
«`html
Проблема и Решение
Широкое использование крупных языковых моделей (LLMs) в критически важных областях создало важную задачу: как обеспечить соблюдение четких этических и безопасных стандартов. Существующие методы выравнивания, такие как супервизированное тонкое обучение и обучение с подкреплением на основе человеческой обратной связи, имеют свои ограничения. Модели могут генерировать вредоносный контент, отказываться от законных запросов или плохо справляться с незнакомыми ситуациями.
Что такое Делиберативное Выравнивание?
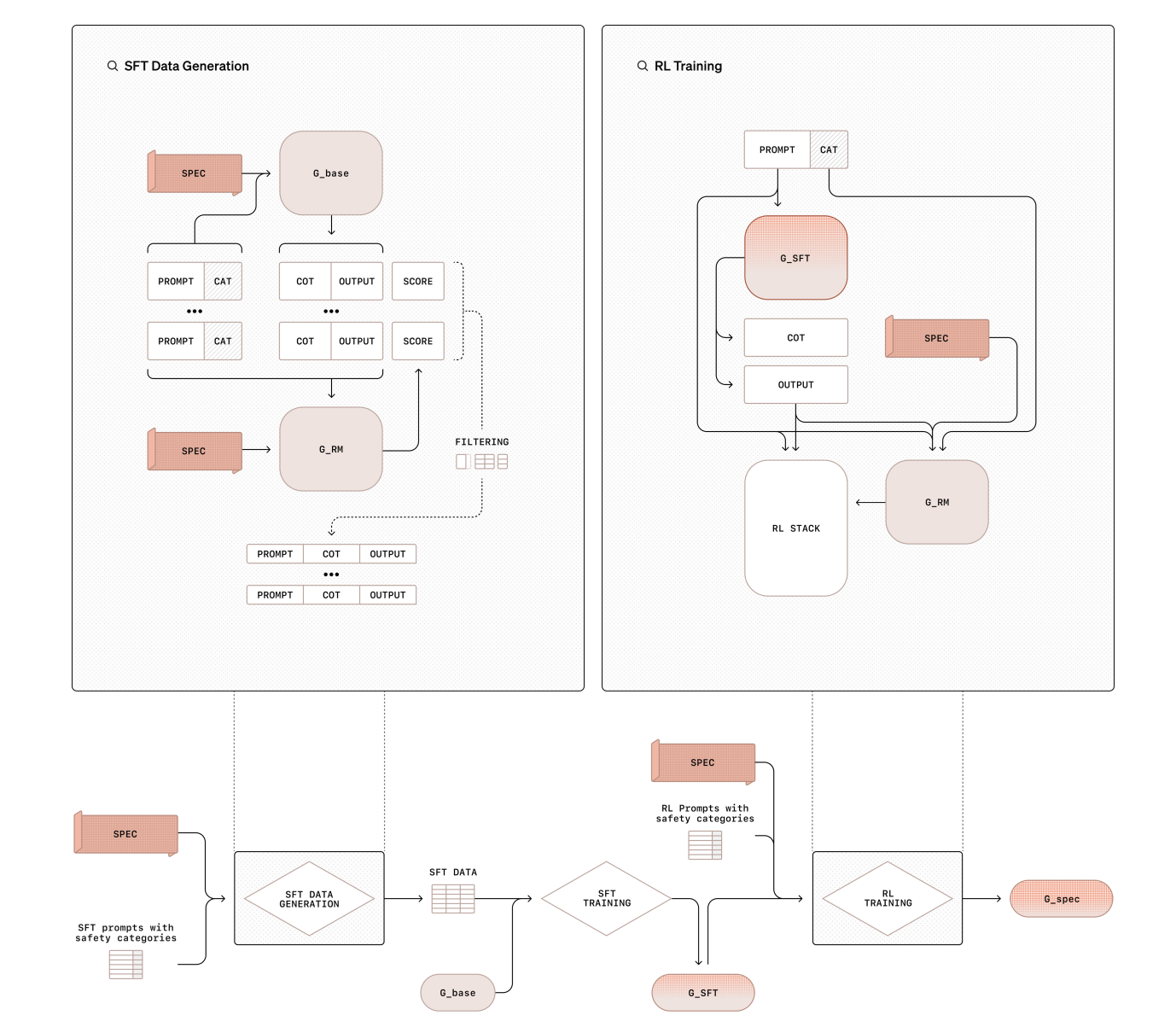
Исследователи OpenAI предложили Делиберативное Выравнивание — новый подход, который обучает модели четким стандартам безопасности и учит их рассуждать по этим стандартам перед генерацией ответов. Это решение решает ключевые недостатки традиционных методов выравнивания.
Преимущества Делиберативного Выравнивания
- Обучение моделей учитывать соответствующие политики.
- Использование данных, сгенерированных моделями, для достижения лучших результатов в области безопасности.
- Улучшенная устойчивость к атакам и меньше отказов от валидных запросов.
Технические детали и преимущества
Делиберативное Выравнивание включает двухступенчатый процесс обучения:
- Первый этап — супервизированное тонкое обучение, которое помогает моделям понять принципы безопасности.
- На втором этапе обучение с подкреплением улучшает рассуждения модели с помощью модели вознаграждений.
Этот процесс не требует аннотированных данных, что снижает затраты на обучение.
Результаты и выводы
Делиберативное Выравнивание показало заметные улучшения в производительности моделей OpenAI. Например, модель o1 продемонстрировала высокую устойчивость к атакам, а также хорошую точность в ответах на безопасные запросы. Эти результаты подчеркивают надежность и эффективность нового подхода.
Заключение
Делиберативное Выравнивание представляет собой значительный шаг вперед в выравнивании языковых моделей с принципами безопасности. Оно предлагает масштабируемое и понятное решение для сложных этических задач. Успех моделей серии o1 демонстрирует потенциал этого подхода для повышения безопасности и надежности ИИ-систем.
Как внедрить ИИ в вашу компанию?
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта, выполните следующие шаги:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение из множества доступных вариантов ИИ.
- Внедряйте ИИ постепенно: начните с малого проекта, анализируйте результаты и KPI.
- На основе полученных данных расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
Попробуйте AI Sales Bot — этот AI ассистент в продажах помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. Будущее уже здесь!
«`




















