
«`html
Оптимизация ИИ: Machete от Neural Magic
Быстрый рост больших языковых моделей (LLMs) требует оптимизированных решений для управления памятью и скоростью обработки. Модели, такие как GPT-3 и Llama, требуют значительных ресурсов GPU, и эффективное использование оборудования становится критически важным.
Что такое Machete?
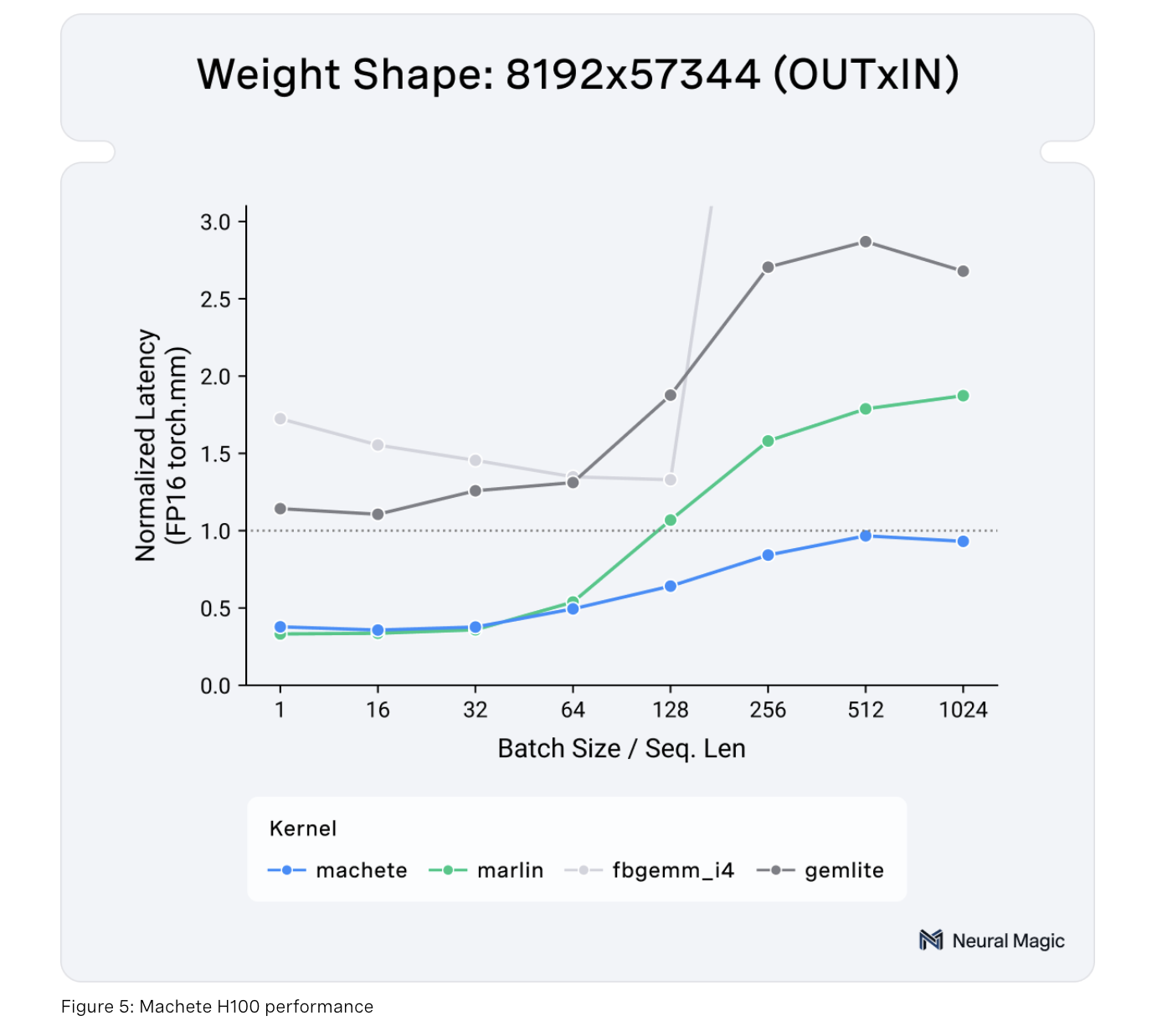
Machete — это новый смешанный GEMM ядро для GPU NVIDIA Hopper, которое значительно улучшает производительность LLM. Оно использует смешанную квантовку w4a16, что позволяет сократить использование памяти примерно в 4 раза, сохраняя при этом высокую производительность.
Преимущества Machete:
- Снижение потребления памяти: Machete уменьшает требования к памяти, что позволяет запускать даже самые большие модели, такие как Llama 3.1 70B и 405B, на доступном оборудовании.
- Увеличение скорости: В тестах Machete показал увеличение пропускной способности на 29% и ускорение генерации токенов на 32% для Llama 3.1 70B.
- Оптимизация работы с памятью: Использование предшествующей перетасовки весов и улучшенные процедуры конвертации делают Machete эффективным решением для повышения производительности LLM.
Почему это важно?
Machete помогает справиться с критическими узкими местами в использовании памяти и пропускной способности. Это делает его незаменимым инструментом для повышения эффективности обработки моделей, снижая затраты на вычисления.
Рекомендации по внедрению ИИ:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выбирайте подходящие решения и внедряйте их постепенно.
- Начинайте с небольших проектов и анализируйте результаты.
Если вам нужны советы по внедрению ИИ, пишите нам в Telegram. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
Попробуйте AI Sales Bot, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab.
«`



















