
«`html
Системы генерации с поддержкой извлечения (RAG)
Системы RAG — это важное направление в области искусственного интеллекта, которое улучшает большие языковые модели (LLM) с помощью внешних источников информации для генерации ответов. Это особенно полезно в таких областях, как ответ на вопросы и поиск информации, где необходимы точные ответы.
Проблемы традиционных RAG систем
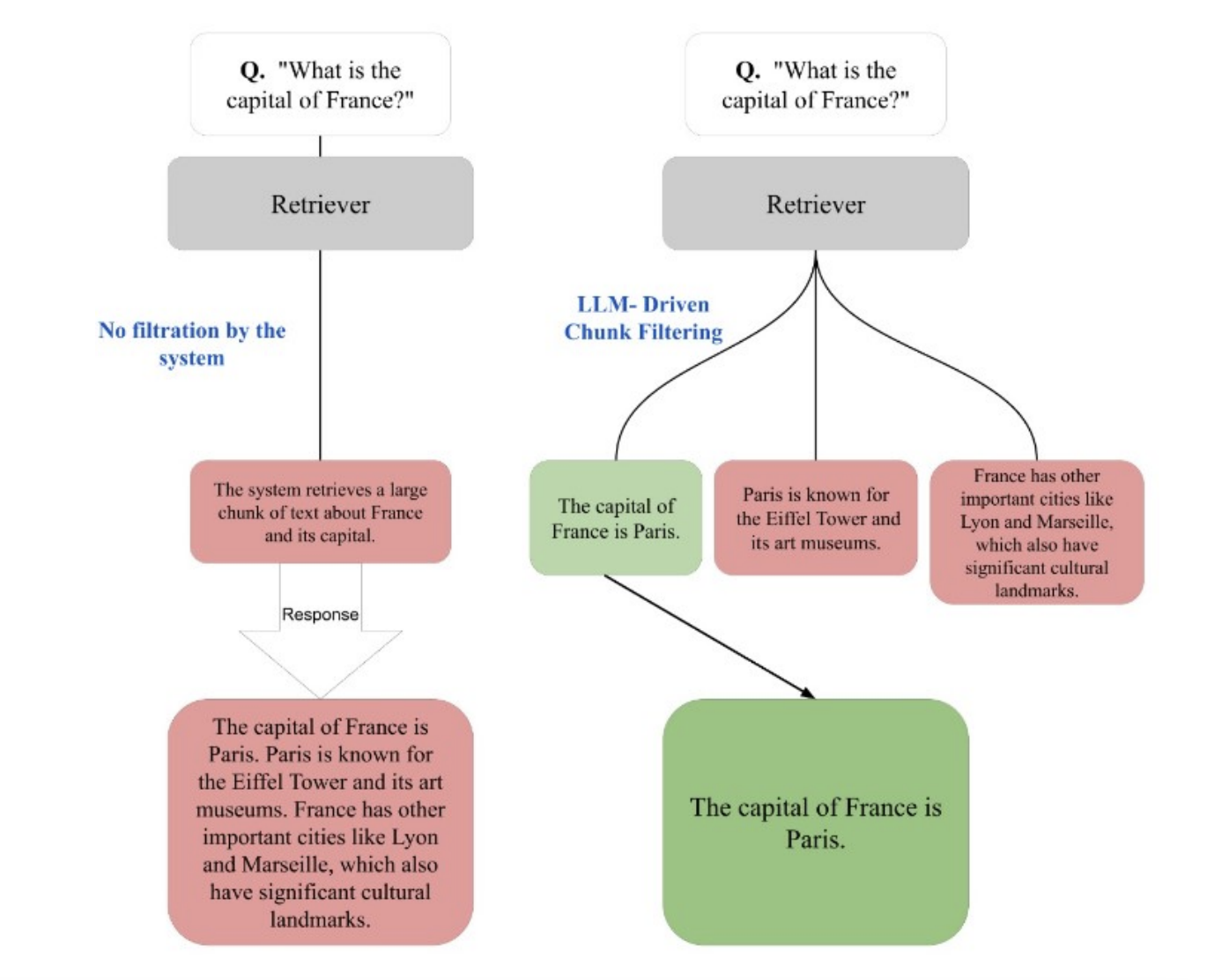
Основная задача RAG систем — извлечение только самой релевантной информации, отбрасывая ненужные данные. Традиционные методы часто извлекают большие объемы документов, что может привести к включению нерелевантной информации. Это особенно критично в областях, где точность фактов имеет большое значение.
Новый подход ChunkRAG
Исследователи из Algoverse AI Research предложили новый подход ChunkRAG, который фильтрует извлекаемые данные на уровне «чанков» (частей текста). Этот метод позволяет избегать нерелевантной информации и повышает точность ответов модели.
Методология ChunkRAG
ChunkRAG разбивает документы на управляемые «чанки» и каждый из них оценивает на релевантность. Это включает в себя использование многослойной системы оценки на основе LLM и механизма самоанализа.
Результаты и преимущества ChunkRAG
ChunkRAG показал значительные улучшения в точности, достигнув 64.9% на тестах PopQA, что на 10% выше, чем у конкурирующей модели CRAG. Также, ChunkRAG уменьшает нерелевантные данные более чем на 15% по сравнению с традиционными системами RAG.
Основные выводы о ChunkRAG:
- Улучшенная точность: 64.9% на PopQA, что превышает традиционные системы на 10%.
- Улучшенная фильтрация: Использует фильтрацию на уровне чанков.
- Динамическое оценивание релевантности: Включает механизм самоанализа, что позволяет более точно оценивать релевантность.
- Адаптация для сложных задач: Подходит для мультишаговых рассуждений и проверки фактов.
- Потенциал для более широкого применения: Может быть адаптирован для различных наборов данных.
Заключение
ChunkRAG предлагает инновационное решение для ограничения традиционных моделей RAG, сосредоточившись на фильтрации на уровне чанков и динамическом оценивании релевантности. Этот подход значительно улучшает точность и надежность генерируемых ответов.
«`




















