
«`html
Важность многозначной коммуникации
В современном мире эффективная коммуникация на разных языках становится все более актуальной. Модели многомодального ИИ сталкиваются с проблемами при объединении изображений и текста на разных языках.
Jina-CLIP v2: Многоязычная модель
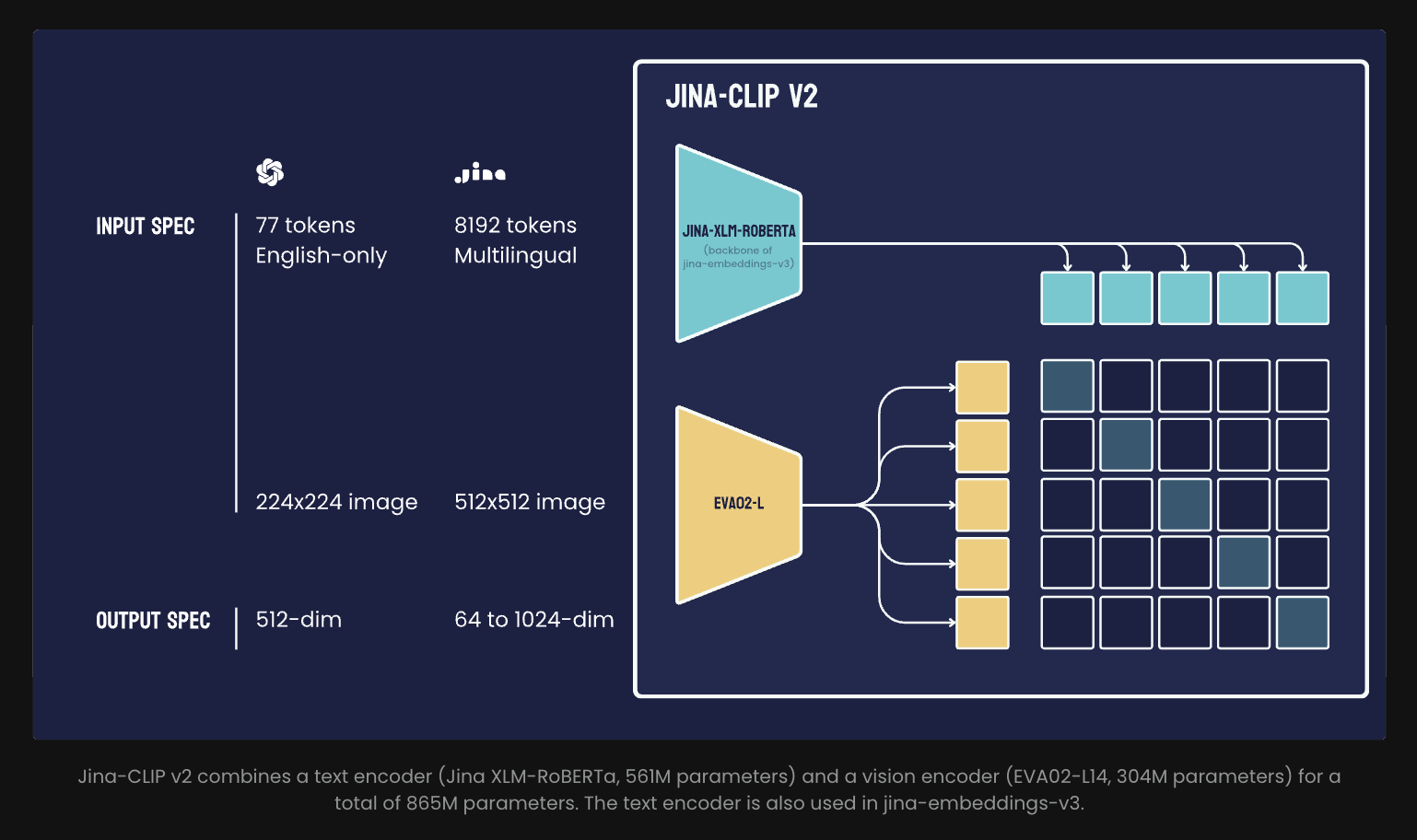
Jina AI представила Jina-CLIP v2 — многозначную модель, которая связывает изображения с текстом на 89 языках. Она поддерживает множество языков и решает проблемы доступа к современным технологиям ИИ.
Модель обрабатывает изображения с разрешением 512×512 и может работать с текстом до 8,000 токенов, что делает ее эффективной для связывания изображений и многоязычного текста. Также она использует представления Матрешки, которые уменьшают размер векторов до 64 измерений для текстов и изображений, улучшая эффективность обработки.
Технические особенности
Jina-CLIP v2 демонстрирует гибкость и эффективность, позволяя генерировать векторы как на больших, так и на малых масштабах. Модель также может работать как отдельный извлекатель текста, сопоставляя производительность с другими моделями для многоязычных векторов.
Эта модель подходит для различных задач, от многоязычных поисковых систем до рекомендательных систем, и помогает пользователям с менее распространенными языками.
Выводы и перспективы
Jina-CLIP v2 — это важный шаг к созданию инклюзивных инструментов искусственного интеллекта, которые преодолевают языковые барьеры. Это решение может значительно повлиять на приложения в области электронной коммерции, рекомендаций контента и визуального поиска.
Если вам нужна помощь в внедрении ИИ, пишите нам. Следите за новостями о ИИ в нашем Telegram-канале.
«`




















