
«`html
Многофункциональные большие языковые модели (MLLMs)
Многофункциональные большие языковые модели (MLLMs) быстро развиваются, позволяя машинам одновременно интерпретировать текстовые и визуальные данные. Эти модели имеют трансформационные приложения в анализе изображений, ответах на визуальные вопросы и многомодальном рассуждении. Они играют важную роль в улучшении способности искусственного интеллекта понимать и взаимодействовать с миром.
Проблемы и решения
Несмотря на их потенциал, эти системы сталкиваются с серьезными вызовами. Основная проблема заключается в зависимости от естественного языка для обучения, что часто приводит к низкому качеству визуального представления. Увеличение размера наборов данных и вычислительной сложности дало лишь небольшие улучшения. Необходима более целенаправленная оптимизация для визуального понимания.
Существующие методы обучения MLLMs обычно используют визуальные кодеры для извлечения признаков из изображений и подачи их в языковую модель вместе с текстовыми данными. Однако эти подходы требуют значительных ресурсов, что ограничивает их масштабируемость.
Подход OLA-VLM
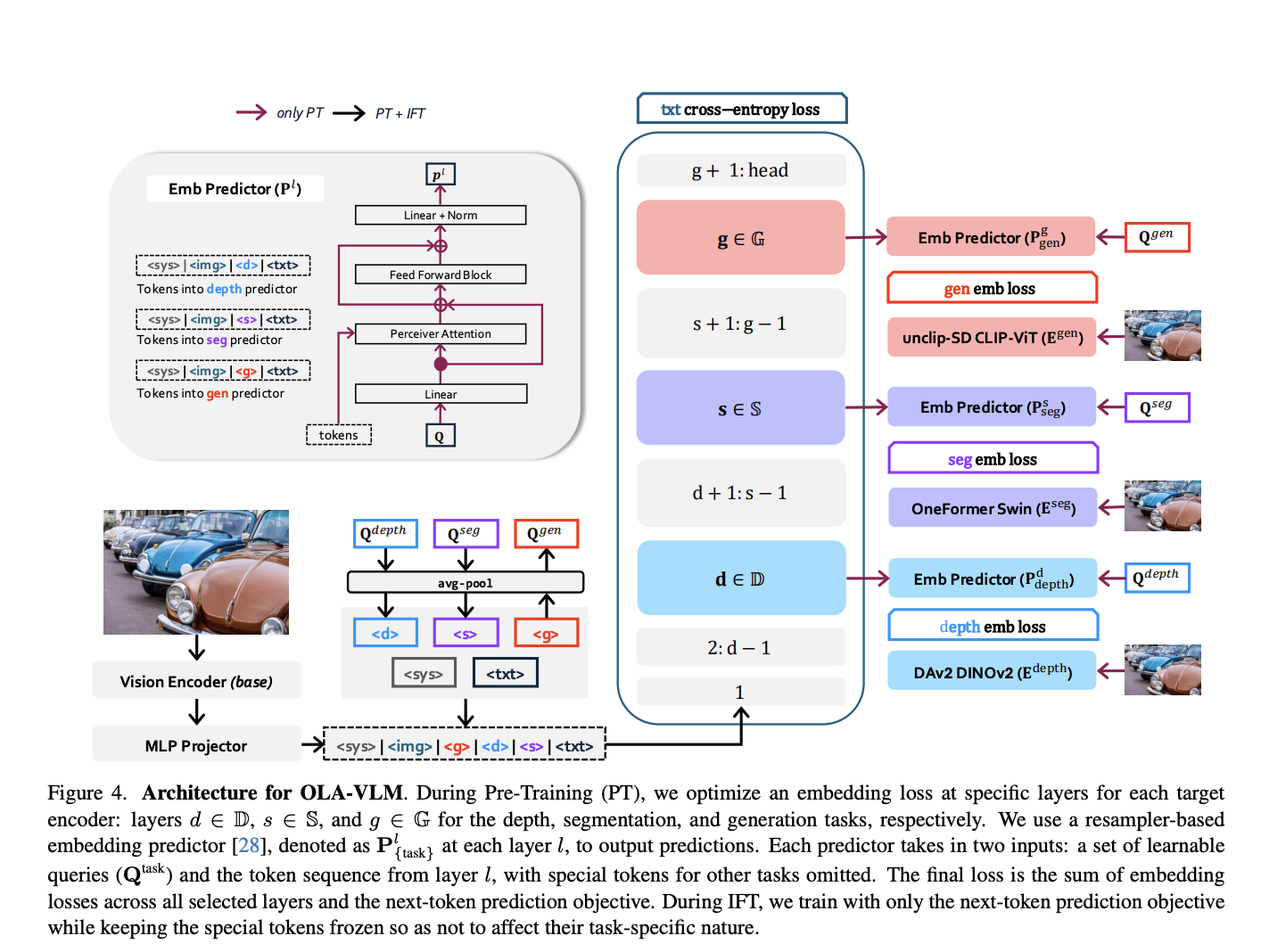
Исследователи из SHI Labs и Microsoft Research представили новый подход под названием OLA-VLM. Этот метод улучшает MLLMs, дистиллируя вспомогательную визуальную информацию в скрытые слои во время предварительного обучения. Вместо увеличения сложности визуального кодера, OLA-VLM использует оптимизацию встраивания для улучшения согласования визуальных и текстовых данных.
Технология OLA-VLM включает функции потерь встраивания для оптимизации представлений от специализированных визуальных кодеров. Эти кодеры обучаются для задач сегментации изображений, оценки глубины и генерации изображений. Дистиллированные признаки интегрируются в языковую модель, что обеспечивает лучшее визуальное рассуждение без дополнительных вычислительных затрат.
Результаты и эффективность
Производительность OLA-VLM была тщательно протестирована на различных бенчмарках, показывая значительные улучшения по сравнению с существующими моделями. Например, на CV-Bench OLA-VLM превзошел базовую модель LLaVA-1.5 на 8.7% в задачах оценки глубины.
Анализ представлений, полученных OLA-VLM, показал, что модель достигла лучшего согласования визуальных признаков в промежуточных слоях, что значительно улучшило ее производительность в различных задачах.
Заключение
Исследование SHI Labs и Microsoft Research подчеркивает значительный прогресс в многомодальном ИИ. OLA-VLM устанавливает новый стандарт для интеграции визуальной информации в MLLMs, улучшая качество визуальных представлений с меньшими вычислительными затратами.
Как использовать ИИ в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации и какие ключевые показатели эффективности (KPI) вы хотите улучшить.
Подберите подходящее решение и внедряйте ИИ постепенно. Начните с малого проекта, анализируйте результаты и расширяйте автоматизацию на основе полученных данных.
Если вам нужны советы по внедрению ИИ, пишите нам в Telegram. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
Попробуйте AI Sales Bot, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab.
«`





















