
«`html
Language Models and AI Advancements
Языковые модели являются ключевыми в продвижении искусственного интеллекта (ИИ), улучшая способность машин обрабатывать и генерировать текст, приближенный к человеческому. Важно, чтобы эти модели становились все более сложными, используя обширные объемы данных и сложные архитектуры для оптимизации производительности и эффективности. Одна из основных проблем в этой области заключается в разработке моделей, способных управлять обширными наборами данных без излишних вычислительных затрат.
Существующие исследования в области больших языковых моделей (LLM)
Существующие исследования в области больших языковых моделей (LLM) включают фундаментальные рамки, такие как GPT-3 от OpenAI и BERT от Google, использующие традиционные архитектуры трансформеров. Модели, такие как LLaMA от Meta и T5 от Google, сосредотачиваются на совершенствовании эффективности обучения и вывода. Инновации, такие как Sparse и Switch Transformers, исследуют более эффективные механизмы внимания и архитектуры Mixture-of-Experts (MoE) соответственно. Эти модели стремятся сбалансировать вычислительные требования с производительностью, влияя на последующие разработки, такие как GShard и Switch Transformer, оптимизирующие механизмы маршрутизации и балансировки нагрузки среди экспертов модели.
DeepSeek-V2: Продвинутая Модель Языка
Исследователи из DeepSeek-AI представили DeepSeek-V2, сложную модель языка MoE, использующую инновационный механизм Multi-head Latent Attention (MLA) и архитектуру DeepSeekMoE. Этот подход уникальным образом обеспечивает эффективность, активируя только долю своих общих параметров для каждой задачи, резко снижая вычислительные затраты при сохранении высокой производительности. Механизм MLA значительно сокращает необходимый для вывода кэш Key-Value, оптимизируя обработку без ущерба для глубины контекстного понимания.
Методология DeepSeek-V2
Методология DeepSeek-V2 сосредоточена на продвинутых протоколах обучения и оценке обширных наборов данных. Модель была предварительно обучена с использованием тщательно составленного корпуса, содержащего 8,1 трлн токенов из различных высококачественных мультиязычных наборов данных. Это обучение использовало Supervised Fine-Tuning (SFT) и Reinforcement Learning (RL) для совершенствования производительности и адаптивности в различных сценариях. Оценки проводились с использованием набора стандартизированных бенчмарков для измерения эффективности модели в реальных приложениях. Используемая структура, включая механизм Multi-head Latent Attention и Rotary Position Embedding, была критически важна для обеспечения эффективности и эффективности модели без излишних вычислительных затрат.
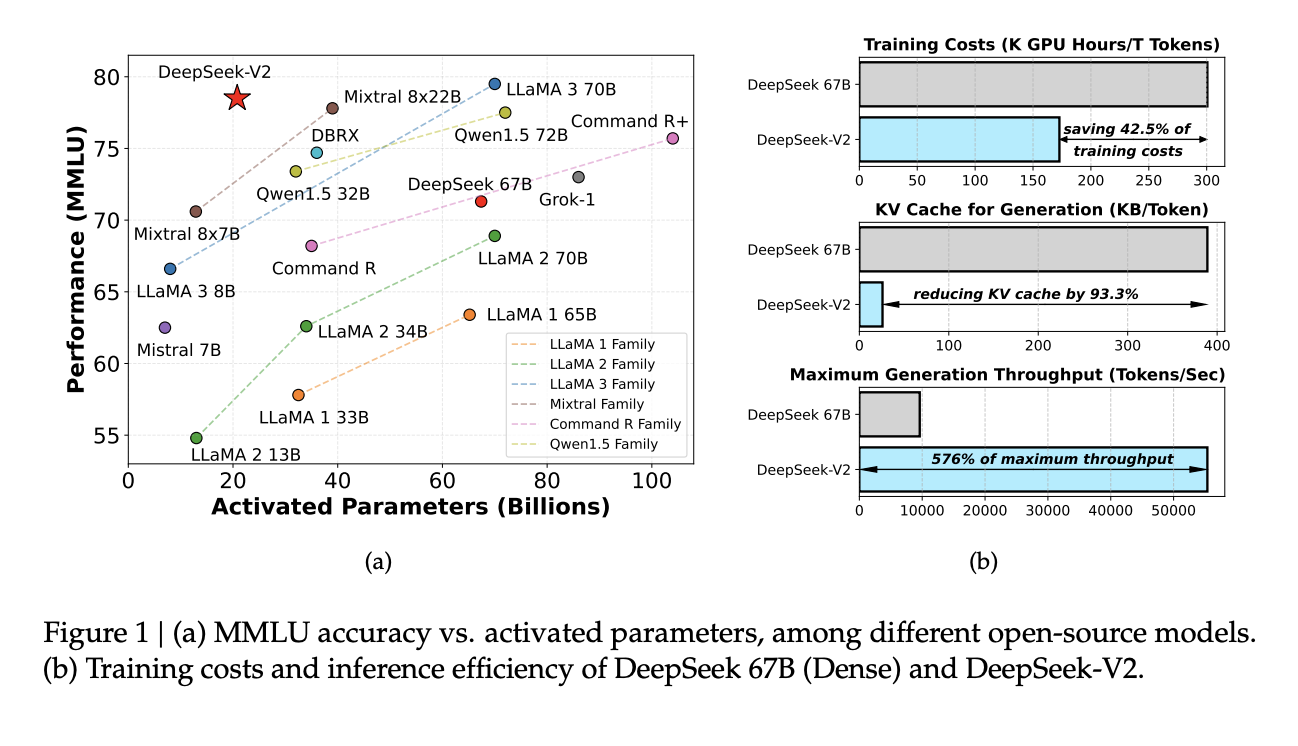
Успех DeepSeek-V2
DeepSeek-V2 продемонстрировала значительное улучшение показателей эффективности и производительности. По сравнению с предыдущей версией, DeepSeek 67 B, модель достигла сокращения затрат на обучение на 42,5% и уменьшения размера кэша Key-Value на 93,3%. Более того, она увеличила максимальную скорость генерации в 5,76 раз. В бенчмарках DeepSeek-V2 с активированными всего 21 млрд параметров постоянно превосходила другие открытые модели, занимая высокие позиции по различным показателям производительности в различных языковых задачах. Этот количественный успех подчеркивает практическую эффективность DeepSeek-V2 в развертывании передовой технологии языковых моделей.
Заключение
DeepSeek-V2, разработанная DeepSeek-AI, вносит значительные усовершенствования в технологию языковых моделей благодаря своей архитектуре Mixture-of-Experts и механизму Multi-head Latent Attention. Эта модель успешно снижает вычислительные затраты, улучшая производительность, что подтверждается резкими сокращениями затрат на обучение и улучшением скорости обработки. Демонстрируя надежную эффективность на различных бенчмарках, DeepSeek-V2 устанавливает новый стандарт эффективных и масштабируемых моделей ИИ, делая ее важным достижением для будущих приложений в обработке естественного языка и за ее пределами.
Проверьте статью и Github. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, серверу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit с более чем 41 тыс. подписчиков.
Этот пост был опубликован на портале MarkTechPost.
Внедрение ИИ в ваш бизнес
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте This AI Paper by DeepSeek-AI Introduces DeepSeek-V2: Harnessing Mixture-of-Experts for Enhanced AI Performance.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`



















