Преимущества использования Blockwise Parallel Decoding (BCD) в моделях языка
Практические решения для улучшения эффективности и плавности работы моделей языка
Недавние достижения в области авторегрессионных языковых моделей привели к удивительным изменениям в области обработки естественного языка (NLP). Модели, такие как GPT и другие, проявили отличную производительность в задачах создания текста, включая вопросно-ответные и суммарные задачи. Однако их высокая задержка вывода создает значительное препятствие для их общего применения, особенно в глубоких моделях с сотнями миллиардов параметров. Эта задержка обусловлена тем, что авторегрессионные модели генерируют текст по одному токену за раз в последовательности. Это приводит к значительному увеличению вычислительного спроса, что ограничивает возможность моделей быть задействованными в реальном времени.
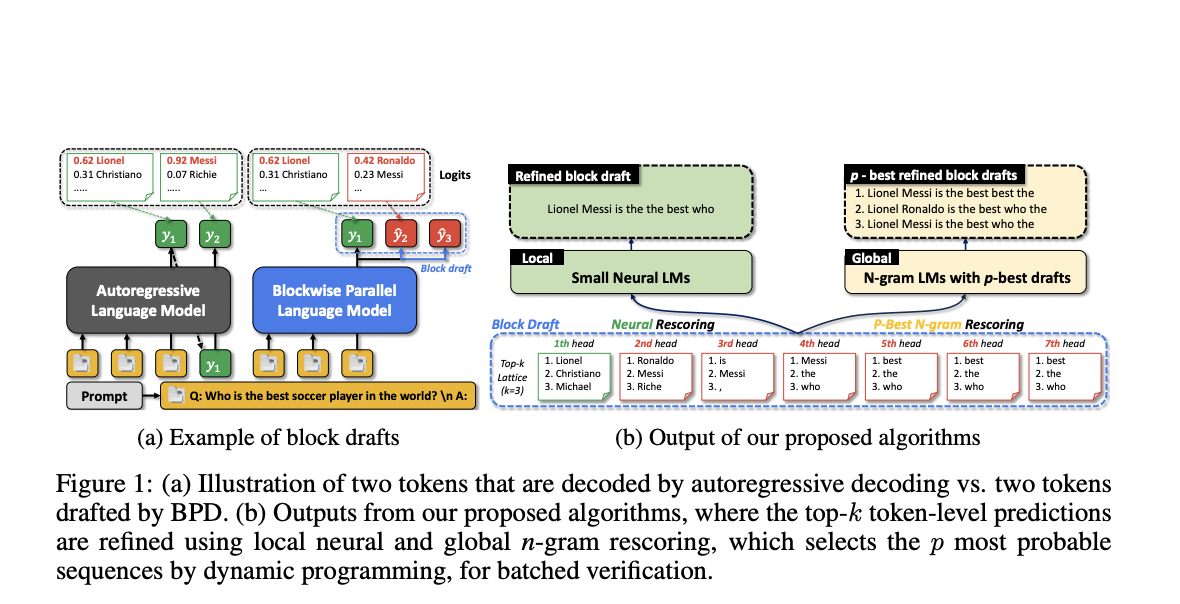
Для решения этой проблемы команда исследователей из KAIST и Google разработала метод Blockwise Parallel Decoding (BPD), предназначенный для ускорения вывода этих моделей. Известные как блочные черновики, BPD позволяет одновременное предсказание нескольких будущих токенов, в отличие от типичных авторегрессионных методов. Несколько голов предсказания параллельно создают эти блочные черновики, а затем авторегрессионная модель выбирает и условно принимает наилучшие токены.
Благодаря одновременному представлению нескольких токенов, эта техника значительно ускоряет скорость вывода, уменьшая время ожидания последовательных предсказаний токенов. Однако BPD имеет свой набор трудностей, особенно в обеспечении точности и хорошей организации блочных черновиков для их принятия моделью.
Команда предложила два ключевых способа, с помощью которых эффективность блочных черновиков была улучшена. Сначала были изучены распределения токенов, сгенерированные несколькими головами предсказания в BPD. Цель этого анализа — лучше понять, как модель одновременно генерирует несколько токенов и как оптимизировать эти предсказания для повышения плавности и точности. Анализируя эти распределения токенов, можно выявить тенденции или нерегулярности, которые могут повлиять на производительность блочных черновиков.
Во-вторых, используя этот исследовательский подход, были созданы алгоритмы, улучшающие блочные черновики. Команда предложила использовать нейронные языковые модели и n-граммные модели для улучшения качества блочных черновиков перед верификацией авторегрессионной моделью. В то время как нейронные языковые модели обеспечивают более сложное понимание контекста, что помогает сделать блочные черновики более соответствующими ожиданиям модели, n-граммные модели помогают гарантировать локальную согласованность в предсказаниях токенов.
Тестирование показало обнадеживающие результаты, с улучшенными блочными черновиками, увеличивающими эффективность блока, то есть количество токенов из блочного черновика, в конечном итоге принимаемых авторегрессионной моделью, на 5-21%. Эти улучшения были продемонстрированы на нескольких различных наборах данных, что указывает на устойчивость метода.




















