
«`html
Проблемы и решения в области ИИ
Несмотря на огромный потенциал больших языковых моделей (LLM), они сталкиваются с серьезными проблемами при генерации точных ответов. Это особенно важно для задач, требующих работы с длинными и сложными документами в таких областях, как исследования, образование и промышленность.
Основные проблемы
Одной из главных проблем является склонность LLM к созданию неточной или «галлюцинированной» информации. Это происходит, когда модели генерируют правдоподобный текст, не основанный на входных данных. Такие ошибки могут привести к распространению дезинформации и снижению доверия к системам ИИ. Для решения этой проблемы необходимы комплексные критерии оценки, которые помогут убедиться, что генерируемый текст соответствует контексту.
Существующие решения
Существуют методы, такие как контролируемая донастройка и обучение с подкреплением, которые помогают улучшить точность LLM. Также применяются стратегии, основанные на интерпретации состояния модели, чтобы уменьшить количество неточностей. Однако эти подходы могут снижать креативность и разнообразие ответов. Поэтому необходимо создать надежную систему для оценки и улучшения точности LLM, не жертвуя другими качествами.
Новая инициатива
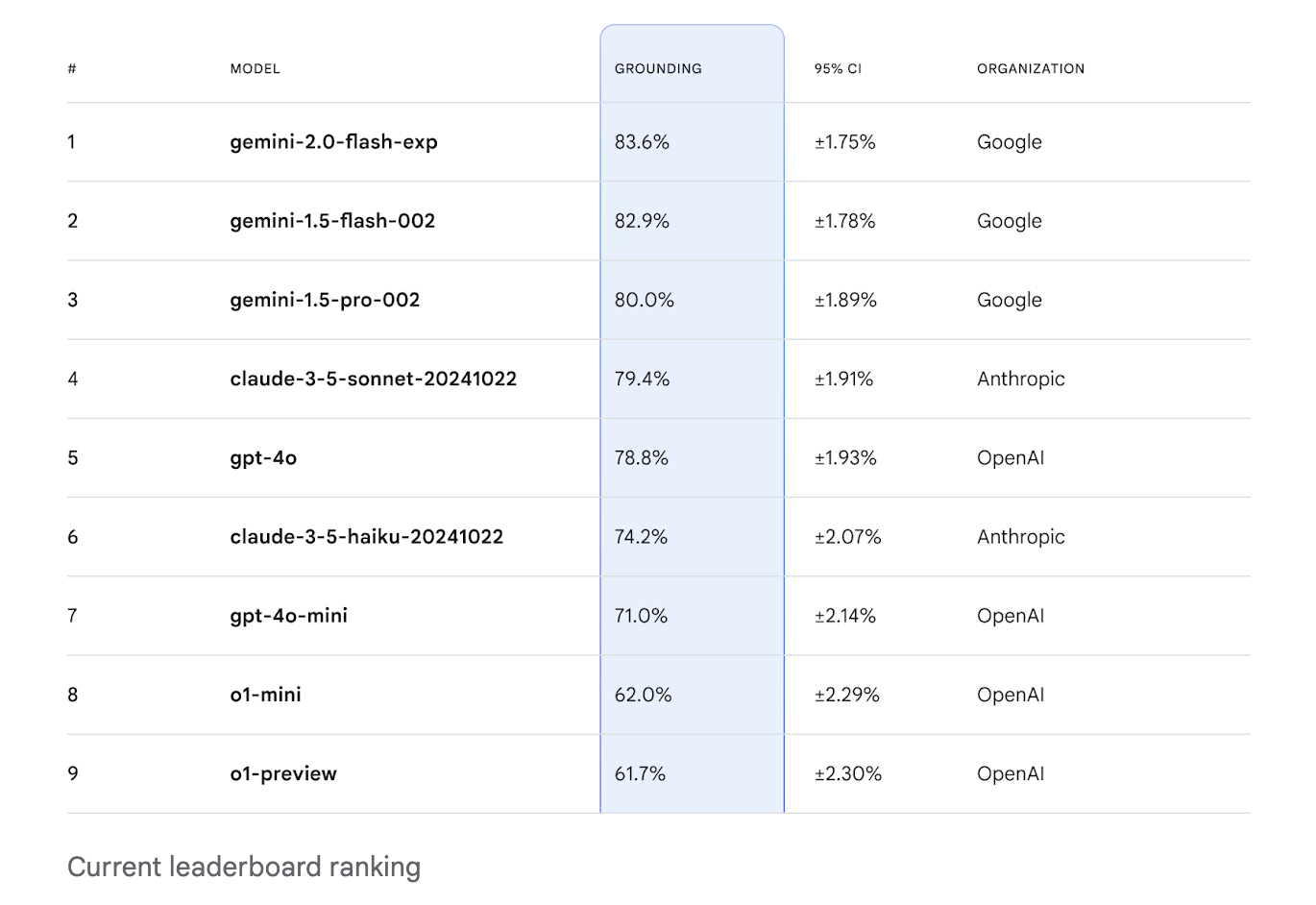
Исследователи из Google DeepMind и других организаций представили FACTS Grounding Leaderboard, который позволяет оценивать способность LLM генерировать ответы, полностью основанные на обширных контекстах. База данных включает запросы пользователей и источники документов до 32,000 токенов, что требует фактической точности ответов.
Методология оценки
Оценка включает два этапа: сначала проверяются ответы на соответствие запросам, затем оценивается их фактическая точность с помощью нескольких автоматических моделей. Например, используются модели Gemini 1.5 Pro и GPT-4o, которые помогают обеспечить высокую степень соответствия с человеческими оценками.
Результаты
Лидерборд показал разнообразные результаты по тестируемым моделям. Модель Gemini 1.5 Flash достигла впечатляющего результата в 85.8% точности. Эти результаты подчеркивают важность строгих критериев оценки и прозрачности в оценке моделей.
Заключение
FACTS Grounding Leaderboard заполняет важную нишу в оценке LLM, сосредотачиваясь на генерации длинных ответов. Это помогает продвигать точность фактов в ИИ-системах и устанавливает новые стандарты для оценки LLM.
Как внедрить ИИ в вашу компанию
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, следуйте этим шагам:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выберите подходящее решение из множества доступных вариантов.
- Внедряйте ИИ постепенно: начните с небольшого проекта и анализируйте результаты.
- На основе полученных данных расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
Попробуйте AI Sales Bot — этот ИИ-ассистент в продажах помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. Будущее уже здесь!
«`















