
«`html
Введение в SuffixDecoding
Большие языковые модели (LLMs) стали основой современных приложений. Однако, быстрое генерирование токенов остается сложной задачей, что замедляет развитие новых приложений. Например, системы, использующие многопоточность, часто сталкиваются с долгими временами отклика из-за ожидания обработки. Ускорение генерации токенов критически важно для дальнейшего распространения приложений на базе LLM.
Проблемы существующих методов
Существующие методы декодирования имеют ограничения:
- Они зависят от качества начальной модели, что требует затрат на обучение.
- Интеграция моделей может привести к неэффективности и конфликтам в использовании памяти.
Решение SuffixDecoding
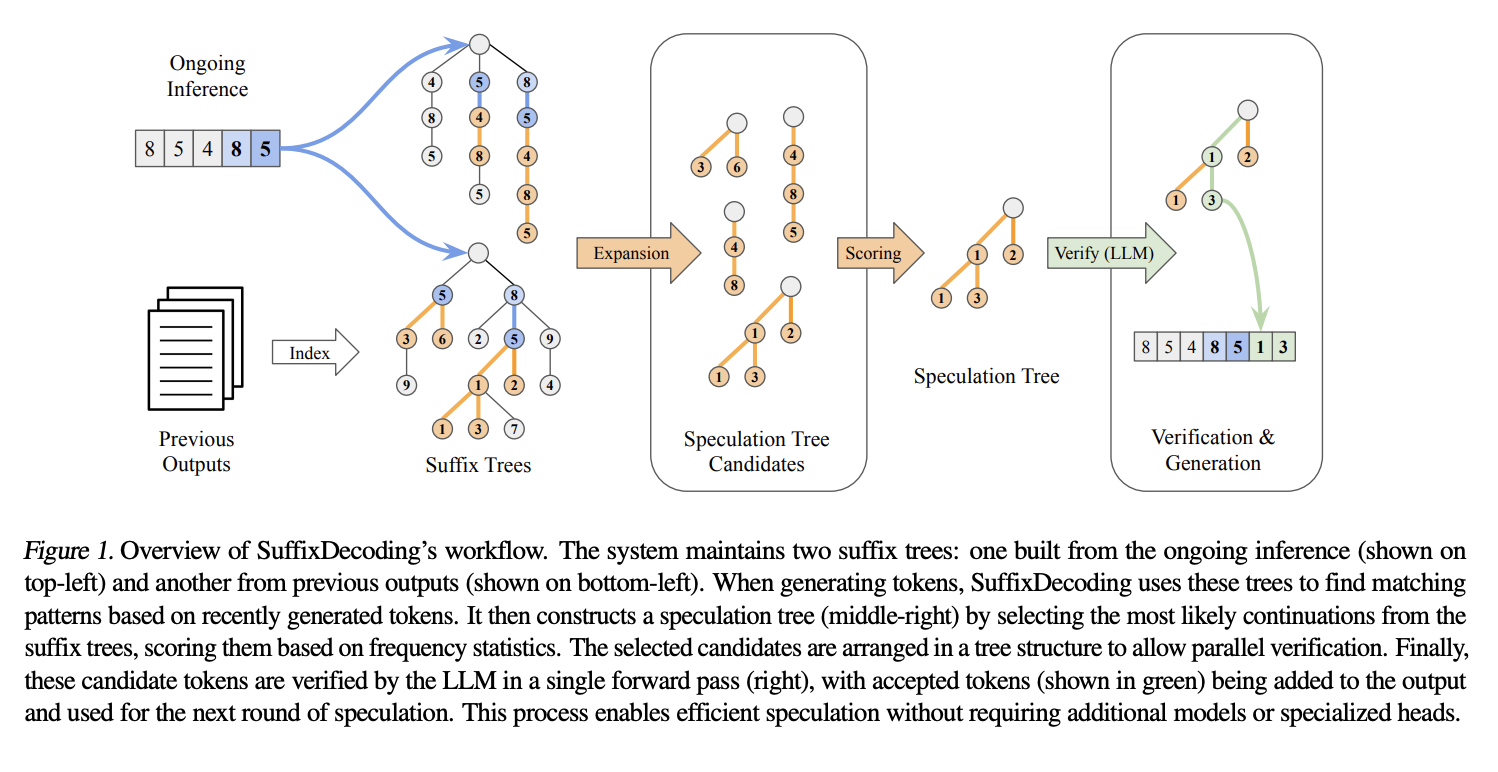
Исследователи из Snowflake AI Research и Университета Карнеги-Меллона представили SuffixDecoding — подход без модели, который не требует начальных моделей или дополнительных декодирующих голов. Он использует эффективные суффиксные деревья, основанные на предыдущих выводах и текущих запросах.
Как работает SuffixDecoding?
Процесс начинается с токенизации пар «запрос-ответ», после чего строится суффиксное дерево. Каждая нода дерева представляет токен, а путь от корня к любой ноде соответствует последовательности из обучающих данных. Это позволяет избежать сложностей и затрат на память, связанных с интеграцией моделей.
Преимущества SuffixDecoding
Для каждого нового запроса SuffixDecoding создает отдельное суффиксное дерево, что особенно полезно для задач, таких как:
- Суммирование документов
- Ответы на вопросы
- Многоходовые беседы
- Редактирование кода
Суффиксное дерево отслеживает частоту появления различных последовательностей токенов, что позволяет эффективно находить все возможные продолжения.
Эффективность и результаты
Эксперименты показывают, что SuffixDecoding достигает до 2.9x большей производительности по сравнению с предыдущими методами. Он также демонстрирует более высокую точность в генерации токенов, что позволяет значительно ускорить процесс.
Вывод
SuffixDecoding — это модельный подход для ускорения вывода LLM, который использует суффиксные деревья для оптимизации работы. Он показывает высокую эффективность и подходит для сложных многопоточных задач.
Как внедрить ИИ в вашу компанию?
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить.
- Выберите подходящее решение и внедряйте ИИ постепенно.
Если нужны советы по внедрению ИИ, пишите нам!
«`




















