
«`html
Расширение возможностей моделей больших языков (LLM) в тестовое время с использованием дополнительных вычислений
Исследователи из UC Berkeley и Google DeepMind предлагают адаптивную стратегию «оптимального вычисления» для масштабирования тестового времени вычислений в LLM.
Исследователи изучают способы расширения возможностей LLM, чтобы они могли более эффективно решать сложные задачи, подобные человеческому мышлению. Это может открыть новые перспективы в задачах агентства и рассуждения, позволить заменить крупномасштабные LLM на устройствах более компактными моделями и обеспечить путь к общим алгоритмам самоусовершенствования с уменьшенным человеческим наблюдением.
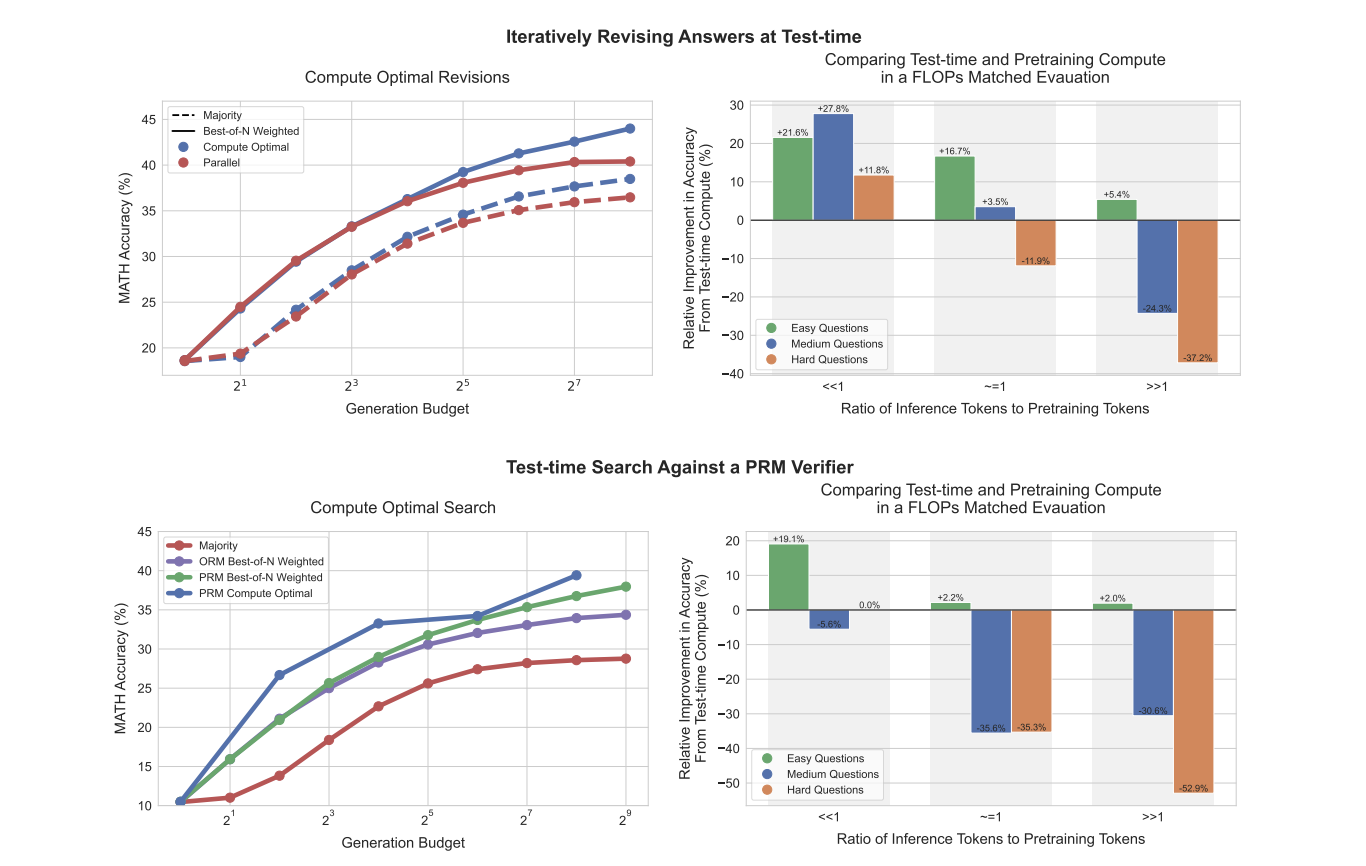
Исследователи предлагают адаптивную «оптимальную вычислительную» стратегию для выбора наиболее эффективного метода использования дополнительных вычислений, основываясь на конкретной задаче и уровне ее сложности. Это позволяет значительно улучшить масштабирование, превосходя лучшие из N базовые линии, используя при этом примерно в 4 раза меньше вычислений как для методов ревизии, так и для поиска.
Использование дополнительных вычислений в LLM можно рассматривать через единую перспективу модификации предсказанного распределения модели в тестовое время. Для улучшения предложенного распределения и оптимизации проверки исследователи исследовали различные подходы, такие как RL-вдохновленные тонкую настройку и техники самокритики.
Исследование анализирует различные подходы к оптимизации масштабирования вычислений в LLM, включая алгоритмы поиска с процессными проверками (PRM) и улучшение предложенного распределения через ревизии. Сравнение показывает, что для простых и средней сложности вопросов использование дополнительных вычислений в тестовое время часто превосходит увеличение предварительного обучения. Однако для самых сложных вопросов дополнительное предварительное обучение остается более эффективным.
Это исследование демонстрирует важность адаптивных стратегий «оптимального вычисления» для масштабирования тестового времени вычислений в LLM. Сравнение показывает, что для простых и средней сложности вопросов использование дополнительных вычислений в тестовое время часто превосходит увеличение предварительного обучения в 4 раза.
«`
«`html
Подробнее о исследовании можно прочитать в оригинальной статье. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на нас в Twitter и присоединиться к нашим каналам в Telegram и LinkedIn. Если вам нравится наша работа, вам понравится и наша рассылка.
Также не забудьте присоединиться к нашему сообществу в Reddit.
Здесь вы можете найти предстоящие вебинары по искусственному интеллекту.
Arcee AI представляет Arcee Swarm: инновационное сочетание агентов, вдохновленное кооперативным интеллектом, обнаруженным в самой природе.
«`


















