
Michelangelo: Искусственный интеллект для Оценки Долгосрочного Рассуждения в Больших Языковых Моделях за Пределами Простых Задач Поиска
Значимость долгосрочного рассуждения
Важно, чтобы машины могли синтезировать и извлекать актуальные данные из огромных наборов информации, обеспечивая возможность обработки сложных отношений в огромных контекстах. Это необходимо для функций, таких как сжатие документов, генерация кода и анализ крупномасштабных данных, все это является ключевым для развития ИИ.
Проблема измерения понимания долгого контекста
Существующие методы оценки усваивания долгого контекста в больших языковых моделях неэффективны, поскольку фокусируются на изолированных задачах поиска, не способствуя полному оцениванию способности модели усваивать и синтезировать информацию из больших наборов данных.
Новый подход Michelangelo
Фреймворк Michelangelo предлагает новый способ тестирования усваивания долгого контекста в моделях с использованием синтетических данных, обеспечивая проверку на сложные и актуальные задачи. Фокус на понимании долгого контекста через систему Latent Structure Queries позволяет модели раскрывать скрытые структуры внутри большого контекста, отбрасывая ненужную информацию.
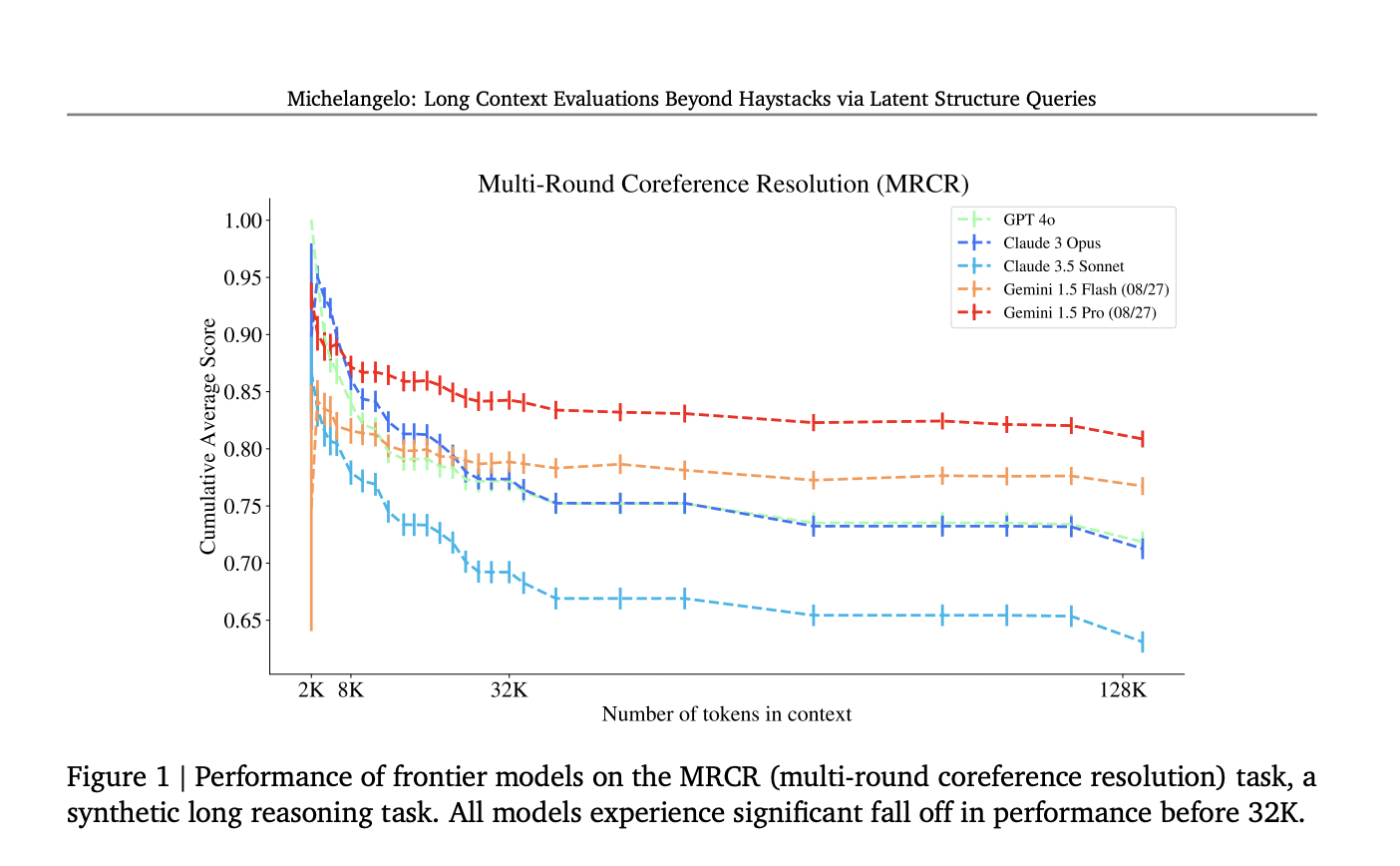
Задачи Michelangelo
Фреймворк включает в себя три основные задачи: Latent List, Multi-Round Coreference Resolution (MRCR) и задачу IDK. Они предоставляют детальные инсайты в способность современных моделей обрабатывать долгосрочное рассуждение.
Преимущества Michelangelo
Michelangelo существенно улучшает оценку способности моделей обрабатывать долгий контекст и выявляет различия в работе таких моделей, как GPT-4, Claude 3 и Gemini. Он демонстрирует потенциал моделей Gemini в работе с обширными данными, превосходя другие модели.




















