
Мультимодельные большие языковые модели (MLLMs)
Практические решения и ценность
MLLMs сосредотачиваются на создании систем искусственного интеллекта (ИИ), способных без проблем интерпретировать текстовые и визуальные данные. Эти модели направлены на устранение разрыва между пониманием естественного языка и визуальным восприятием, позволяя машинам последовательно обрабатывать различные формы ввода, от текстовых документов до изображений. Понимание и рассуждение по нескольким модальностям становится ключевым, особенно по мере того, как ИИ движется к более сложным применениям в областях, таких как распознавание изображений, обработка естественного языка и компьютерное зрение. Улучшая способы интеграции и обработки разнообразных источников данных, MLLMs готовы революционизировать задачи, такие как подписывание изображений, понимание документов и интерактивные системы ИИ.
Основные проблемы и решения
Одним из значительных вызовов при разработке MLLMs является обеспечение равнозначной производительности в текстовых и визуально-языковых задачах. Часто улучшения в одной области могут привести к снижению в другой. Например, улучшение понимания модели визуальных данных может негативно сказаться на ее языковых возможностях, что проблематично для приложений, требующих обеих, таких как оптическое распознавание символов (OCR) или сложные мультимодальные рассуждения. Ключевая проблема заключается в балансировке обработки визуальных данных, таких как изображения высокого разрешения, и поддержании надежного текстового рассуждения. По мере того, как приложения ИИ становятся более сложными, этот компромисс становится критическим узким местом в развитии мультимодальных моделей ИИ.
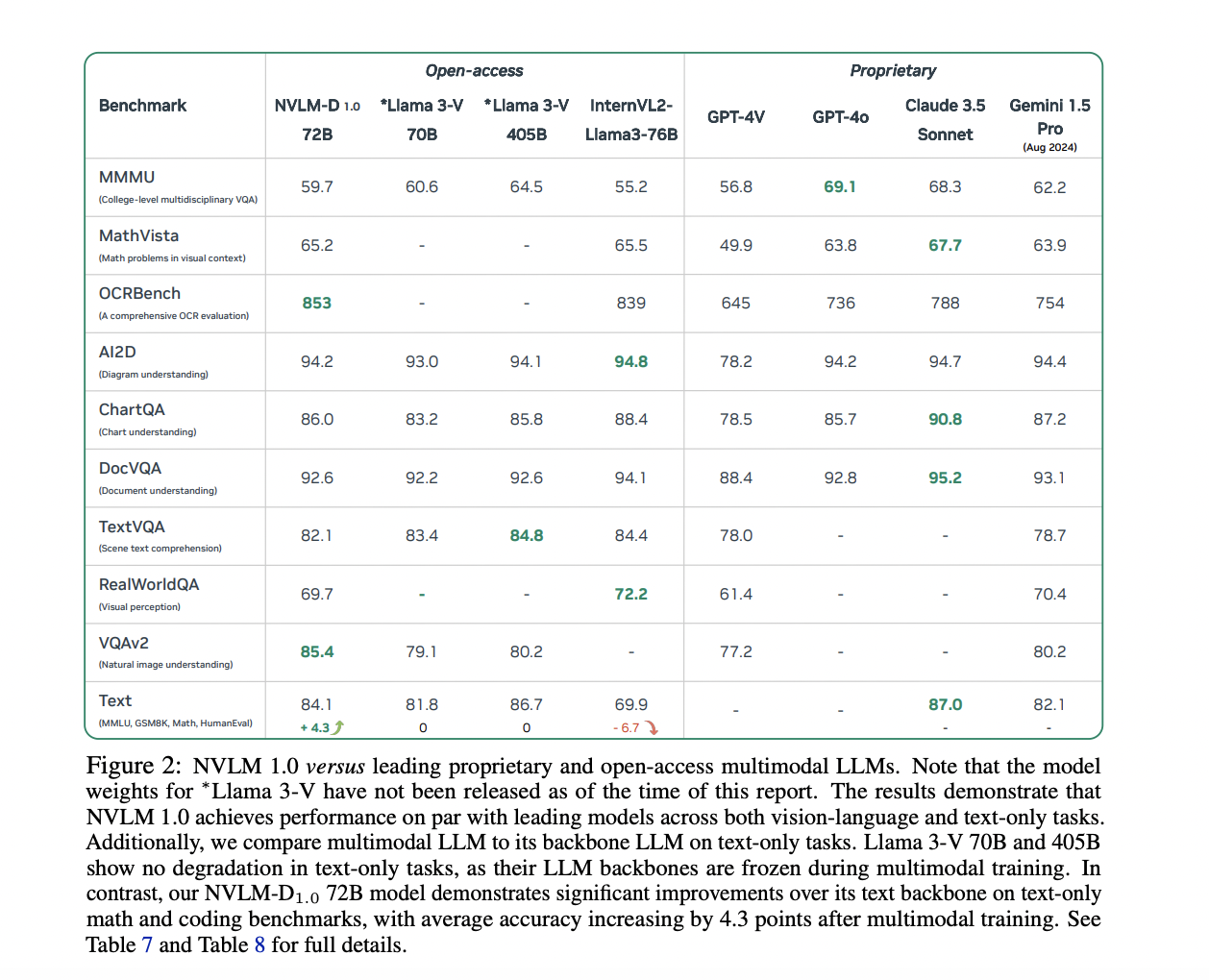
Решения и преимущества NVLM 1.0 моделей
Исследователи из NVIDIA представили модели NVLM 1.0, представляющие собой значительный прорыв в мультимодельном языковом моделировании. Семейство моделей NVLM 1.0 состоит из трех основных архитектур: NVLM-D, NVLM-X и NVLM-H. Каждая из этих моделей решает недостатки предыдущих подходов, интегрируя передовые возможности мультимодального рассуждения с эффективной обработкой текста. Особенностью NVLM 1.0 является включение высококачественных данных для обучения текста в режиме только надзора (SFT), позволяющее этим моделям поддерживать и даже улучшать свою производительность в текстовых задачах, превосходящих визуально-языковые задачи. Модели NVLM 1.0 используют гибридную архитектуру для балансировки обработки текста и изображений, достигая впечатляющих результатов на различных бенчмарках.



















