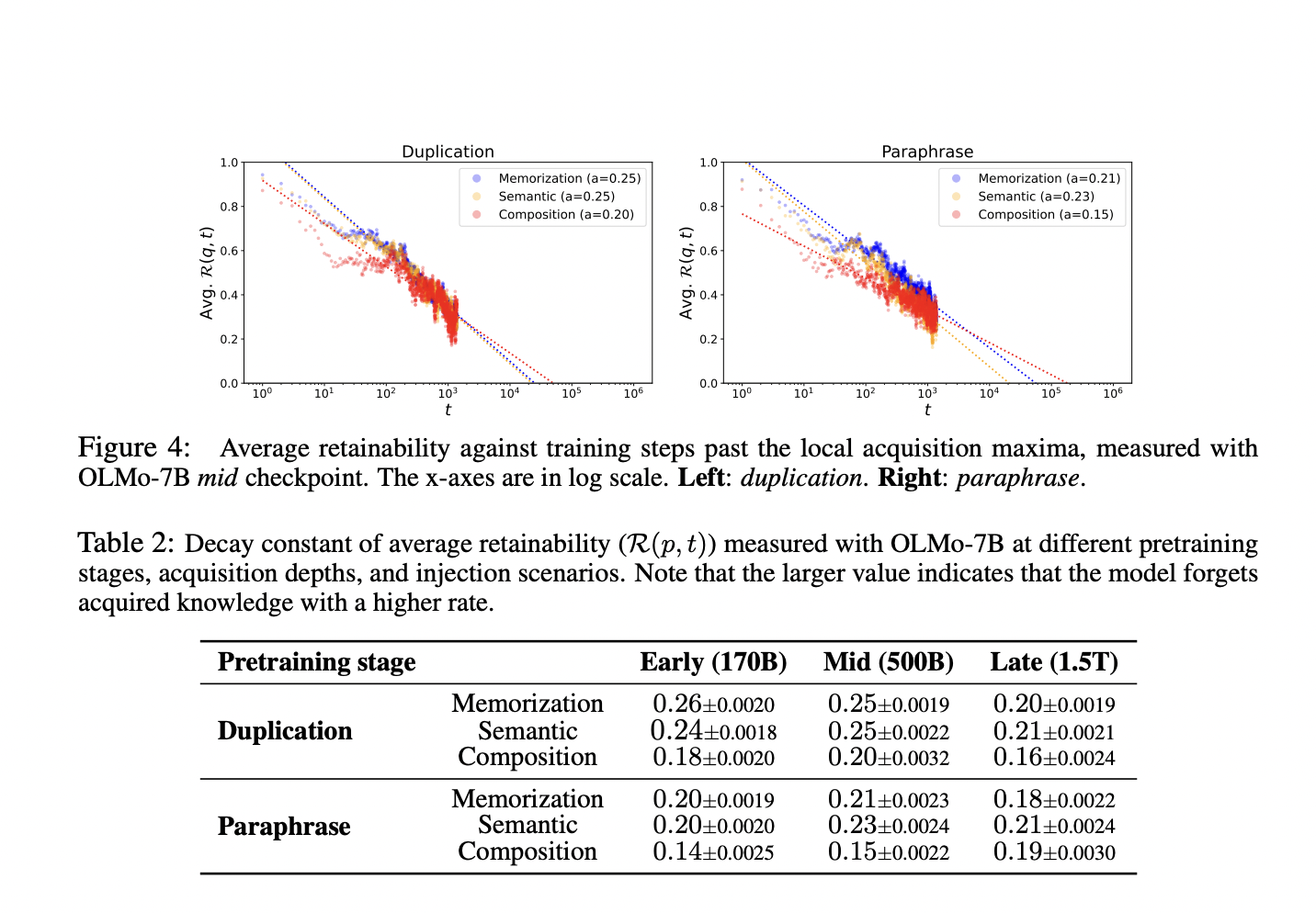
Исследование о приобретении и сохранении фактических знаний в больших языковых моделях
Проблема
Большие языковые модели (LLM) имеют сложности с сохранением фактических знаний во время обучения. Это влияет на их способность обобщать информацию и применять ее в различных сценариях.
Решение
Для улучшения сохранения фактических знаний в LLM предлагаются следующие методы:
- Увеличение размера модели и обучающих наборов данных
- Использование продвинутых методов оптимизации
- Изменение размеров пакетов для более эффективной обработки данных
- Устранение дублирования данных для более эффективного обучения
Исследование
Исследователи из KAIST, UCL и KT предложили новый подход к изучению приобретения и сохранения фактических знаний в LLM. Они провели эксперимент, внедряя новые фактические знания в модель во время предварительного обучения. Анализируя способность модели запоминать и обобщать информацию, они выявили стратегии оптимизации обучения для улучшения долговременной памяти в LLM.
Выводы
Исследование показало, что увеличение размера модели и использование качественных данных, а не количества, способствует лучшему сохранению фактических знаний. Также выявлено, что модели, обученные с использованием дедупликации данных, более устойчивы к забыванию и лучше обобщают информацию.
Практическое применение
Оптимизация размера пакетов и качества данных в предварительной фазе обучения может значительно улучшить сохранение фактических знаний в LLM. Эти улучшения делают модели более надежными для различных задач, особенно при работе с менее распространенными знаниями.
Подробнее о исследовании можно узнать здесь.
Подписывайтесь на наш Telegram-канал и следите за новостями в Twitter @itinairu45358.




















