
«`html
Hex-LLM: Новый Фреймворк для Эффективного Обслуживания Открытых LLM на Google Cloud TPUs
В мире искусственного интеллекта большие языковые модели (LLM) становятся важными инструментами для различных приложений. Однако их эффективное развертывание и обслуживание остаются сложной задачей. Hex-LLM предлагает практические решения для этой проблемы.
Что такое Hex-LLM?
Hex-LLM — это фреймворк для обслуживания LLM, разработанный для аппаратного обеспечения Google Cloud TPU. Он обеспечивает высокую производительность и низкие затраты на развертывание открытых моделей из Hugging Face.
Ключевые особенности Hex-LLM
- Непрерывная пакетная обработка на основе токенов: Эффективное использование ресурсов TPU за счет обработки входящих токенов в непрерывном потоке.
- Оптимизированные ядра PagedAttention: Минимизация задержек и вычислительных нагрузок, что обеспечивает быструю обработку запросов.
- Тензорный параллелизм: Распределение вычислений по нескольким ядрам TPU для повышения эффективности.
- Динамические адаптеры LoRA и квантизация: Гибкая настройка моделей без необходимости их переобучения, что снижает использование памяти и увеличивает скорость вывода.
Интеграция с Hugging Face Hub
Hex-LLM позволяет разработчикам легко загружать и обслуживать модели из обширной библиотеки Hugging Face, упрощая процесс развертывания на Google TPUs.
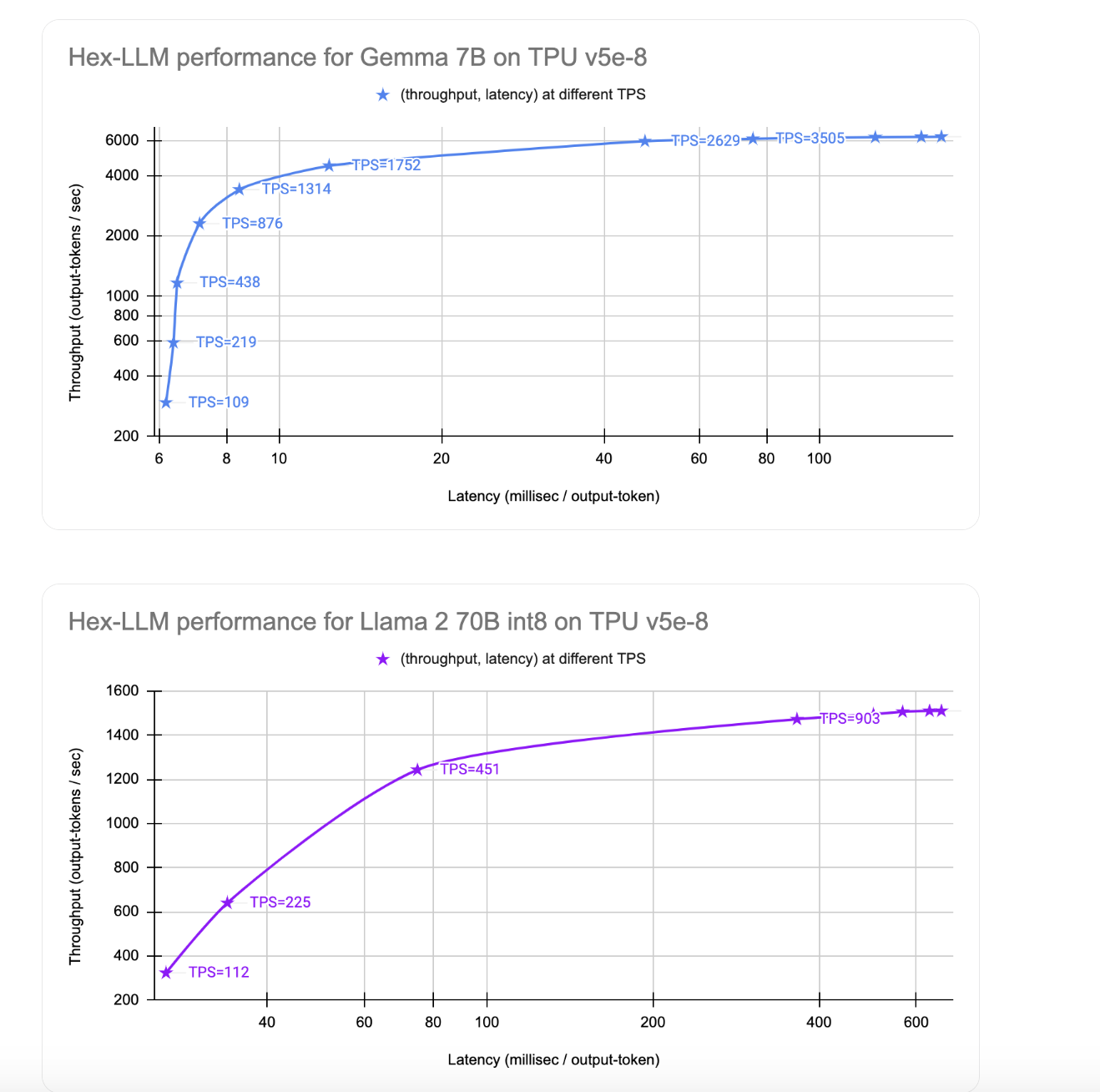
Показатели производительности: скорость и стоимость
Hex-LLM демонстрирует впечатляющие результаты, достигая 1510 токенов в секунду при обслуживании модели Llama 2 70B с затратами около $9.60 в час.
Доступность в Vertex AI Model Garden
Hex-LLM доступен в Vertex AI Model Garden, что упрощает доступ к предобученным моделям и инструментам для машинного обучения.
Заключение
Hex-LLM представляет собой значительный шаг вперед в эффективном обслуживании открытых LLM. С его помощью организации могут использовать мощь больших языковых моделей в своих приложениях.
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, грамотно используйте Hex-LLM. Проанализируйте, как ИИ может изменить вашу работу, определите ключевые показатели эффективности (KPI) и подберите подходящее решение.
Внедряйте ИИ решения постепенно, начиная с малого проекта. Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм.
Попробуйте AI Sales Bot — этот AI ассистент в продажах помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. Будущее уже здесь!
«`




















