
«`html
Мульти-модальное обучение в области искусственного интеллекта
Мульти-модальное обучение — это быстро развивающаяся область, фокусирующаяся на обучении моделей понимать и генерировать контент в различных модальностях, включая текст и изображения. Путем использования обширных наборов данных эти модели могут выстраивать визуальные и текстовые представления в общем вложенном пространстве, облегчая приложения, такие как подписи к изображениям и поиск текста по изображению. Интегрированный подход направлен на улучшение способности модели более эффективно обрабатывать различные типы входных данных.
Основные проблемы и практические решения
Основная проблема, решаемая в данном исследовании, — неэффективность текущих моделей в управлении только текстовыми и тексто-изображенческими задачами. Обычно существующие модели преуспевают в одной области, в то время как проявляют слабую производительность в другой, требуя отдельных систем для различных типов информационного поиска. Это увеличивает сложность таких систем и потребность в ресурсах, подчеркивая необходимость более унифицированного подхода.
Текущие методы, такие как Противопоставленное Предварительное Обучение Язык-Изображение (CLIP), выстраивают соответствие между изображениями и текстом через пары изображений и подписей к ним. Однако эти модели часто испытывают трудности с задачами только текста, поскольку не могут обрабатывать более длинные текстовые входы. Этот недостаток приводит к неоптимальной производительности в сценариях поиска текстовой информации, что затрудняет обработку задач, требующих эффективного понимания больших текстовых объемов.
Исследователи Jina AI представили модель Jina-clip-v1 для решения этих проблем. Эта модель с открытым исходным кодом использует новый мульти-задачный контрастный подход к обучению, разработанный для оптимизации соответствия текста-изображения и текст-текста в рамках одной модели. Этот метод направлен на объединение возможностей эффективной обработки обоих типов задач, снижая потребность в отдельных моделях.
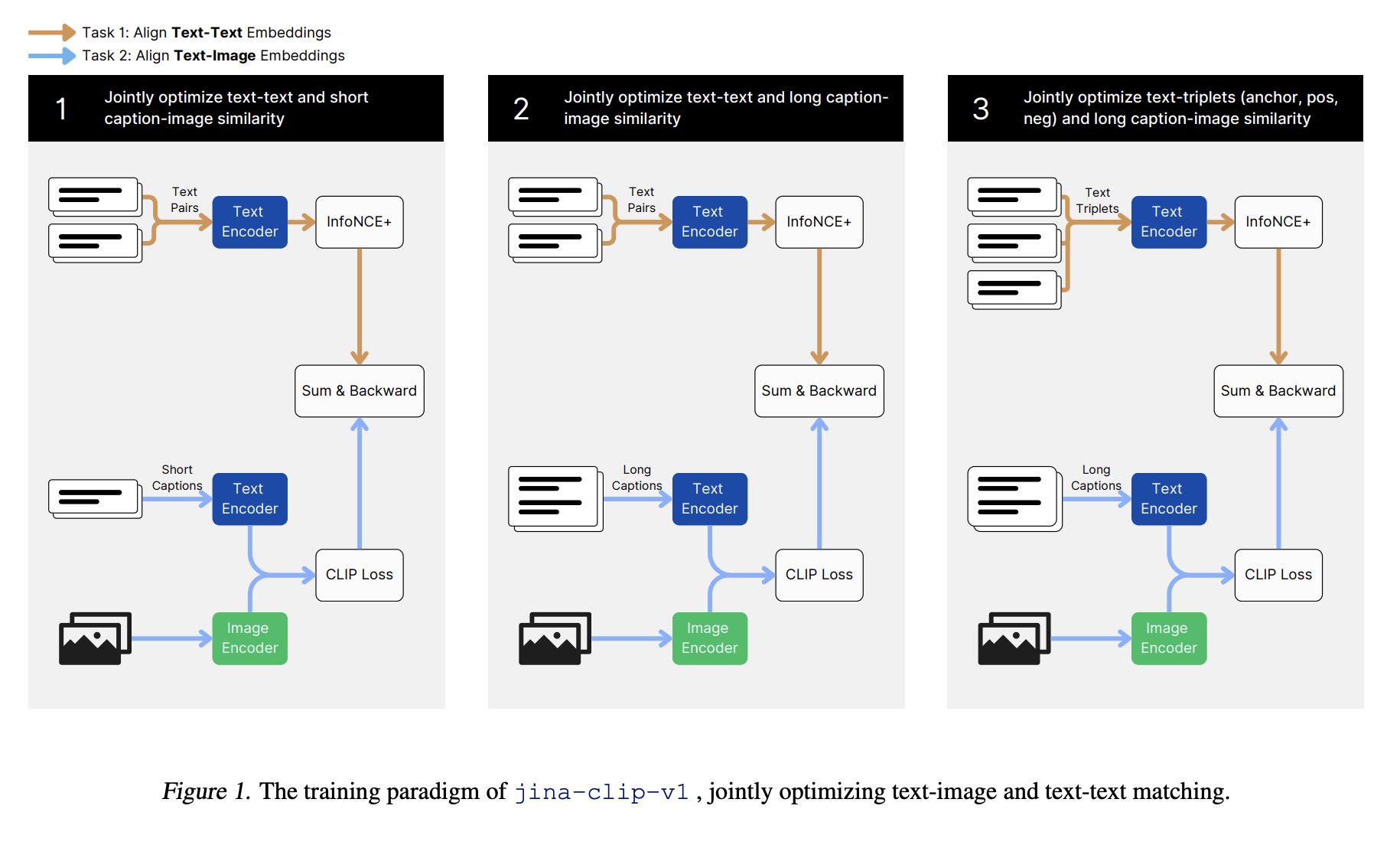
Предложенный метод обучения для jina-clip-v1 включает три этапа. Первый этап фокусируется на соответствии визуальных и текстовых представлений с использованием коротких, созданных человеком подписей, позволяя модели создать основу для мульти-модальных задач. На втором этапе исследователи ввели длинные синтетические подписи к изображениям для улучшения производительности модели в задачах поиска текста-текста. Финальный этап использует «тяжелые отрицательные» для настройки текстового кодировщика, улучшая его способность различать релевантные и нерелевантные тексты, сохраняя соответствие текста-изображения.
