
«`html
Google представила инновацию под названием DataGemma, разработанную для борьбы с одной из основных проблем современного искусственного интеллекта: галлюцинациями в больших языковых моделях (LLM).
Галлюцинации возникают, когда ИИ уверенно генерирует информацию, которая является неверной или выдуманной. Эти неточности могут подрывать полезность ИИ, особенно в исследованиях, разработке политики или других важных процессах принятия решений.
Практические решения и ценность
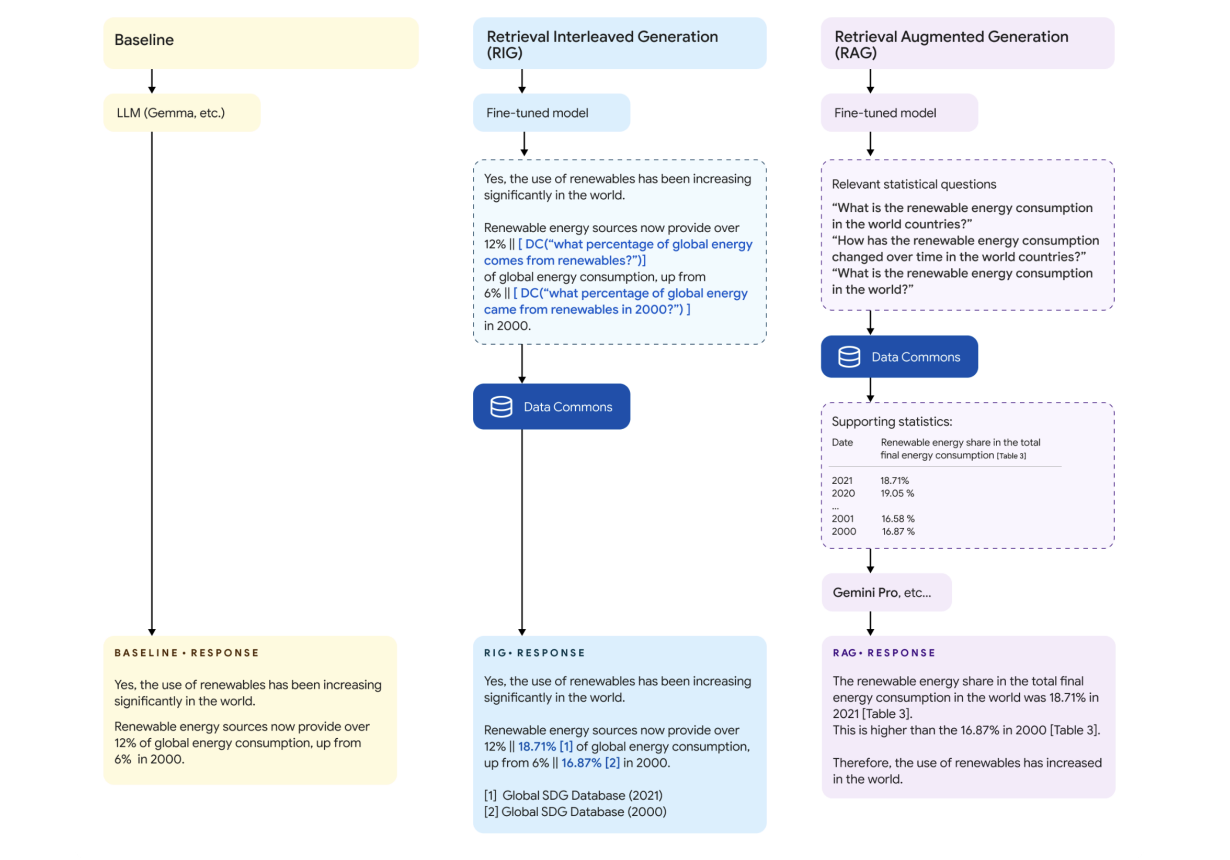
Google DataGemma направлена на укоренение LLM в реальных мировых статистических данных с помощью ресурсов Data Commons.
Введены две специфические варианты: DataGemma-RAG-27B-IT и DataGemma-RIG-27B-IT, представляющие передовые достижения в методологиях Retrieval-Augmented Generation (RAG) и Retrieval-Interleaved Generation (RIG).
Data Commons содержит более 240 миллиардов точек данных по многим статистическим переменным, включая данные от таких доверенных источников, как Всемирная организация здравоохранения, Центры по контролю и профилактике заболеваний и различные национальные бюро переписи населения.
Методология RIG обеспечивает проверку фактов по авторитетным источникам, а методология RAG обогащает контекст информации для более полезных ответов.
Значение для общества
Google DataGemma решает проблему галлюцинаций в больших языковых моделях (LLM), обеспечивая точность и достоверность информации, создаваемой ИИ. Это важный шаг к тому, чтобы ИИ стал надежным партнером в исследованиях, принятии решений и поиске знаний.
Google делает DataGemma доступной для исследователей и разработчиков, предоставляя им модели и заметки для быстрого старта обеих методологий RIG и RAG.
«`




















