
«`html
Важность очистки данных для языковых моделей
Очистка данных является важным этапом в создании высококачественных наборов данных для обучения языковых моделей. Этот процесс включает методы, такие как удаление дубликатов, фильтрация и смешивание данных, которые повышают эффективность и точность моделей. Цель состоит в том, чтобы создать наборы данных, улучшающие производительность моделей по различным задачам, от понимания естественного языка до сложного рассуждения.
Существующие методы очистки данных и новое решение
Существующие методы включают удаление дубликатов, фильтрацию и использование модельных подходов для формирования обучающих наборов. Однако производительность этих стратегий существенно различается, и требуется принятие общего решения относительно наиболее эффективного подхода для очистки обучающих данных для языковых моделей.
Команда исследователей из университета Вашингтона, Apple и Toyota Research Institute разработала новый рабочий процесс DataComp for Language Models (DCLM). Этот метод направлен на создание высококачественных обучающих наборов данных и установление стандартов для оценки их производительности.
Этапы DCLM-рабочего процесса и его результаты
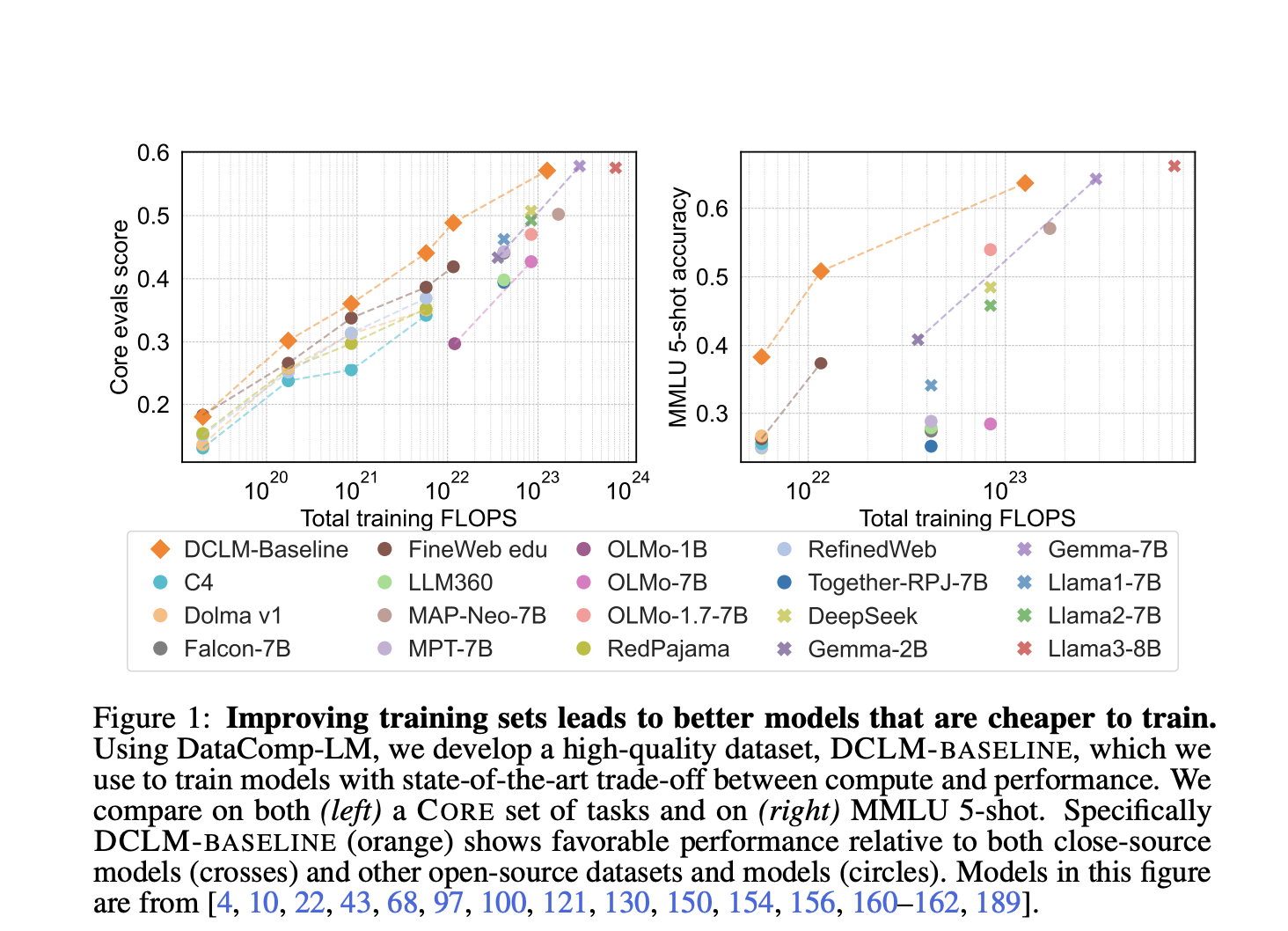
Рабочий процесс DCLM включает несколько ключевых этапов, включая извлечение текста из сырых HTML с помощью инструмента Resiliparse, удаление дубликатов при помощи фильтра Блума и модельную фильтрацию. Эти шаги критически важны для создания высококачественного обучающего набора данных, известного как DCLM-BASELINE. Метикулезный процесс гарантирует включение только наиболее актуальных и высококачественных данных в обучающий набор.
DCLM-BASELINE показал значительное улучшение производительности модели, достигнув 64% 5-шотовой точности на MMLU. Это значительное улучшение по сравнению с предыдущими моделями подчеркивает эффективность метода DCLM в создании высококачественных обучающих наборов данных.
Заключение
Предложенный рабочий процесс DCLM устанавливает новый стандарт для очистки данных в языковых моделях, обеспечивая всеобъемлющую структуру для оценки и улучшения обучающих наборов данных. Это не только продвигает текущее состояние языкового моделирования, но также готовит почву для будущих улучшений в этой области.
Использование ИИ решений для вашего бизнеса
Если ваша компания хочет оставаться лидером с помощью искусственного интеллекта, DataComp for Language Models (DCLM) предлагает надежное решение для улучшения качества наборов данных и производительности моделей. Подумайте о том, как можно применить ИИ в вашем бизнесе, определите KPI, выберите подходящее решение и внедряйте его постепенно.
Если вам нужны советы по внедрению ИИ, не стесняйтесь связаться с нами. Попробуйте наш AI Sales Bot для улучшения результата вашего отдела продаж. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab.
Ссылки:
«`



