Оценки производительности показывают, что jina-clip-v1 достигает превосходных результатов в задачах поиска текста-изображения и поиска. Например, модель достигла среднего значения Recall@5 на уровне 85,8% по всем показателям поиска, превзойдя модель CLIP от OpenAI и демонстрируя производительность на уровне EVA-CLIP. Кроме того, в Massive Text Embedding Benchmark (MTEB), включающем восемь задач с участием 58 наборов данных, Jina-clip-v1 близко конкурирует с лучшими моделями только текстового вложения, достигая среднего результата 60,12%. Это улучшение по сравнению с другими моделями CLIP составляет приблизительно 15% в целом и 22% в задачах поиска.
Подробная оценка включала несколько этапов обучения. Для обучения текста-изображения на первом этапе модель использовала набор данных LAION-400M, содержащий 400 миллионов пар изображений и текста. На этом этапе произошли значительные улучшения в мульти-модальной производительности, хотя производительность текста-текста изначально не соответствовала из-за различий в длине текста между типами обучающих данных. Последующие этапы включали добавление синтетических данных с более длинными подписями и использование «тяжелых отрицательных», улучшая производительность поиска текста-текста и текста-изображения.
Выводы из этого исследования подчеркивают потенциал унифицированных мульти-модальных моделей, таких как Jina-clip-v1, в упрощении систем поиска информации путем объединения возможностей понимания текста и изображений в рамках одной структуры. Этот подход предлагает значительное улучшение эффективности для различных приложений путем сокращения потребности в отдельных моделях для различных модальностей задач, что приводит к потенциальной экономии вычислительных ресурсов и сложности.
Используйте ИИ для улучшения вашего бизнеса
Если вы хотите использовать возможности искусственного интеллекта для развития вашей компании и оставаться лидером, обратитесь к Jina AI Open Sources Jina CLIP: A State-of-the-Art English Multimodal (Text-Image) Embedding Model. Рассмотрите, как ИИ может изменить вашу работу, определите области, где можно применить автоматизацию, и найдите моменты, когда ваши клиенты могут извлечь выгоду от использования ИИ. Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ. Подберите подходящее решение из множества вариантов ИИ и внедряйте его постепенно, начиная с небольших проектов, анализируя результаты и KPI. На основе полученных данных и опыта расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`




















