
Введение в обучение с подкреплением
Обучение с подкреплением (RL) стало ключевым элементом в развитии крупных языковых моделей (LLM), улучшая их способности к рассуждению для выполнения сложных задач. Однако исследовательское сообщество сталкивается с серьезными трудностями в воспроизведении передовых методов RL из-за недостаточной прозрачности ключевых деталей обучения от крупных игроков отрасли.
Введение DAPO
Недавно исследователи из ByteDance, Университета Цинхуа и Гонконгского университета представили DAPO (Dynamic Sampling Policy Optimization) — открытую систему обучения с подкреплением, разработанную для улучшения способностей рассуждения крупных языковых моделей. Система DAPO стремится устранить проблемы воспроизводимости, открыто делясь всеми алгоритмическими деталями, процедурами обучения и наборами данных.
Ключевые инновации DAPO
Техническая основа DAPO включает четыре ключевых инновации:
- Clip-Higher: Решает проблему коллапса энтропии, управляя коэффициентом обрезки в обновлениях политики для стимулирования разнообразия выходных данных.
- Dynamic Sampling: Динамически фильтрует образцы на основе их полезности, обеспечивая более стабильный градиентный сигнал.
- Token-level Policy Gradient Loss: Предлагает уточненный метод расчета потерь, акцентируя внимание на уровне токенов.
- Overlong Reward Shaping: Вводит контролируемый штраф за чрезмерно длинные ответы, направляя модели к более сжатому и эффективному рассуждению.
Практические результаты
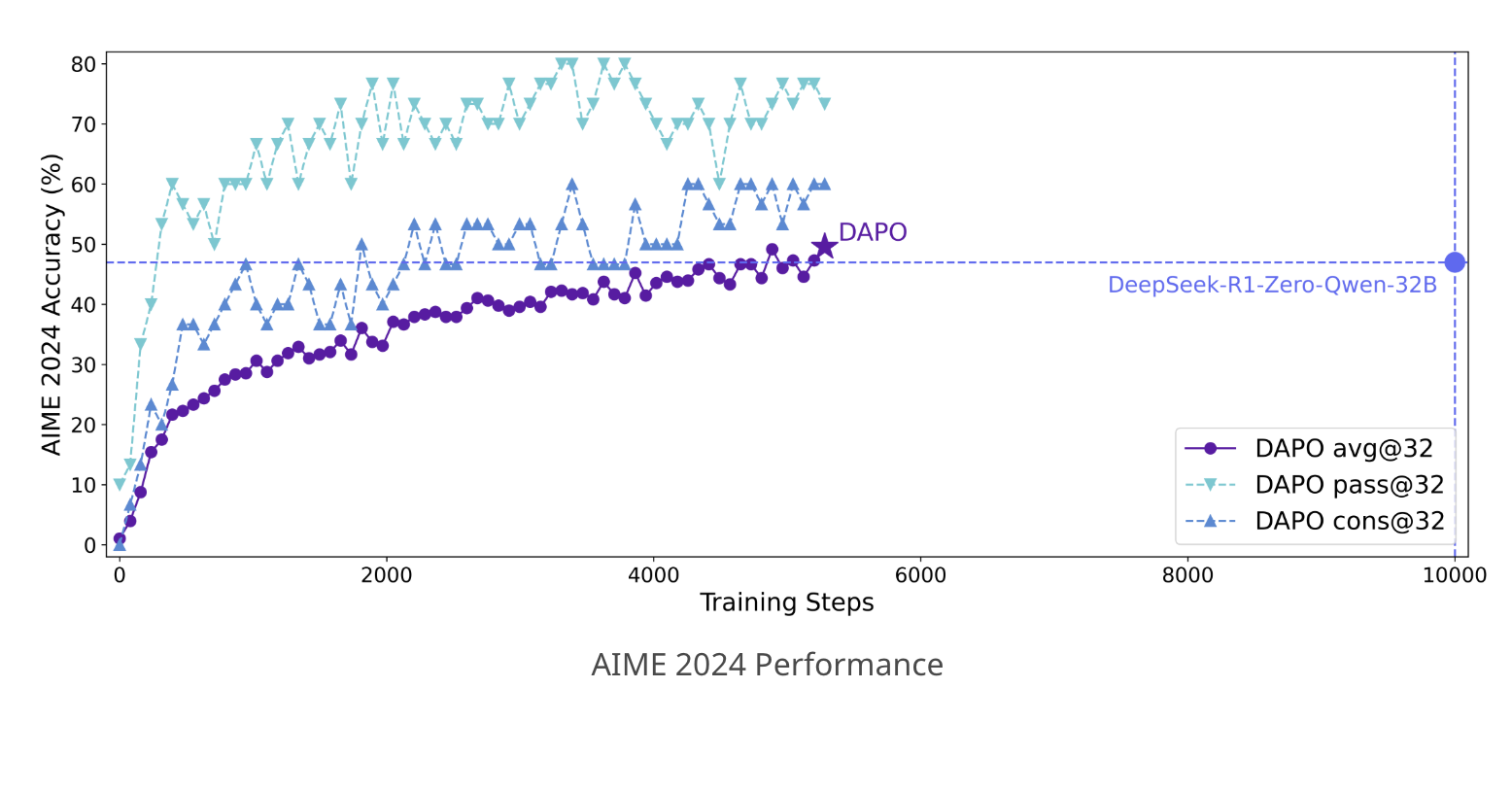
В практических экспериментах DAPO показал значительные улучшения. Модели, обученные с помощью DAPO, достигли 50 баллов на тесте American Invitational Mathematics Examination (AIME) 2024, что выше, чем у предыдущих методов.
Динамика обучения
Динамика обучения DAPO предоставила новые инсайты о развивающихся паттернах рассуждения моделей. С течением времени модели начали демонстрировать более рефлексивное поведение, что подчеркивает способность обучения с подкреплением не только улучшать существующие пути рассуждения, но и развивать новые когнитивные стратегии.
Заключение
Открытие DAPO представляет собой значимый вклад в сообщество обучения с подкреплением, устраняя преграды, созданные недоступными методологиями. Это сотрудничество между ByteDance, Университетом Цинхуа и Гонконгским университетом демонстрирует потенциал прозрачных и совместных исследований для улучшения понимания и практических возможностей систем обучения с подкреплением.
Практические рекомендации для бизнеса
Исследуйте, как технологии ИИ могут трансформировать ваш подход к работе:
- Идентифицируйте процессы, которые можно автоматизировать.
- Определите ключевые показатели эффективности (KPI), чтобы убедиться, что ваши инвестиции в ИИ приносят положительные результаты.
- Выбирайте инструменты, соответствующие вашим потребностям, и настраивайте их под свои цели.
- Начните с небольшого проекта, соберите данные о его эффективности и постепенно расширяйте использование ИИ.
Контакты
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Чтобы быть в курсе последних новостей ИИ, подписывайтесь на наш Telegram.
Пример решения на базе ИИ
Посмотрите практический пример решения на базе ИИ: бот для продаж, разработанный для автоматизации взаимодействий с клиентами на всех этапах их пути.



















