
«`html
SQ-LLaVA: Новый метод визуальной настройки инструкций для улучшения понимания языка и изображений
Большие модели, которые объединяют язык и изображение, становятся мощными инструментами для многомодального понимания. Они способны интерпретировать и генерировать контент, который сочетает визуальную и текстовую информацию. Однако создание качественных наборов данных для визуальных инструкций является сложной задачей.
Проблемы и решения
Качество и разнообразие наборов данных напрямую влияют на производительность модели. Исследователи разработали метод настройки инструкций, который позволяет языковым моделям интерпретировать и выполнять инструкции на разных задачах. Это улучшает работу моделей в реальных сценариях.
Инновации в интеграции языка и изображения
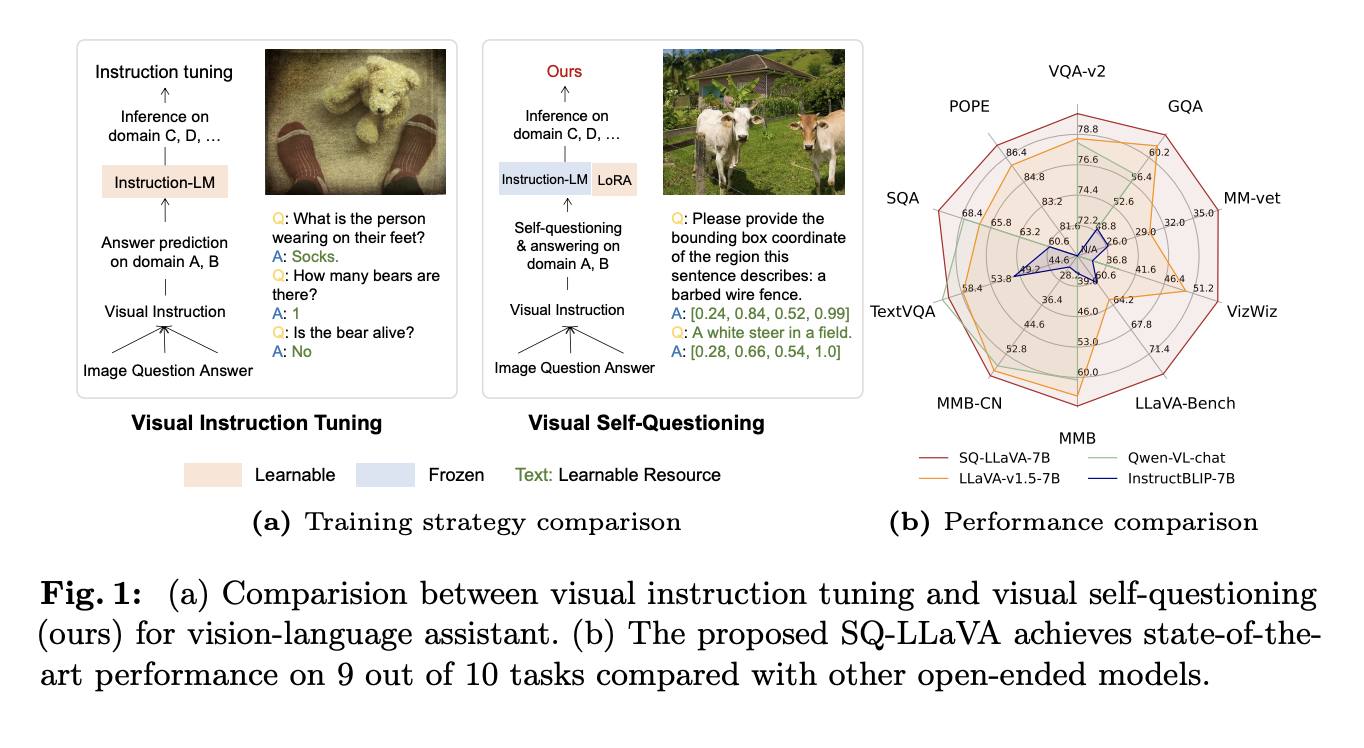
Модель SQ-LLaVA использует уникальный подход визуального само-вопроса, что позволяет улучшить понимание языка и изображения. Эта модель обучается задавать вопросы и находить визуальные подсказки без необходимости в дополнительных данных.
Ключевые компоненты модели
Архитектура SQ-LLaVA включает четыре основных компонента:
- Предобученный визуальный энкодер CLIP-ViT.
- Прототипный экстрактор для улучшения визуального представления.
- Обучаемый блок проекции, который сопоставляет визуальные токены с языковыми.
- Предобученная языковая модель Vicuna.
Достижения модели SQ-LLaVA
Модель SQ-LLaVA продемонстрировала значительные улучшения в различных задачах:
- Производительность: SQ-LLaVA-7B превзошла предыдущие методы на 17.2% по сравнению с LLaVA-v1.5-7B.
- Научное мышление: Улучшенные результаты на ScienceQA показывают сильные возможности в многопроходном рассуждении.
- Надежность: SQ-LLaVA-7B показала улучшения на 2% по сравнению с LLaVA-v1.5-7B.
- Масштабируемость: SQ-LLaVA-13B превзошла предыдущие работы в шести из десяти тестов.
- Открытие визуальной информации: Модель генерировала разнообразные и значимые вопросы о изображениях.
- Капшонирование изображений без обучения: Значительные улучшения по сравнению с базовыми моделями.
Практическое применение ИИ
Если вы хотите развивать свою компанию с помощью ИИ, используйте метод SQ-LLaVA. Определите, где можно применить автоматизацию, и выберите подходящее решение. Внедряйте ИИ постепенно, начиная с небольших проектов.
Если вам нужны советы по внедрению ИИ, пишите нам в Telegram. Следите за новостями о ИИ в нашем Telegram-канале или в Twitter.
Попробуйте AI Sales Bot, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab.
«`



















