
Внедрение ИИ-решений для генерации точных аудио-описаний видео
Внедрение Audio Description (AD) представляет собой большой шаг к увеличению доступности видеоконтента. AD обеспечивает озвученное описание важных визуальных элементов в видео, недоступных в оригинальной звуковой дорожке. Однако создание точного AD требует значительных ресурсов, таких как специальная экспертиза, оборудование и значительные временные затраты. Автоматизация процесса создания AD улучшает доступность видео для людей с ограниченными возможностями зрения, однако большая проблема в этом процессе — генерация предложений правильной длины, которые соответствуют различным временным промежуткам в диалогах актеров.
Роль больших мультимодальных моделей в ИИ
Недавно большие мультимодальные модели (LMMs) стали популярны в области искусственного интеллекта, в основном фокусируясь на интеграции различных типов данных, включая текст, изображения, аудио и видео, чтобы стать более надежными и интеллектуальными. Например, модель GPT-4V — это LLM-модель, расширяющая большую языковую модель GPT-4 с потенциалом видения. Метод MM-VID открыл использование модели GPT-4V для генерации AD с помощью двухэтапного метода. Данный процесс включает синтез компактных подписей кадров и улучшение окончательного AD с использованием GPT-4. Однако эти методы не имеют явного процесса распознавания персонажей.
Использование GPT-4V для генерации AD
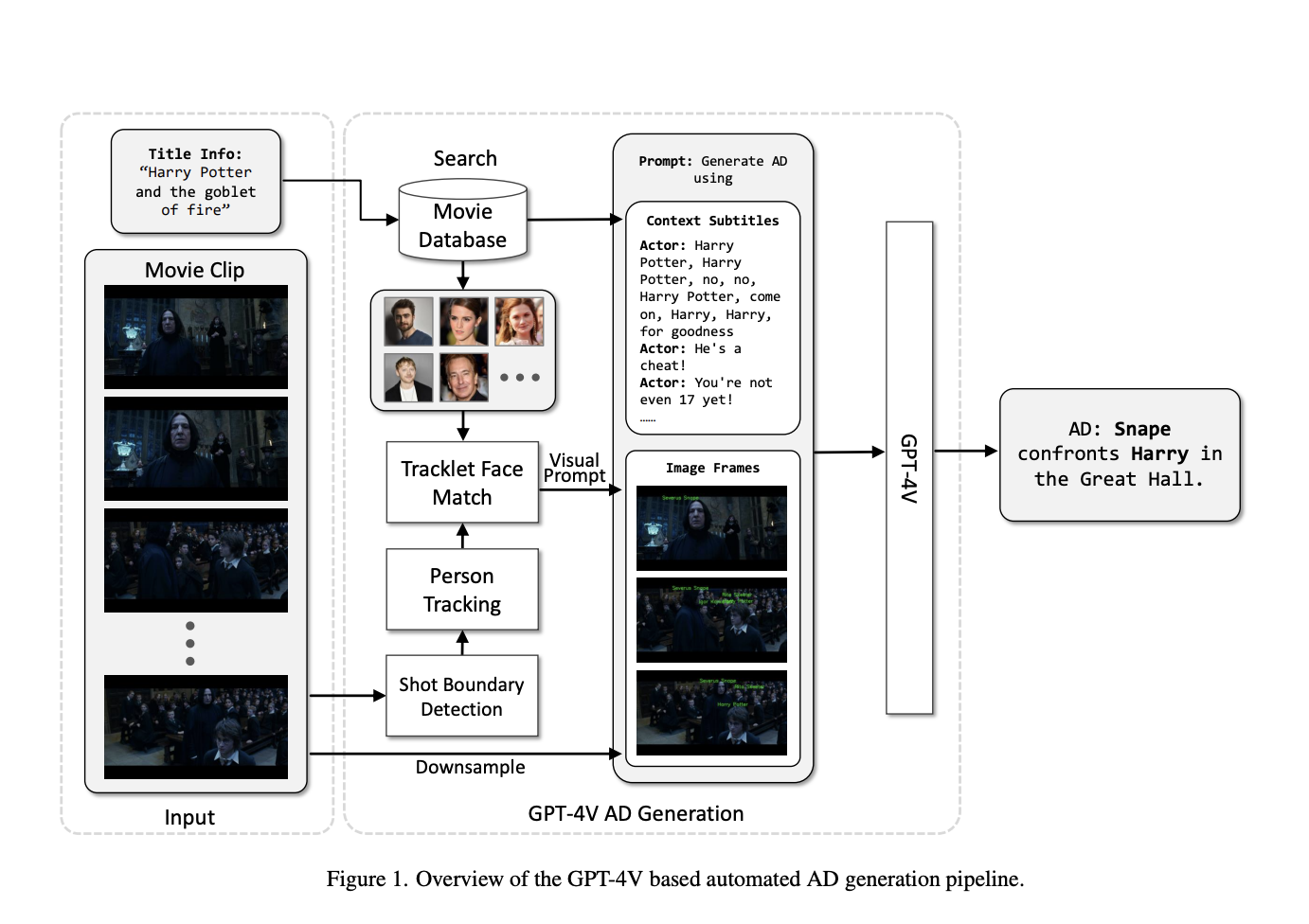
Команда из Microsoft представила автоматизированный процесс, использующий GPT-4V(ision) для генерации точных AD для видео. Этот метод использует видеоролик и информацию о его названии для создания AD и использует мультимодальные возможности GPT-4V для интеграции визуальных сигналов из видеокадров с текстовым контекстом для создания AD. Этот метод помогает подстроить размер AD под промежуток речи и адаптировать его для различных видеороликов, предоставляя входные данные для правил создания AD, показывая, какой длины должно быть предложение простым и естественным способом.
Результаты и перспективы
