
«`html
Преобразование выравнивания больших языковых моделей с помощью эффективного обучения с подкреплением
Исследования в области больших языковых моделей (LLMs) акцентируют внимание на выравнивании этих моделей с предпочтениями людей для создания полезных, беспристрастных и безопасных ответов. Ученые сделали значительные шаги в обучении LLMs для улучшения их способности понимать, воспринимать и взаимодействовать с текстом, созданным людьми, улучшая коммуникацию между людьми и машинами.
Основные вызовы в NLP
Основной вызов в NLP заключается в обучении LLMs предоставлять ответы, соответствующие предпочтениям людей, избегая предубеждений и генерируя полезные и безопасные ответы. Настройка с помощью обучения с учителем предлагает основной подход к улучшению поведения модели, но достижение истинного соответствия с предпочтениями людей требует более сложных методов. Комплексные конвейеры, особенно обучение с подкреплением от обратной связи человека (RLHF), часто необходимы для улучшения этих моделей, но их техническая сложность и значительные требования к ресурсам могут затруднить более широкое принятие.
Практические решения
Инструменты, такие как HuggingFace TRL и DeepSpeedChat, предлагают ценные ресурсы для выравнивания модели, но им не хватает масштабируемости и производительности, необходимых для управления современными масштабными моделями. Сложность и размер современных LLMs требуют специализированных оптимизированных решений, которые эффективно обрабатывают их требования к обучению, позволяя исследователям сосредоточиться на настройке поведения модели, не ограничиваясь техническими ограничениями.
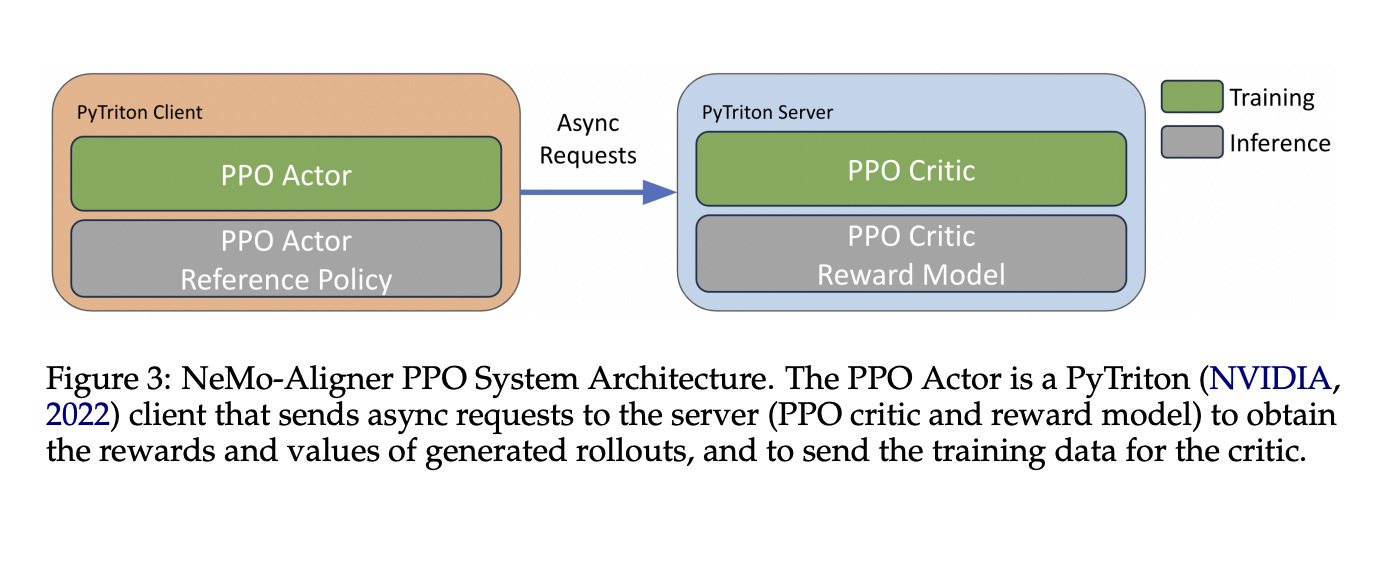
Исследователи в NVIDIA представили NeMo-Aligner, новый инструмент, разработанный для упрощения процесса обучения масштабных LLMs с использованием обучения с подкреплением. Этот инструмент использует фреймворк NeMo от NVIDIA для оптимизации всего конвейера RLHF, от настройки с учителем до обучения модели вознаграждения и оптимизации ближайшей политики (PPO). Фокус команды на оптимизации параллелизма и техник распределенных вычислений привел к созданию инструмента, способного эффективно управлять сложностями, присущими обучению больших моделей. Он позволяет распределять вычислительные нагрузки по разным кластерам, максимально используя доступное оборудование.
Архитектура NeMo-Aligner разработана для упрощения выравнивания модели и повышения эффективности. Инструмент включает различные оптимизации для поддержки нескольких этапов конвейера RLHF. Например, он разделяет конвейер обучения на три фазы:
- Настройка с учителем
- Обучение модели вознаграждения
- PPO
Во время PPO он динамически балансирует рабочие нагрузки между параллельными рабочими, что приводит к значительному улучшению производительности обучения. Используя передовые стратегии распределенных вычислений, NeMo-Aligner эффективно обрабатывает модели большого масштаба, используя сервер PyTriton для общения между моделями во время PPO.
Результаты производительности NeMo-Aligner подчеркивают его значительное улучшение эффективности, особенно во время этапа PPO. Интеграция TensorRT-LLM сокращает время обучения до семи раз по сравнению с традиционными методами, демонстрируя замечательное влияние этой оптимизации. Фреймворк также разработан с учетом расширяемости, позволяя пользователям быстро адаптировать его к новым алгоритмам. Инструмент поддерживает обучение моделей с до 70 миллиардами параметров, позволяя исследователям работать с невиданными масштабами с улучшенной эффективностью и сокращенным временем обучения.
Исследователи продемонстрировали расширяемость NeMo-Aligner, интегрировав его с различными алгоритмами выравнивания, такими как настройка с учителем, прямая оптимизация предпочтений и SPIN. Эта адаптивность позволяет инструменту поддерживать различные стратегии оптимизации, такие как использование моделей предсказания атрибутов для выравнивания моделей с предпочтениями людей по семантическим аспектам, таким как корректность и токсичность. Подход NeMo-Aligner делает возможным улучшение ответов модели целенаправленным, основанным на данных способом.
В заключение, NeMo-Aligner предоставляет надежное и гибкое решение для обучения больших языковых моделей с использованием техник обучения с подкреплением. Решая проблемы масштабируемости и производительности, исследователи создали всеобъемлющий фреймворк, который упрощает процесс выравнивания LLMs с предпочтениями людей. Результатом является инструмент, улучшающий эффективность обучения и обеспечивающий, что модели могут быть настроены для производства полезных и безопасных ответов, соответствующих ожиданиям людей.
Проверьте статью и страницу GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему Telegram-каналу, Discord-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу Reddit.
Источник: MarkTechPost
«`





















