
Решение для улучшения работы больших языковых моделей
Проблема:
Большие языковые модели (LLM) показали значительные успехи в понимании и генерации естественного языка благодаря методам масштабируемого предварительного обучения и настройки. Однако основной вызов заключается в улучшении способностей LLM к логическому мышлению, особенно в сложных логических и математических задачах.
Решение:
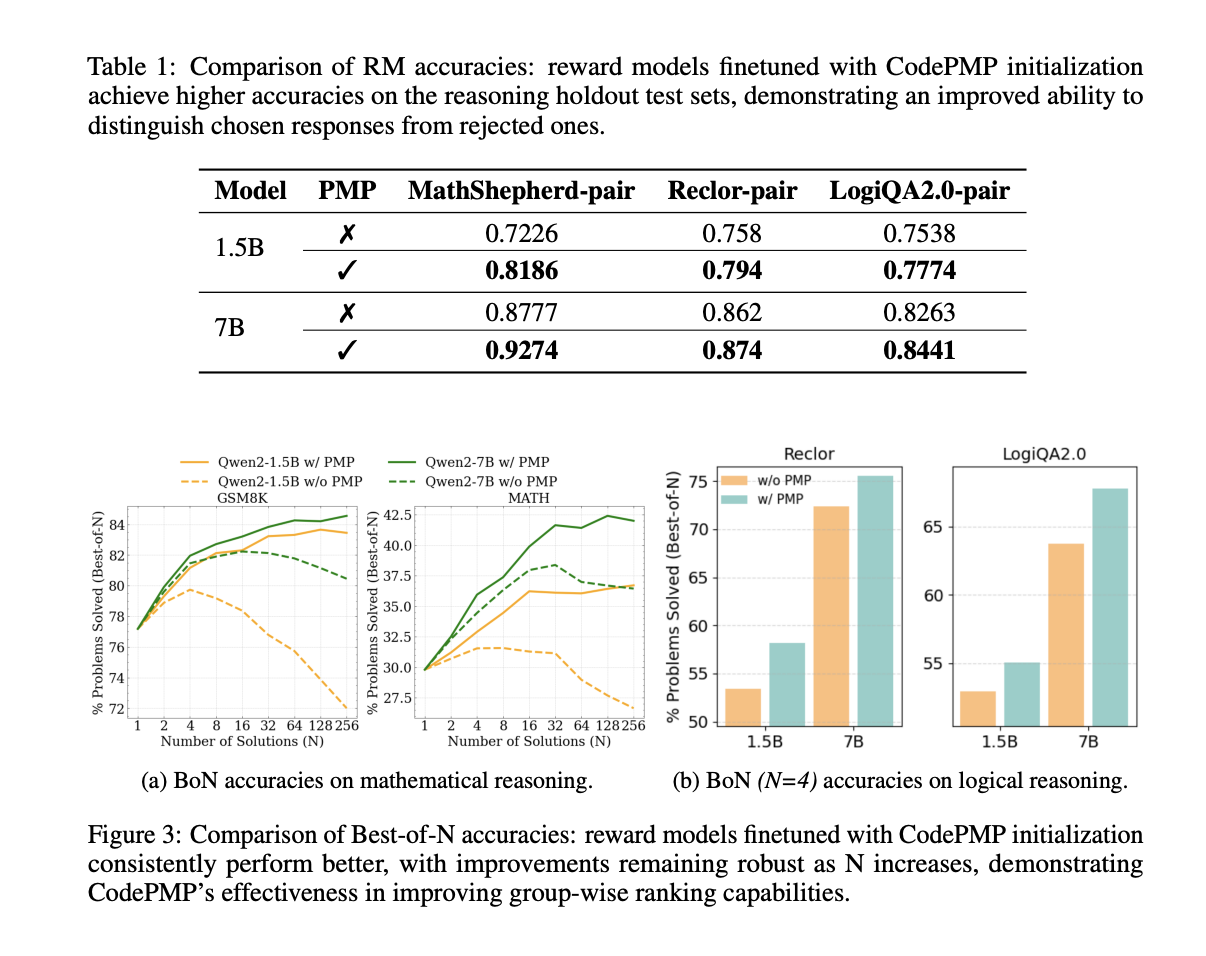
Компания Anthropic предлагает метод предварительного обучения моделей на основе предпочтений (PMP), который использует общедоступные масштабные наборы данных, такие как Reddit или Wikipedia, для предварительного обучения. Новый метод CodePMP генерирует масштабные данные на основе исходного кода, специально предназначенные для логических задач. Он автоматизирует создание данных предпочтения, значительно повышая эффективность и масштабируемость настройки наградных моделей.
Преимущества:
CodePMP демонстрирует значительное улучшение производительности в математическом и логическом мышлении. Модели, предварительно обученные с помощью CodePMP, показывают лучшие результаты в точности моделей и способности отличать правильные и неправильные рассуждения. Этот подход предоставляет эффективное и масштабируемое решение для улучшения способностей LLM в областях, требующих сложного логического мышления.





