Предложенный метод был протестирован с использованием набора данных MAD, который включает богатую коллекцию из более чем 264 000 аудио-описаний из 488 фильмов. Также была использована упрощенная версия многопользовательского отслеживателя при разработке этого метода для генерации треклетов персон, захватывающих всех персонажей, появляющихся в исходном видеоролике. Далее используется TransNetV2 для обнаружения и разделения клипов, содержащих несколько съемок, и после создания треклета извлекаются квадратные участки вокруг каждого человека из кадров. Внутри квадратов лиц выполняется обнаружение лиц с использованием модели YOLOv7, облегчая обрезку и выравнивание квадратов лиц до стандартного размера 112 x 112 пикселей.
GPT-4V был настроен на генерацию всех AD в словах, таких как 6, 10 и 20 слов, с результатами производительности. В наборе данных AudioVault 80% AD содержат десять слов или меньше, 99% AD ограничиваются двадцатью словами, а выбор 6 слов соответствует среднему количеству слов в наборе данных. Результаты показывают, что подсказки из 10 слов показывают наивысшие оценки ROUGE-L и CIDEr по сравнению с фиксированными количествами слов 6, 10 и 20. Предложенный метод превосходит AutoAD-II, установив новую ведущую производительность с оценками CIDEr и ROUGE-L в 20,5 (по сравнению с 19,5) и 13,5 (по сравнению с 13,4) соответственно.
Заключение и перспективы
Команда из Microsoft предложила автоматизированный процесс, использующий GPT-4V(ision) для генерации точных аудио-описаний видео. Этот метод превосходит различные методологии в данной статье, такие как AutoAD-II, с оценками CIDEr и ROUGE-L в 20,5 (по сравнению с 19,5) и 13,5 (по сравнению с 13,4) соответственно. Однако предложенный метод не имеет механизма для определения подходящих моментов в фильме для вставки AD и оценки связанного количества слов для этого AD. Таким образом, в будущем необходимо улучшить качество сгенерированных AD, например, можно настроить легкую модель переписывания языка, используя доступные данные AD, чтобы улучшить вывод LLM.
Проверьте Paper. Вся заслуга за этот исследовательский проект принадлежит исследователям. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему Telegram-каналу, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш newsletter.
Не забудьте присоединиться к нашему 41k+ ML SubReddit


















